






Datax 使用RDBMS方式链接hiveserver2并查询数据
Datax 介绍
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
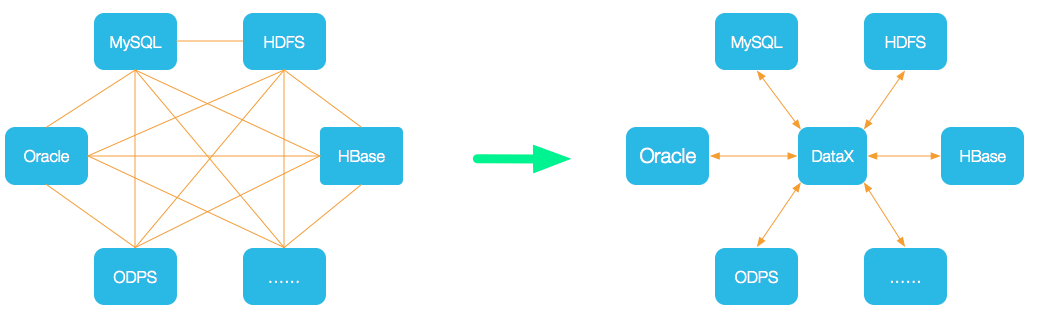
- 设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
- 当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0插件体系

Hive CLI & Hive Server2 比较
Hive CLI 为hive 命令行工具,用户只要在shell提示符中输入hive,就可以在shell环境中找到这个命令
usage: hive
-d,--define <key=value> Variable substitution to apply to Hive commands. e.g. -d A=B or --define A=B
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
-h <hostname> Connecting to Hive Server on remote host
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable substitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-p <port> Connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
Examples
- 从命令行运行查询的示例
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a'
- 设置 Hive 配置变量的示例
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a' --hiveconf hive.exec.scratchdir=/home/my/hive_scratch --hiveconf mapred.reduce.tasks=32
- 使用静默模式将数据从查询中转储到文件中的示例
$HIVE_HOME/bin/hive -S -e 'select a.col from tab1 a' > a.txt
- 从本地磁盘非交互运行脚本的示例
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
- 从 Hadoop 支持的文件系统非交互地运行脚本的示例
$HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql
$HIVE_HOME/bin/hive -f s3://mys3bucket/s3-script.sql
- 进入交互模式之前运行初始化脚本的示例
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
至此hive cli的基本功能已经介绍结束,在hive的官方wiki上发现官方以后将不在支持hive cli 转而支持hiveserver2的beeline client,hiveserver2不仅支持beeline client还支持jdbc方式访问hive,这样大大方便了开发人员操作hive的便利性灵活性
Datax 使用 Hive Server2
Hive Server2 官方介绍为
HiveServer2 has a JDBC driver. It supports both embedded and remote access to HiveServer2. Remote HiveServer2 mode is recommended for production use, as it is more secure and doesn't require direct HDFS/metastore access to be granted for users.
翻译下大概为:HiverServer2体统了jdbc的驱动。同时支持嵌入式和远程访问两种方式。官方强烈建议使用jdbc方式访问因为这种方式更安全而且不用对用户访问hdfs授权
下面是其jdbc的的配置
The HiveServer2 URL is a string with the following syntax:
jdbc:hive2://<host1>:<port1>,<host2>:<port2>/dbName;initFile=<file>;sess_var_list?hive_conf_list#hive_var_list
where
_<host1>_:_<port1>_,_<host2>_:_<port2>_is a server instance or a comma separated list of server instances to connect to (if dynamic service discovery is enabled). If empty, the embedded server will be used.dbNameis the name of the initial database.- is the path of init script file (Hive 2.2.0 and later). This script file is written with SQL statements which will be executed automatically after connection. This option can be empty.
sess_var_listis a semicolon separated list of key=value pairs of session variables (e.g.,user=foo;password=bar).hive_conf_listis a semicolon separated list of key=value pairs of Hive configuration variables for this sessionhive_var_listis a semicolon separated list of key=value pairs of Hive variables for this session.
Special characters in sess_var_list, hive_conf_list, hive_var_list parameter values should be encoded with URL encoding if needed.
Datax json hiveserver2 配置如下,如果需要设置执行引擎例如使用spark则需要在jdbc url 后面追加如下配置
hive2://127.0.0.1:3306/test;hive.execution.engine=spark;
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["name","age"],
"where": "age<100",
"connection": [
{
"table": [
"person"
],
"jdbcUrl": [
"hive2://127.0.0.1:3306/test;"
],
"querySql": [
"select * from test_list where operationDate >= FROM_UNIXTIME(${lastTime}) and operationDate < FROM_UNIXTIME(${currentTime})"
]
}
]
}
}















 3412
3412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









