






一 插入加速
unordered_map 在桶满时自动进行 rehash 操作。手动调用 rehash 函数可以手动调整 桶数量。
rehash 函数被调用时,需要注意以下几点:
- rehash 函数可能会造成 unordered_map 的迭代器失效。如果我们在重新哈希后仍需要继续迭代 unordered_map,则需要重新获取 unordered_map 的迭代器。
- 手动指定桶数量时,应该尽量选择一个合适的值。过小的桶数量会导致哈希冲突概率增加,从而降低 unordered_map 的性能;过大的桶数量会带来额外的空间浪费。通常,桶数量选择 2 的整数幂比选择任意数字要好。
如果对插入的性能有要求,最好事先评估需要的桶的数量,在初始化时候调用reserve()来预留足够的桶,防止后面插入时发送rehash。
二 查看冲突情况和减少冲突概率
查看桶个数、每个桶中元素个数、冲突个数:
size_t collisions = 0;
for (size_t b = 0; b != myMap.bucket_count(); ++b)
if (tuples.bucket_size(bucket) > 1)
collisions += tuples.bucket_size(bucket) - 1;
std::cout << myMap.bucket_count() << "," << myMap.size() << "," << collisions << std::endl;
如果发现冲突较多,可以采用reserve()函数在初始化时增加bucket_count数量,减少冲突概率。
下图中,比较了3种情况下,插入相同的4905个不同合约(类型为std::string)为key的数据:
不reserve多次运行:

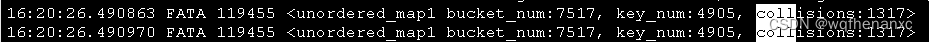
下面第1行是reserve(10000), 第2行是reserve(100000):

可以推测出:
- 默认的std::string 作为key的 hash function以固定的。多次运行,在不提前reserve桶个数前提下,插入相同的一系列数据后, 桶数量和冲突数量每次运行都一样;
- 相同的一系列数据,reserve的桶数量越大,冲突越少;
三 使用struct/class作为key
四 std::string 与 char * 作为key的对比
参考资料:
【1】https://stackoverflow.com/questions/4704521/how-to-i-count-key-collisions-when-using-boostunordered-map
【2】Swisstable:C++中比std::unordered_map更快的hash表 【https://zhuanlan.zhihu.com/p/485294786】
【3】https://deepinout.com/cpp/cpp-tutorials/g_unordered_map-rehash-in-c-stl.html















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









