






目录
感知机
什么是感知机
我们先看一下百科给的解释

感知器是生物神经细胞的简单抽象,神经细胞结构大致可分为:树突、突触、细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’,而未激动时为‘否’。
神经细胞的状态取决于从其它的神经细胞收到的输入信号量,及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会激动,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。为了模拟神经细胞行为,与之对应的感知机基础概念被提出,如权量(突触)、偏置(阈值)及激活函数(细胞体)。
以上就是百科给的解释。
大致意思就是说:感知机是我们对神经网络得一种抽象结构,我们用我们得样本作为神经元,参数也就是权重作为突触,用偏置作为传出信号的一个阈值(达到这个阈值才会传出信号),进行运算,再用激活函数线性运算得到的结果进行计算,从而得到一个值,也就相当于我们人体得神经细胞体接受突出传来得信号刺激后,最后是否会“激动”,从而得到我们想要的结果(也就是产生“电脉冲”)。
单层感知机

从这张图可以看出来,倘若我们假设一个样本有三个特征x=[x1,x2,x2],对应的权重w=[w1,w2,w2],我们假设激活函数为T(x),输出值为y
那么单层感知机得运行原理为:
y=T(wx)
显然,这就相当于把一个线性回归(或者说线性运算)得到的值放到了激活函数里面,然后求得我们的最终值。
看到这里你们是否有疑惑,什么是激活函数呢?
多层感知机
首先看图
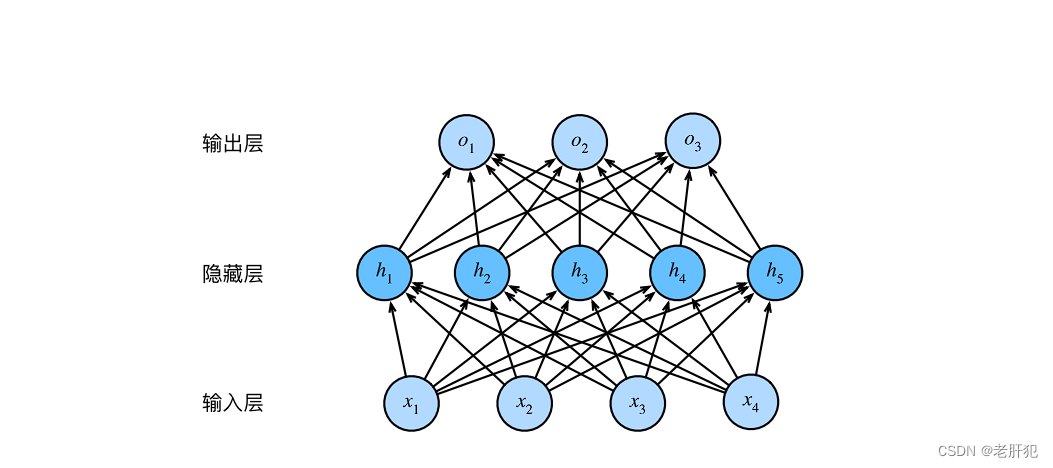
我们前面讲单层感知机的时候提到过,我们的输入层其实就是我们样本的各个特征。
多层感知机和单层感知机的主要区别在于:多层感知机引入了隐藏层。
我们看一下百科对其的定义:

多层感知机就是一种人工神经网络模型,和单层感知机一样,都体现了生物神经网络的特点。
而加入了隐藏层之后就让它和单层感知机在性能上有了很大的区别:
在单层感知机中,输入直接传递给输出层,这意味着它只能学习简单的模式。而 多层感知机 通过引入一个或多个隐藏层,使得网络能够捕捉更复杂的数据特征。每增加一个隐藏层,网络的能力就会显著增强,使其能够学习和表示更加复杂的函数。
多层感知机每一个隐藏层都和输出层一样都带有激活函数,只有输入层没有。
这就类似与人体内的神经网络,当我们看向某些事物的时候,比如看见一个苹果,我们可以在一瞬间知道它的形状,大小,颜色,色泽,等等特征,从而直接判断出”这是一个苹果“,这就相当于单层感知机。
