






毕业设计是要做CGRA的共享存储器的仲裁和修复电路,先从仲裁入手,太久没写verilog有点生疏。
RoundRobin的代码网上有很多。这里主要是看的微信公众号"IC加油站"的老李的资源,copy了一下代码进行调试,代码如下。文章地址:仲裁器设计(二)-- Round Robin Arbiter
`timescale 1ns/1ps
// two paralleled fixed-priority arbiter using mask algorithm
module RR_Arbiter #(
parameter Req_Width = 6
)(
input clk,
input rst,
input [Req_Width-1:0] req,
output [Req_Width-1:0] gnt
);
reg [Req_Width-1:0] Pointer_Req;//denote the next priority
wire [Req_Width-1:0] req_mask;
wire [Req_Width-1:0] priority_mask;
wire [Req_Width-1:0] grant_mask;
wire [Req_Width-1:0] priority_unmask;
wire [Req_Width-1:0] grant_unmask;
wire no_req_mask_label;
//the first FP arbiter with masking
assign req_mask = req & Pointer_Req;
assign priority_mask[0] = 1'b0;
assign priority_mask[Req_Width-1:1] = req_mask[Req_Width-2:0] | priority_mask[Req_Width-2:0];
assign grant_mask[Req_Width-1:0] = req_mask[Req_Width-1:0] & (~priority_mask[Req_Width-1:0]);
//the second FP arbiter without masking
assign priority_unmask[0] = 1'b0;
assign priority_unmask[Req_Width-1:1] = req[Req_Width-2:0] | priority_unmask[Req_Width-2:0];
assign grant_unmask[Req_Width-1:0] = req[Req_Width-1:0] & (~priority_unmask[Req_Width-1:0]);
//Based on the value of req_mask, choose mask or unmask. (if req_mask is none, it means two conditions
//1: no req; 2: req is in the unmask part.
assign no_req_mask_label = ~(|req_mask);
assign gnt = ({Req_Width{no_req_mask_label}} & grant_unmask) | grant_mask;
//Update the Pointer_Reg
always @ (posedge clk) begin
if (rst) begin
Pointer_Req <= {Req_Width{1'b1}};// initialize
end
else begin
if (|req_mask) begin // still have req after mask
Pointer_Req <= priority_mask;
end
else begin // no req after mask, so choose the req with no mask
if (|req) begin //req with no mask have req
Pointer_Req <= priority_unmask;
end
else begin //req with no mask is none, so remain, don't change
Pointer_Req <= Pointer_Req;
end
end
end
end
endmodule其实就是一个简单的组合逻辑加上寄存器存储上一个周期的Pointer_Req用于优先级的轮换,随后编写testbench代码如下:
`timescale 1ns/1ps
module tb_RR_Arbiter #(
parameter Req_Width = 5
)(
//input [Req_Width-1:0] req,
//input clk,
//input rst,
//output reg [Req_Width-1:0] gnt
);
reg [Req_Width-1:0] req;
wire [Req_Width-1:0] gnt;
reg clk;
reg rst;
RR_Arbiter #(5) RRA1 (
.clk(clk),
.rst(rst),
.req(req),
.gnt(gnt)
);
parameter ClockPeriod = 10 ;
initial
begin
clk = 1 ;
repeat(20)
#(ClockPeriod) clk = ~clk;
end
initial
begin
rst = 1;
req = {Req_Width{1'b0}};
#20 rst = 0; req = 6'b01010;
#20 req = 6'b01011;
#20 req = 6'b10011;
#20 req = 6'b01010;
$finish;
end
endmodule
在Modelsim和Vivado中都跑了下代码,仿真会有问题,问题出现在always块中的pointer_req更新后直接被该周期使用了,没有存储给下一周期。因此,给输出加一拍延时缓冲即可,代码改进如下:
`timescale 1ns/1ps
// two paralleled fixed-priority arbiter using mask algorithm
module RR_Arbiter #(
parameter Req_Width = 5
)(
input clk,
input rst,
input [Req_Width-1:0] req,
output [Req_Width-1:0] gnt,
output reg [Req_Width-1:0] Pointer_Req_test, // for test
output reg [Req_Width-1:0] q_test,
output [Req_Width-1:0] req_mask,
output [Req_Width-1:0] priority_mask,
output [Req_Width-1:0] priority_unmask,
output [Req_Width-1:0] grant_unmask,
output [Req_Width-1:0] grant_mask,
output label_req_mask,
output reg [2:0] label_req
);
reg [Req_Width-1:0] Pointer_Req;//denote the next priority
//wire [Req_Width-1:0] req_mask;
//wire [Req_Width-1:0] priority_mask;
//wire [Req_Width-1:0] grant_mask;
//wire [Req_Width-1:0] priority_unmask;
//wire [Req_Width-1:0] grant_unmask;
wire no_req_mask_label;
//the first FP arbiter with masking
assign req_mask = req & Pointer_Req;
assign priority_mask[0] = 1'b0;
assign priority_mask[Req_Width-1:1] = req_mask[Req_Width-2:0] | priority_mask[Req_Width-2:0];//or operation for each bit, from small to big bit
assign grant_mask[Req_Width-1:0] = req_mask[Req_Width-1:0] & (~priority_mask[Req_Width-1:0]);
//the second FP arbiter without masking
assign priority_unmask[0] = 1'b0;
assign priority_unmask[Req_Width-1:1] = req[Req_Width-2:0] | priority_unmask[Req_Width-2:0];//?????????
