






lab5提供了那么多优化方法,依旧没能使我的SocialNetworkCircle读出大文件。那么回归本质,一定是算法层面出了大问题!
这个部分的优化是最耗费我心血的,因为几乎大修了算法逻辑,以及辅助的数据结构,才降低了时间复杂度。最后的总运行时间(读取文件+构造系统)已经压缩至六分钟不到。
在lab3中,读取中等级别的文件仍需一分钟以上,至于lab5提供的大文件几个小时仍未读取成功,便暂时搁置了。而现在几乎瞬间绘制出中、高级别的社交网络结构。如下图,最高规模的轨道系统也可以在几分钟内构造成功,不得不说,这几天的辛苦没有白白浪费!(笑
(中等规模的文件读出如左图,更高规模的JUNG图形库承受不住,糊成一团,在此不予展示)

经过这次几乎长达三天的代码调优,我大概明白了。提高效率最主要的还是要靠降低算法的复杂度。最好是降低循环的层数。
首先展示一下,未调优前的代码:

这令人窒息的循环,只是其中一个代表。
第一步调整:不再每次调用函数getDistance,每次仅仅查询一个人的到中心点的距离。而是一次BFS遍历所有得到所有人到中心点的距离。然后根据距离将‘人’依次放到他所在的轨道。算法的复杂度一下子降低了log n级别。
然而向上图的三层循环,仍未得到改善,下面进行第二步:
利用映射——Map<String, PhysicalObject>,记录所有与名字‘String’对应的‘PhysicalObject’对象。而不像原先一样使用二重循环慢慢查找。这个改动至少降低了n2的复杂度。上图的巨型循环已经改正为——

几乎可以见到成功的曙光了,这时我发现,可以在BFS遍历图中将放置‘人’在轨道上以及添加relation两种操作一次性做好,经过第三步的修正,算法的复杂度以及由至少O(n3)降低到了O(n*log n),这对于100000级别的输入数据,可以说是质的飞跃。
最后第四步,进行小细节上的调优:
List中contains():调用indexOf(o)方法 遍历List中的每个元素,每个元素与比较对象进行equals()比较,只要有一个相同,就返回true;而Set中的contain()调用的是map.containKey(o),内部使用的是Hashtable,所以嵌套循环比较存在或者使用contains方法查询元素是否存在,HashSet都要比ArrayList快的多。所以将部分数据结构由List调整为Set。
最终程序优化后,可计时得(电脑性能不同时,略有差异):
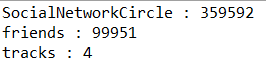
发现构造的轨道系统竟然是近十万人的巨型社交网络!















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