而我们若是等到各种特征信息后,再在脑海中想一想(相当于加入隐藏层),然后再在脑子里进行处理,判断出它的种类,从而得到”这是某某种类的苹果“,这其实就是多层感知机
多层感知机又叫层全连接神经网络。
在我们写代码的过程中,输入层就是我们样本的各个特征值,没一条带箭头的直线都表示一个参数,可以看到对于每个特征都有一组参数与其对应,我们的隐藏层也是带有激活函数,所以整个多层感知机的运行顺序为:
输入数据集数据x->x*w0->激活函数(x*w0)(到隐藏层神经元)->w1*激活函数(x*w0)->输出预测值y
数据集内的数据x应当是一个矩阵数据,w0也应当为一个矩阵,其一行或一列为某一特征的所有参数,一般而言w0的行数取决于隐藏层的深度。,而数据集往往取其转置
这一个正向的运行顺序也被称之为前向传播
前向传播和反向传播
前向传播和反向传播是神经网络的核心机制,它们共同构成了神经网络的学习过程。
前向传播负责将输入数据传递到输出层得到预测结果;
而反向传播则负责根据预测结果与真实值之间的差异来调整权重和偏差,以逐渐提高模型的准确性和性能。
激活函数
什么是激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活,它们将输入信号 转换为输出的可微运算。
激活函数决定了一个神经元是否应该通过加权求和并添加偏差而被激活。激活函数的目的是为神经元添加非线形的输入。一个没有激活函数的神经网络就只是一个线性回归模型,非线形的激活函数能够增加非线性的变换到输入中,使得它能够学习和表现更复杂的任务。
从生物来讲,激活函数就是用来计算上一个神经元传来得刺激足不足以让这个神经元产生“电脉冲”,他最终会得到一个值,我们用这个值来确定是否会产生“电脉冲”,或者说产生什么样得“电脉冲”,在分类问题中,就是用这个值和目标值或者说标签,进行损失函数处理,从而训练。
激活函数的作用
得到一个值。
并且会在计算过程中引入非线性元素,我们知道我们的数据基本上都是非线性的,引入非线性元素有助于我们解决实际问题。
常用的激活函数
ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU),因为它实现简单,同时在各种预测任务 中表现良好。ReLU提供了一种非常简单的非线性变换。给定元素x,ReLU函数被定义为该元素与0的最大值:
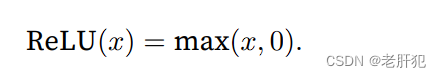

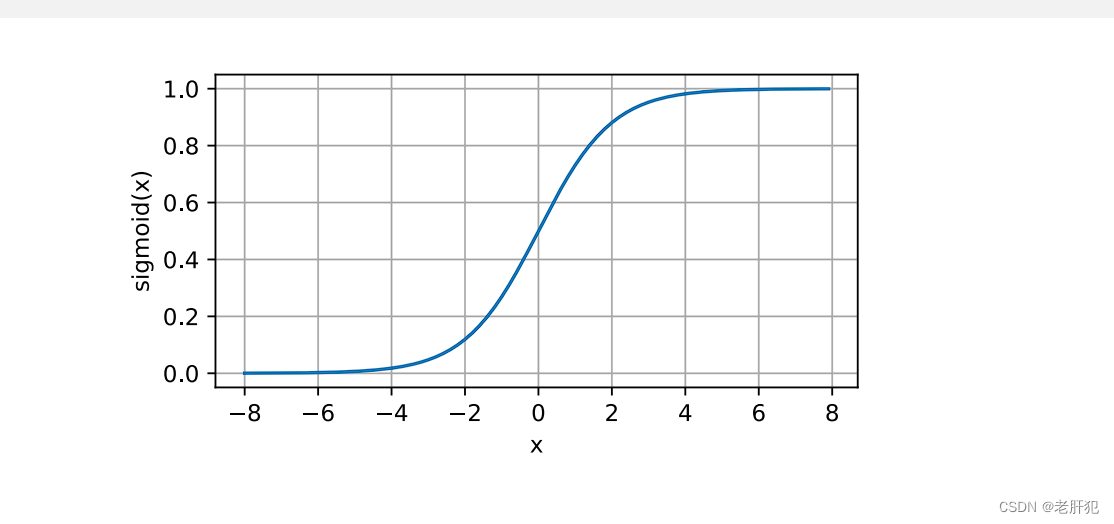
