







文章目录
章节前言
首先对上节课所讲的针对于图的传统机器学习进行回顾。关于此内容,上个学习笔记已经记载很多了(不清楚地可以点链接),在此不再叙述。

为什么要Embedding?
- 节点间嵌入的相似性表明节点之间在网络中的相似性。 例如:两个节点都很接近(由一条边连接)
- 编码网络信息
- 可能用于许多下游预测

Embedding的例子

本章主要内容
本章主要讲了如何使用节点嵌入:聚类、社区发现,节点分类,链接预测(通过concatenate、哈达玛积、取平均、求和、计算距离来得到链接嵌入),图分类(聚合节点嵌入或使用匿名随机游走获得图嵌入)
一、Node Embeddings: Encoder and Decoder
假设我们有一个图G,其中V是顶点集,A是邻接矩阵。
为简单起见:没有使用节点特性或额外信息。

目标是对节点进行编码,使嵌入空间的相似性(例如,点积)近似于图中的相似性。

编码器从节点映射到嵌入:定义一个节点相似函数(即,原始网络中相似度的度量)
Decoder DEC 将embedding对映射为相似度得分
优化编码器参数,使:
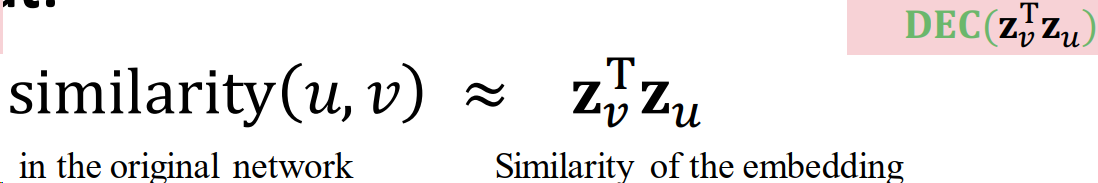
1.1 编码器
将每个节点映射到低维向量,这里的d一般是64-1000维。

最简单的编码方法:Encoder只是一个嵌入式查找。

1.1.1 “浅”编码 “shallow” encoding:

上图中,映射矩阵Z每列是一个节点所对应的embedding向量。v是一个其他元素都为0,对应节点位置的元素为1的向量。通过矩阵乘法的方式得到结果。
这种方式就是将每个节点直接映射为一个embedding向量,我们的学习任务就是直接优化这些embedding。
缺点:参数多,很难scale up3到大型图上。
优点:如果获得了Z,各节点就能很快得到embedding。
有很多种方法:如DeepWalk,node2vec等
1.2.2 Encoder + Decoder Framework Summary
- 浅层编码器:嵌入查找
- 优化参数:𝐙包含节点嵌入 𝐳 𝑢 𝐳_𝑢 zu对于所有节点𝑢∈𝑉
- 我们将在第6讲中介绍深层编码器(gnn)
- 解码器:基于节点相似度
- 目的:对相似的节点对(𝑢,𝑣)最大化 𝐳 𝑣 T 𝐳 𝑢 𝐳_𝑣^Τ𝐳_𝑢 zvTzu
1.3 节点相似的不同定义
- 有边
- 共享邻居
- 有相似的structural roles
本节课将学习:随机游走(random walk)定义的节点相似度以及如何为这样的相似性度量优化嵌入
1.4 Note on Node Embeddings
这是学习节点嵌入的无监督/自我监督方式。
- 我们不使用节点标签
- 我们没有利用节点特性
- 目标是直接估计节点的一组坐标(即嵌入),以便保留网络结构的某些方面(由DEC捕获)。
这些嵌入是独立于任务的,因为它们不是为特定的任务而训练的,但可以用于任何任务。
二、Random Walk Approaches for Node Embeddings
2.1 统一符号表示
向量 z u ⃗ \vec{z_u} zu:节点𝑢的嵌入(我们的目标)
概率函数 P ( v ∣ z u ⃗ ) P(v|\vec{z_u}) P(v∣zu):从节点𝑢开始随机遍历访问节点𝑣的(预测)概率。
下面两个分线性函数被用来生成预测概率:

Softmax函数:将K个实值组成的向量变成一个和为1的由K个概率组成的概率向量。
Sigmoid函数:是一个S形状的函数,能够将实值映射成(0,1)区间的值。
2.2 随机游走:
给定一个图 G G G和一个开始节点 v v v,我们随机挑选这个节点的邻居节点 v u i v_{u_i} vui,然后移到这个邻居节点 v u i v_{u_i} vui,以这个邻居节点作为开始点重复这个过程。到达一定次数之后这个过程结束。在整个过程中访问的节点序列就是图上的随机游走。如下图所示:

2.2.1 random walk embeddings
随机游走嵌入: z u T z v \mathbf{z}_{u}^{\mathrm{T}}\mathbf{z}_v zuTzv表示u和v同时出现在图的随机游走过程的概率。
随机游走Embedding的执行步骤:
- 用随机游动策略R估计从节点u开始的随机游走中访问节点v的概率。

- 优化这些embedding来编码随机游走统计参数。用embedding空间中的相似性(这个相似性需要专门的二元函数来计算,如简单的内积cos(𝜃))来编码节点经过随机游走算法得出来的”相似性“。

2.2.2 random walks优点
-
表达性强。灵活且随机的节点相似性定义能够整合节点局部和全局的邻居信息。
思想:如果从节点u开始的随机游走过程以高概率访问到节点v,那么节点u 和节点u有“很强的关系“,他们是相似的。 -
高效:在训练过程中不需要考虑所有的节点对,仅仅需要考虑在随机游走过程中出现的节点对。
2.3 无监督特征学习
- 目的:在d维空间中,找到能够保存图节点相似性的节点嵌入。
- 思路:在embedding空间中临近的节点在网络中连接的紧密。
- 给定一个节点u,如何定义节点中连接紧密的节点?
N R ( u ) N_R\left( u \right) NR(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