assign grant_unmask[Req_Width-1:0] = req[Req_Width-1:0] & (~priority_unmask[Req_Width-1:0]);
//Based on the value of req_mask, choose mask or unmask. (if req_mask is none, it means two conditions
//1: no req; 2: req is in the unmask part.
assign no_req_mask_label = ~(|req_mask);
assign gnt = ({Req_Width{no_req_mask_label}} & grant_unmask) | grant_mask;
//test
assign label_req_mask = |req_mask;
//assign label_req = |req;
//reg [Req_Width-1:0] q;
//Update the Pointer_Reg
always @ (posedge clk) begin
#1
if (rst) begin
q_test <= {Req_Width{1'b1}};// initialize
//q_test <= q;
//Pointer_Req <= q_test;
//Pointer_Req_test <= q_test;
label_req <= 1;
//Pointer_Req_test <= {Req_Width{1'b1}};
end
else begin
if (label_req_mask) begin // still have req after mask
q_test <= priority_mask;
//Pointer_Req <= q_test;
//Pointer_Req_test <= q_test;
label_req <= 2;
//Pointer_Req_test <= priority_mask;
end
else begin // no req after mask, so choose the req with no mask
if (|req) begin //req with no mask have req
q_test <= priority_unmask;
//Pointer_Req <= q_test;// delay one clock, otherwise the result will be wrong, since the comb circuit will immediately use the pointer-reg
//Pointer_Req_test <= q_test;
label_req <= 3;
//Pointer_Req_test <= priority_unmask;
end
else begin //req with no mask is none, so remain, don't change
q_test <= Pointer_Req;
//Pointer_Req <= q_test;
//Pointer_Req_test <= q_test;
label_req <= 4;
//Pointer_Req_test <= Pointer_Req;
end
end
end
end
always @ (posedge clk) begin
Pointer_Req <= q_test;
Pointer_Req_test <= q_test;
end
endmodule同时在Always块中加入少许延时,确保每次计算该周期的gnt的时候用的是上一周期的Pointer_Req而不是本周期。随后,tb代码如下:
`timescale 1ns/1ps
module tb_RR_Arbiter #(
parameter Req_Width = 10
)(
//input [Req_Width-1:0] req,
//input clk,
//input rst,
//output reg [Req_Width-1:0] gnt
);
reg [Req_Width-1:0] req;
wire [Req_Width-1:0] gnt;
reg clk;
reg rst;
wire [Req_Width-1:0] Pointer_Req_test;
wire [Req_Width-1:0] q_test;
wire [Req_Width-1:0] req_mask;
wire [Req_Width-1:0] priority_mask;
wire [Req_Width-1:0] priority_unmask;
wire [Req_Width-1:0] grant_mask;
wire [Req_Width-1:0] grant_unmask;
wire label_req_mask;
wire [2:0] label_req;
RR_Arbiter #(Req_Width) RRA1 (
.clk(clk),
.rst(rst),
.req(req),
.gnt(gnt),
.Pointer_Req_test(Pointer_Req_test),
.q_test(q_test),
.req_mask(req_mask),
.priority_mask(priority_mask),
.priority_unmask(priority_unmask),
.grant_mask(grant_mask),
.grant_unmask(grant_unmask),
.label_req_mask(label_req_mask),
.label_req(label_req)
);
parameter ClockPeriod = 10 ;
initial
begin
clk = 1 ;
repeat(40)
#(ClockPeriod) clk = ~clk;
end
initial
begin
rst = 1;
req = {Req_Width{1'b0}};
#40 rst = 0; req = 10'b0000000000;//0
#20 req = 10'b0000001101;//2
#20 req = 10'b0000001110;//cha dui
#20 req = 10'b0001101101;//4
#20 req = 10'b0011101001;
#20 req = 10'b0011100101;
#20 req = 10'b0011000110;
#20 req = 10'b0010000111;//again
#20 req = 10'b0000000111;
#20 req = 10'b1000000110;
#20 req = 10'b1000000110;
#20 req = 10'b1000000011;
$finish;
end
endmodule
得到的仿真图如下:
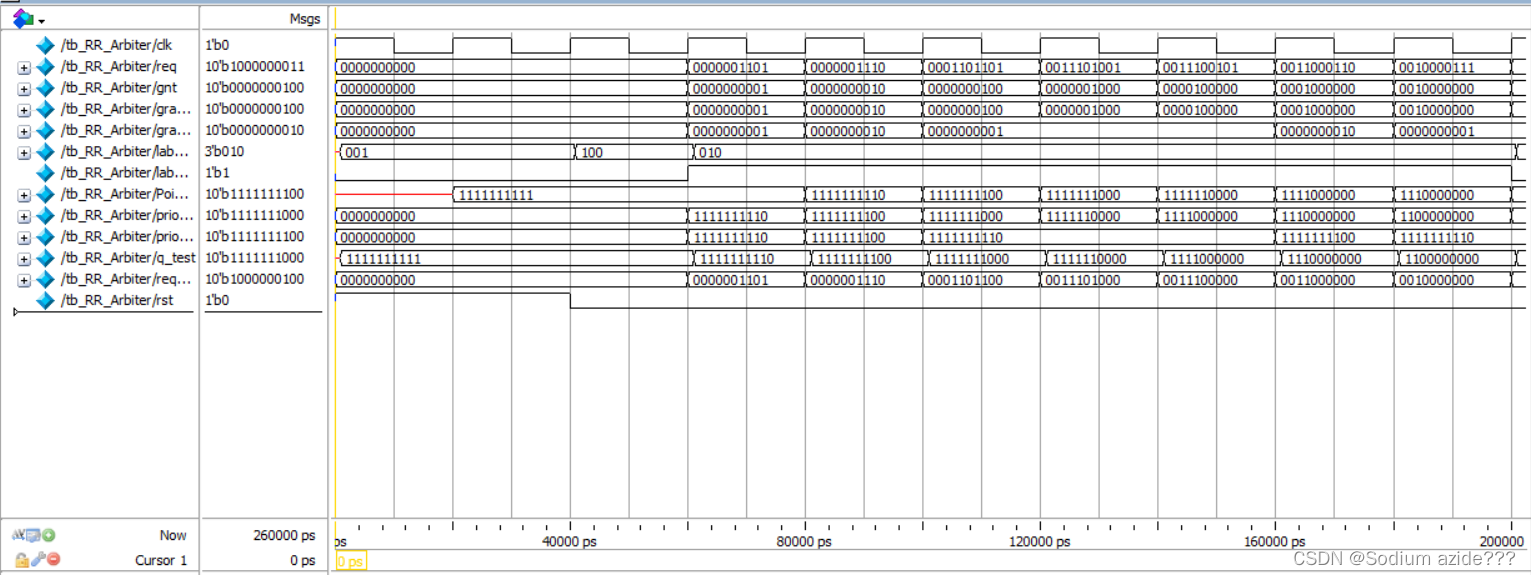
总结:太久没有编写verilog,过于生疏,需要熟练。时序电路的阻塞和非阻塞赋值需要注意,有时候设计时钟上升沿触发,可能输入信号的值变为了这一周期而不是上一周期的,学会用延时去卡拍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