sigmoid函数
对于一个定义域在R中的输入,sigmoid函数将输入变换为区间(0, 1)上的输出。因此,sigmoid通常称为挤压 函数(squashing function):它将范围(‐inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:

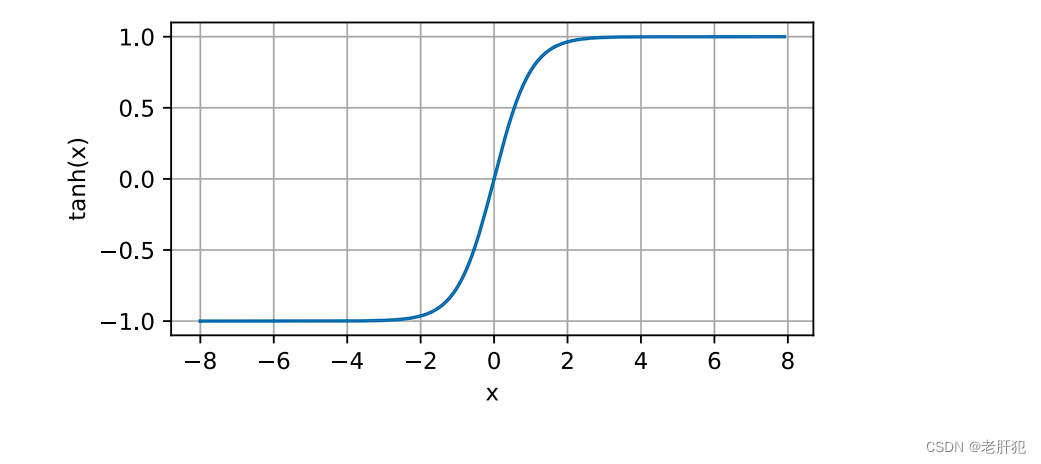
tanh函数
与sigmoid函数类似,tanh(双曲正切)函数也能将其输入压缩转换到区间(‐1, 1)上。tanh函数的公式如下:
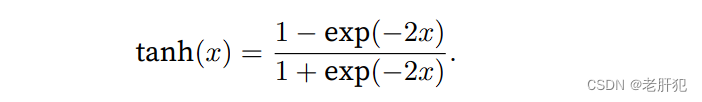
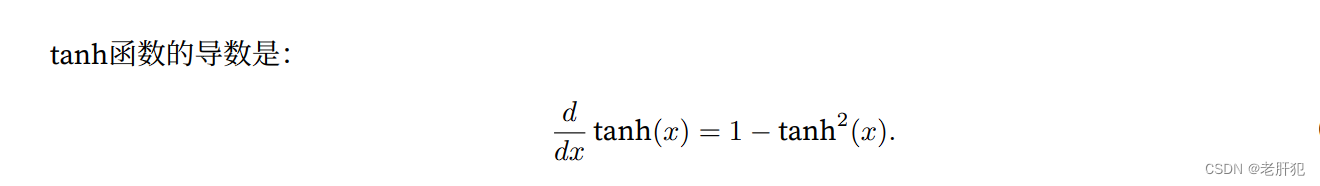
softmax函数
Softmax函数是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为K的任意实向量,Softmax函数可以将其压缩为长度为K,值在[ 0 , 1 ] 范围内,并且向量中元素的总和为1的实向量。
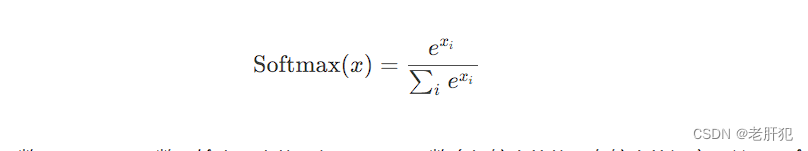
以上就是常见的激活函数。
调用代码
import torch
import numpy as np
from matplotlib import pyplot as plt, font_manager
print('-------------激活函数------')
a=torch.tensor([[10.,-1.],[-6.,5.]])
sigmoid=torch.nn.Sigmoid()
softmax=torch.nn.Softmax(dim=1)
reLU=torch.nn.ReLU()
tanh=torch.nn.Tanh()
print(sigmoid(a))
print(softmax(a))
print(reLU(a[0]))
print(tanh(a))调用结果示例
D:\Anaconda3\envs\pytorch\python.exe D:\learn_pytorch\学习过程\第二周的代码\代码三.py
-------------激活函数------
tensor([[1.0000, 0.2689],
[0.0025, 0.9933]])
tensor([[9.9998e-01, 1.6701e-05],
[1.6701e-05, 9.9998e-01]])
tensor([10., 0.])
tensor([[ 1.0000, -0.7616],
[-1.0000, 0.9999]])
进程已结束,退出代码0
梯度消失
既然说到激活函数,那就免不了要聊一聊梯度消失,梯度消失往往出现在我们调用sigmoid()激活函数来搭建神经网络后,更新梯度出现的结果。
梯度消失是一种现象,通俗而言就是我们进行反向传播时,我们的参数更新着更新着慢慢的不更新了,我们用来更新迭代参数的梯度近似为了0,而我们的模型明显的没有达到我们的预期,这个现象我们称之为梯度消失。
对于sigmoid()函数而言
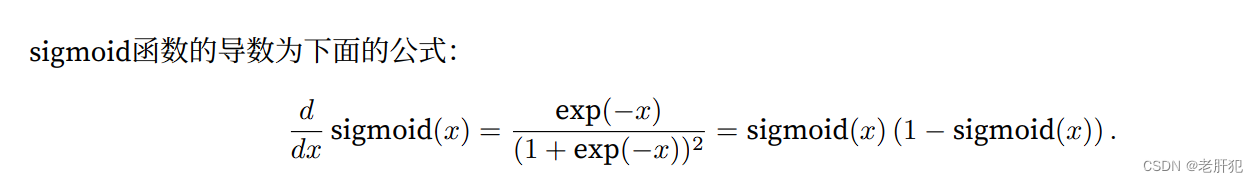
我们知道,它会映射一个在[0,1]范围的值,倘若我们又多个隐藏层,根据链式法则。我们的梯度计算就相当于许多个0.几相乘然后在乘以其他的数,这会导致我们求的导数也就是梯度越来越小,从而出现梯度消失的问题。
(不懂什么是梯度的可以看这篇博客深度学习之梯度,梯度下降法以及使用梯度下降法实现线性回归代码实例(完整代码))
链式法则

 什么意思呢就是这样的:
什么意思呢就是这样的:
所以我们使用sigmoid()很容易就会出现梯度消失。
BP神经网络
BP算法和其对应的神经网络
在了解之前我们提一下上面提到过的,正向传播(前向传播),反向传播:
前向传播负责将输入数据传递到输出层得到预测结果;
而反向传播则负责根据预测结果与真实值之间的差异来调整权重和偏差,以逐渐提高模型的准确性和性能。
BP算法就是目前使用较为广泛的一种参数学习算法.
BP算法的基本思想
它的基本思想:学习过程由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。
BP算法的一般过程
首先正向传播FP(求损失).在这个过程中,我们根据输入的样本,给定的初始化权重值W和偏置项的值b, 计算最终输出值以及输出值与实际值之间的损失值.如果损失值不在给定的范围内则进行反向传播的过程; 否则停止W,b的更新.
然后反向传播BP(回传误差).将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
BP神经网络
BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络
BP神经网络的工作流程
先前向传播,它涉及到将输入数据通过网络向前传递,直到得到输出结果。在传递过程中,每个神经元将它的输入加权求和,然后通过一个激活函数,如sigmoid、ReLU等,生成输出,并将其传递给下一层的神经元。这个过程一直持续到我们得到最终的输出。
(在前向传播过程中,每个神经元的操作都是基于其局部接收到的信息,而不需要关注其他神经元或整个网络的状态。)
反向传播是在前向传播之后进行的,它的目标是通过比较网络的输出和实际的目标值,来调整网络的权重和偏置。
在反向传播过程中,首先会计算输出层的表现误差,然后将这个误差反向传播回网络,对每一层的权重和偏置进行相应的调整。反向传播的过程中,我们需要关注的是整个网络的误差表现,而不仅仅是单个神经元的表现。
BP神经网络的代码实现
示例神经网络图:

后面的代码实现都是基于此图。
底层思路代码实现
导库,创建数据
import torch
import numpy as np
from matplotlib import pyplot as plt, font_manager
print('---------------------BP神经网络--------------')
x0=np.array([[0,0,1],[0,1,1],[1,0,1],[1,1,1]]).T
#print(x0)
#print(x0.shape)#(3, 4)
y=np.array([[0,1,1,0]])
#定义参数
w0=np.random.random((4,3))#4*3个随机数
w1=np.random.random((1,4))模型的的定义:前向传播,反向传播
#模型:f(w1*f(w0*x0))
Ir=0.01
bath=10
epoch=300000
a=0
def sig(x):
return 1/(1+np.exp(-x))
def lin(w,x):
return np.matmul(w,x)
w0_grad=0
lisw0g=[]
lisw1g=[]
lista=[]
w1_grad=0
for n1 in range(bath):
for n2 in range(epoch):
a=a+1
#正向传播
#第一层网络
z0=lin(w0,x0)#4*4
x1=sig(z0)
#第二层网络
z1=lin(w1,x1)#1*4
pre_y=sig(z1)
#反向传播
#利用链式法则
pre_y_grad=-(y-pre_y) #损失函数对预测值的偏导
z1_grad=pre_y_grad*(pre_y*(1-pre_y))#损失函数对z1的偏导
w1_grad=np.matmul(z1_grad,x1.T)#损失函数对w1的偏导
x1_grad=np.matmul(w1.T,z1_grad) #损失函数对x1的偏导
z0_grad=x1_grad*(x1*(1-x1)) #损失函数对z0的偏导
w0_grad=np.matmul(z0_grad,x0.T)#损失函数对w0的偏导
x0_grad=np.matmul(w0.T,z0_grad)# 损失函数对x0的偏导
#权值的更新
w1=w1-Ir*w1_grad
w0=w0-Ir*w0_grad
print('循环次数:{2},w1_grad:{0},w0_grad:{1}'.format(w1_grad,w0_grad,a))这里面前向传播就是我所说的:输入数据集数据x->x*w0->激活函数(x*w0)(到隐藏层神经元)->w1*激活函数(x*w0)->输出预测值y
反向传播则是通过逐步的求导,利用链式法则,来得到我们对参数的梯度,从而对参数进行更新,我们这里为了方便体现底层思路,并没有设置偏置。
完整代码
import torch
import numpy as np
from matplotlib import pyplot as plt, font_manager
print('---------------------BP神经网络--------------')
x0=np.array([[0,0,1],[0,1,1],[1,0,1],[1,1,1]]).T
#print(x0)
#print(x0.shape)#(3, 4)
y=np.array([[0,1,1,0]])
#定义参数
w0=np.random.random((4,3))#4*3个随机数
w1=np.random.random((1,4))
#模型:f(w1*f(w0*x0))
Ir=0.01
bath=10
epoch=300000
a=0
def sig(x):
return 1/(1+np.exp(-x))
def lin(w,x):
return np.matmul(w,x)
w0_grad=0
lisw0g=[]
lisw1g=[]
lista=[]
w1_grad=0
for n1 in range(bath):
for n2 in range(epoch):
a=a+1
#正向传播
#第一层网络
z0=lin(w0,x0)#4*4
x1=sig(z0)
#第二层网络
z1=lin(w1,x1)#1*4
pre_y=sig(z1)
#反向传播
#利用链式法则
pre_y_grad=-(y-pre_y) #损失函数对预测值的偏导
z1_grad=pre_y_grad*(pre_y*(1-pre_y))#损失函数对z1的偏导
w1_grad=np.matmul(z1_grad,x1.T)#损失函数对w1的偏导
x1_grad=np.matmul(w1.T,z1_grad) #损失函数对x1的偏导
z0_grad=x1_grad*(x1*(1-x1)) #损失函数对z0的偏导
w0_grad=np.matmul(z0_grad,x0.T)#损失函数对w0的偏导
x0_grad=np.matmul(w0.T,z0_grad)# 损失函数对x0的偏导
#权值的更新
w1=w1-Ir*w1_grad
w0=w0-Ir*w0_grad
print('循环次数:{2},w1_grad:{0},w0_grad:{1}'.format(w1_grad,w0_grad,a))
lisw0g.append(w0_grad.mean())
lisw1g.append(w1_grad.mean())
lista.append(a)
print('w0:',w0)
print('w1:',w1)
z0=lin(w0,x0)
x1=sig(z0)
z1=lin(w1,x1)
x2=sig(z1)
print('真实值',y)
print('预测值:',x2)
font = font_manager.FontProperties(fname="C:\\Users\\ASUS\\Desktop\\Fonts\\STZHONGS.TTF")
plt.plot(lista,lisw1g,"r",label='w1_grad')
plt.plot(lista,lisw0g,"b",label='w0_grad')
plt.title('梯度和训练次数的关系',fontproperties=font, fontsize=18)
plt.legend(prop=font)
plt.show()
运行结果
D:\Anaconda3\envs\pytorch\python.exe D:\learn_pytorch\学习过程\第二周的代码\代码五.py
---------------------BP神经网络--------------
循环次数:300000,w1_grad:[[ 3.50836092e-04 7.38760267e-05 7.12490778e-05 -3.32039528e-04]],w0_grad:[[-1.41646446e-04 -1.47074213e-04 2.18537619e-04]
[-1.34961594e-04 1.70115284e-04 -1.08514693e-04]
[ 1.12591598e-04 -1.11313376e-04 -6.73398923e-05]
[-9.46318852e-05 -9.00097004e-05 3.50811555e-05]]
循环次数:600000,w1_grad:[[ 1.47400528e-04 3.28459324e-05 3.14354629e-05 -1.37618206e-04]],w0_grad:[[-5.53977504e-05 -5.85255580e-05 8.60022439e-05]
[-6.41841275e-05 7.67069041e-05 -4.13144294e-05]
[ 5.66015008e-05 -5.60472417e-05 -3.48432741e-05]
[-3.67801802e-05 -3.45753305e-05 1.30718599e-05]]
循环次数:900000,w1_grad:[[ 9.11764391e-05 2.10867481e-05 2.06290761e-05 -8.46479151e-05]],w0_grad:[[-3.30629473e-05 -3.52263707e-05 5.15098235e-05]
[-4.11346720e-05 4.80764525e-05 -2.40245030e-05]
[ 3.80537787e-05 -3.72266484e-05 -2.31614268e-05]
[-2.19342395e-05 -2.04850413e-05 7.60319038e-06]]
循环次数:1200000,w1_grad:[[ 6.54216175e-05 1.55084464e-05 1.55166204e-05 -6.05500096e-05]],w0_grad:[[-2.31912129e-05 -2.48080666e-05 3.61993165e-05]
[-2.99732546e-05 3.45449218e-05 -1.65080378e-05]
[ 2.86666142e-05 -2.77508623e-05 -1.71948160e-05]
[-1.53735365e-05 -1.43021829e-05 5.23281475e-06]]
循环次数:1500000,w1_grad:[[ 5.07864995e-05 1.22556285e-05 1.25034262e-05 -4.69168514e-05]],w0_grad:[[-1.77158593e-05 -1.89831508e-05 2.76809022e-05]
[-2.34517970e-05 2.67584410e-05 -1.24000698e-05]
[ 2.29785415e-05 -2.20590577e-05 -1.36000643e-05]
[-1.17316008e-05 -1.08878057e-05 3.93660780e-06]]
循环次数:1800000,w1_grad:[[ 4.13953758e-05 1.01267407e-05 1.05036415e-05 -3.81961354e-05]],w0_grad:[[-1.42649582e-05 -1.52916079e-05 2.22999405e-05]
[-1.91977538e-05 2.17352076e-05 -9.84370623e-06]
[ 1.91597251e-05 -1.82698783e-05 -1.12091029e-05]
[-9.43455981e-06 -8.74266054e-06 3.12906380e-06]]
循环次数:2100000,w1_grad:[[ 3.48778737e-05 8.62592993e-06 9.07371013e-06 -3.21581311e-05]],w0_grad:[[-1.19034381e-05 -1.27556866e-05 1.86115092e-05]
[-1.62138925e-05 1.82421238e-05 -8.11367523e-06]
[ 1.64184538e-05 -1.55702560e-05 -9.50971885e-06]
[-7.86192820e-06 -7.27838592e-06 2.58190392e-06]]
循环次数:2400000,w1_grad:[[ 3.00997103e-05 7.51141234e-06 7.99747099e-06 -2.77395425e-05]],w0_grad:[[-1.01917800e-05 -1.09126889e-05 1.59347664e-05]
[-1.40103803e-05 1.56806185e-05 -6.87204264e-06]
[ 1.43553104e-05 -1.35517786e-05 -8.24285232e-06]
[-6.72183031e-06 -6.21929777e-06 2.18877095e-06]]
循环次数:2700000,w1_grad:[[ 2.64517649e-05 6.65128844e-06 7.15651826e-06 -2.43709536e-05]],w0_grad:[[-8.89736177e-06 -9.51636206e-06 1.39086216e-05]
[-1.23193670e-05 1.37264093e-05 -5.94137713e-06]
[ 1.27466980e-05 -1.19870173e-05 -7.26380555e-06]
[-5.85964458e-06 -5.41983719e-06 1.89379599e-06]]
循环次数:3000000,w1_grad:[[ 2.35784327e-05 5.96751811e-06 6.48034691e-06 -2.17207031e-05]],w0_grad:[[-7.88601849e-06 -8.42403009e-06 1.23244531e-05]
[-1.09823967e-05 1.21891156e-05 -5.22008973e-06]
[ 1.14576075e-05 -1.07393877e-05 -6.48559545e-06]
[-5.18611448e-06 -4.79621764e-06 1.66497024e-06]]
w0: [[ 4.51043042 4.72655183 -7.04826393]
[ 2.89853025 -1.72953664 1.00128818]
[-1.07515748 2.73570187 0.19648933]
[ 7.23068438 7.09755745 -3.00385718]]
w1: [[-10.23119076 -4.83259132 -4.37497106 12.14108798]]
真实值 [[0 1 1 0]]
预测值: [[0.00462783 0.99503721 0.99449421 0.00559154]]
进程已结束,退出代码0

使用纯python封装成类的BP代码实现
由于前面底层已经实现我们这里直接看原代码和运行结果就好
完整代码
import torch
import numpy as np
from matplotlib import pyplot as plt, font_manager
print('---------------------使用纯python封装成类的BP--------------')
class BPNetwork:
def __init__(self,input_size,hidden_size,output_size):# 一个样本的特征数,隐藏层深度,该样本的结果的个数
self.input_size=input_size
self.hidden_size=hidden_size
self.output_size=output_size
#初始化权重和偏置
self.w0=np.random.random((self.hidden_size,self.input_size))
self.w1=np.random.random((self.output_size,self.hidden_size))
def forward(self,x0):
#前向传播
#从输入层到隐藏层
self.z0=np.matmul(self.w0,x0)
self.x1=1/(1+np.exp(-self.z0))
#从隐藏层到输出层
self.z1=np.matmul(self.w1,self.x1)
self.pre_y= 1/(1+np.exp(-self.z1))
return self.pre_y
def backward(self,x0,y,Ir):
#反向传播
# 利用链式法则
pre_y_grad = -(y - self.pre_y) # 损失函数对预测值的偏导
z1_grad = pre_y_grad * (self.pre_y * (1 - self.pre_y)) # 损失函数对z1的偏导
w1_grad = np.matmul(z1_grad, self.x1.T) # 损失函数对w1的偏导
x1_grad = np.matmul(self.w1.T, z1_grad) # 损失函数对x1的偏导
z0_grad = x1_grad * (self.x1 * (1 - self.x1)) # 损失函数对z0的偏导
w0_grad = np.matmul(z0_grad, x0.T) # 损失函数对w0的偏导
x0_grad = np.matmul(self.w0.T, z0_grad) # 损失函数对x0的偏导
# 权值的更新
self.w1 = self.w1 - Ir * w1_grad
self.w0 = self.w0 - Ir * w0_grad
#定义数据集
x0=np.array([[0,0,1],[0,1,1],[1,0,1],[1,1,1]]).T
#print(x0)
#print(x0.shape)#(3, 4)
y=np.array([[0,1,1,0]])
#模型:f(w1*f(w0*x0))
Ir=0.01
bath=10
epoch=30000
a=0
#模型对象的建立
bp=BPNetwork(3,4,1)
for i1 in range(bath):
for i2 in range(epoch):
a=a+1
bp.forward(x0)
bp.backward(x0,y,Ir)
#预测结果
pre_y=bp.forward(x0)
print(pre_y)
运行结果
D:\Anaconda3\envs\pytorch\python.exe D:\learn_pytorch\学习过程\第二周的代码\代码六.py
---------------------使用纯python封装成类的BP--------------
[[0.01011527 0.965961 0.96552328 0.04075291]]
进程已结束,退出代码0
这个大家只需要看一下如何实现就好。
使用pytorch封装BP类模型直接实现
因为注释已经很清楚了,所以我们看注释就好
完整代码
import torch
import numpy as np
from matplotlib import pyplot as plt, font_manager
print('---------------------使用pytorch封装BP类--------------')
class BPNetwork(torch.nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super(BPNetwork,self).__init__()
#模型的定义,设定参数得到我们要获取的模型模板
self.hidden1=torch.nn.Linear(input_size,hidden_size)#隐藏层模型
self.out=torch.nn.Linear(hidden_size,output_size)#线性模型
self.sig=torch.nn.Sigmoid()#sigmoi函数模型
def forward(self,x):
x=x.to(torch.float32)#x里面的数变成浮点数
x=self.hidden1(x)
x=self.sig(x)
x=self.out(x)
out=self.sig(x)
return out
#定义数据集:
x0=torch.tensor([[0,0,1],[0,1,1],[1,0,1],[1,1,1]],dtype=torch.float32)
y=torch.tensor([[0,1,1,0]],dtype=torch.float32).T
#模型的定义
model=BPNetwork(3,4,1)
#损失函数
criterion=torch.nn.MSELoss()
#学习率
Ir=0.01
#梯度下降法优化
optimizer=torch.optim.SGD(model.parameters(),Ir)
#开始训练
a=0
lista=[]
bath=10
epoch=10000
loss=0
listloss=[]
for i1 in range(bath):
for i2 in range(epoch):
a=a+1
pre_y=model(x0)
loss=criterion(pre_y,y)#然后再计算损失函数
optimizer.zero_grad()#,一开始没有梯度,如果有梯度。把梯度清零,防止影响下一步
loss.backward()#里面包含了梯度下降
optimizer.step()
lista.append(a)
listloss.append(loss.item())
print('训练次数:{0},loss:{1}'.format(a,loss))
print('listloss:',listloss)
print('lista:',lista)
#输出模型权重
print('w0:',model.hidden1.weight.data)
print('b0:',model.hidden1.bias.data)
print('w1:',model.out.weight.data)
print('b1:',model.out.bias.data)
#预测
y_test=model(x0)
print(' 真实值:',y)
print('测试值:',y_test)
font = font_manager.FontProperties(fname="C:\\Users\\ASUS\\Desktop\\Fonts\\STZHONGS.TTF")
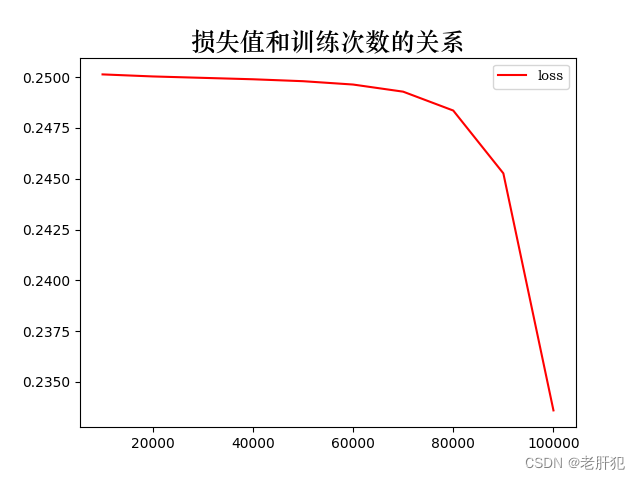
plt.plot(lista,listloss,"r",label='loss')
plt.title('损失值和训练次数的关系',fontproperties=font, fontsize=18)
plt.legend(prop=font)
plt.show()运行结果
D:\Anaconda3\envs\pytorch\python.exe D:\learn_pytorch\学习过程\第二周的代码\代码七.py
---------------------使用pytorch封装BP类--------------
训练次数:10000,loss:0.25013861060142517
训练次数:20000,loss:0.2500382363796234
训练次数:30000,loss:0.24996845424175262
训练次数:40000,loss:0.24989889562129974
训练次数:50000,loss:0.24980413913726807
训练次数:60000,loss:0.24963954091072083
训练次数:70000,loss:0.249288409948349
训练次数:80000,loss:0.24835924804210663
训练次数:90000,loss:0.24526642262935638
训练次数:100000,loss:0.23359310626983643
listloss: [0.25013861060142517, 0.2500382363796234, 0.24996845424175262, 0.24989889562129974, 0.24980413913726807, 0.24963954091072083, 0.249288409948349, 0.24835924804210663, 0.24526642262935638, 0.23359310626983643]
lista: [10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000]
w0: tensor([[ 0.3757, -0.2921, 0.5110],
[ 1.4889, -1.6685, -0.9312],
[-0.1518, -0.0435, -0.5344],
[-0.3823, 0.3513, -0.5912]])
b0: tensor([-0.2293, -0.5776, 0.5447, 0.2155])
w1: tensor([[-0.7097, 1.5051, 0.2236, 0.3266]])
b1: tensor([-0.1634])
真实值: tensor([[0.],
[1.],
[1.],
[0.]])
测试值: tensor([[0.4875],
[0.4539],
[0.5799],
[0.4712]], grad_fn=<SigmoidBackward0>)
进程已结束,退出代码0
以上就是所有内容了。














 2268
2268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









