






1.
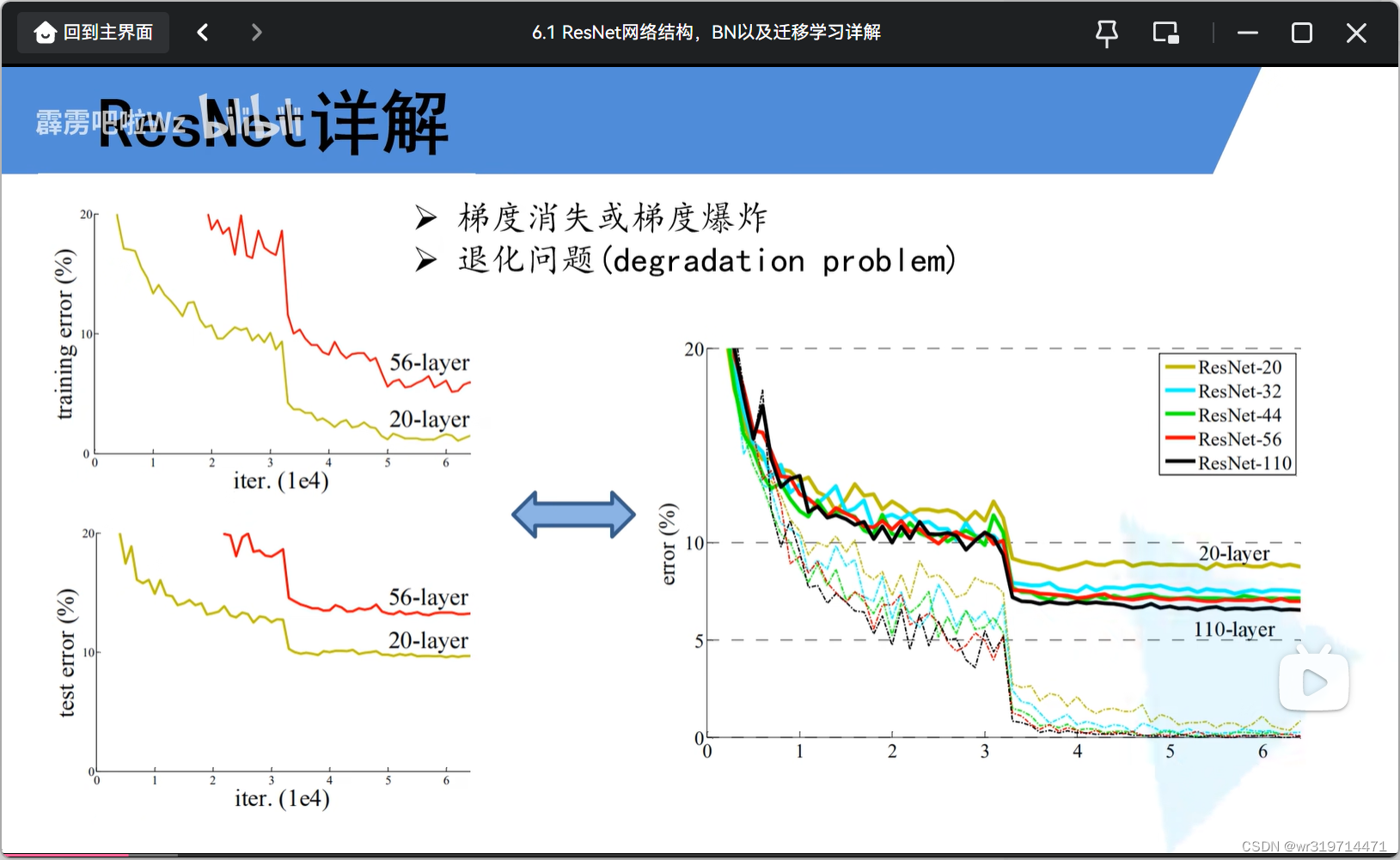
网络并不是层数越多越好
原因:
1.梯度消失或爆炸
a.梯度消失
假设每一层的误差梯度是一个小于1的数,那反向传播过程中,每向前传播一层,都要乘以一个小于1的数,当层数越多时,梯度越趋近于0
b.梯度爆炸(与梯度消失相反)
解决方法:对数据进行标准化处理,权重初始化,bn
2.退化问题
用残差结构解决
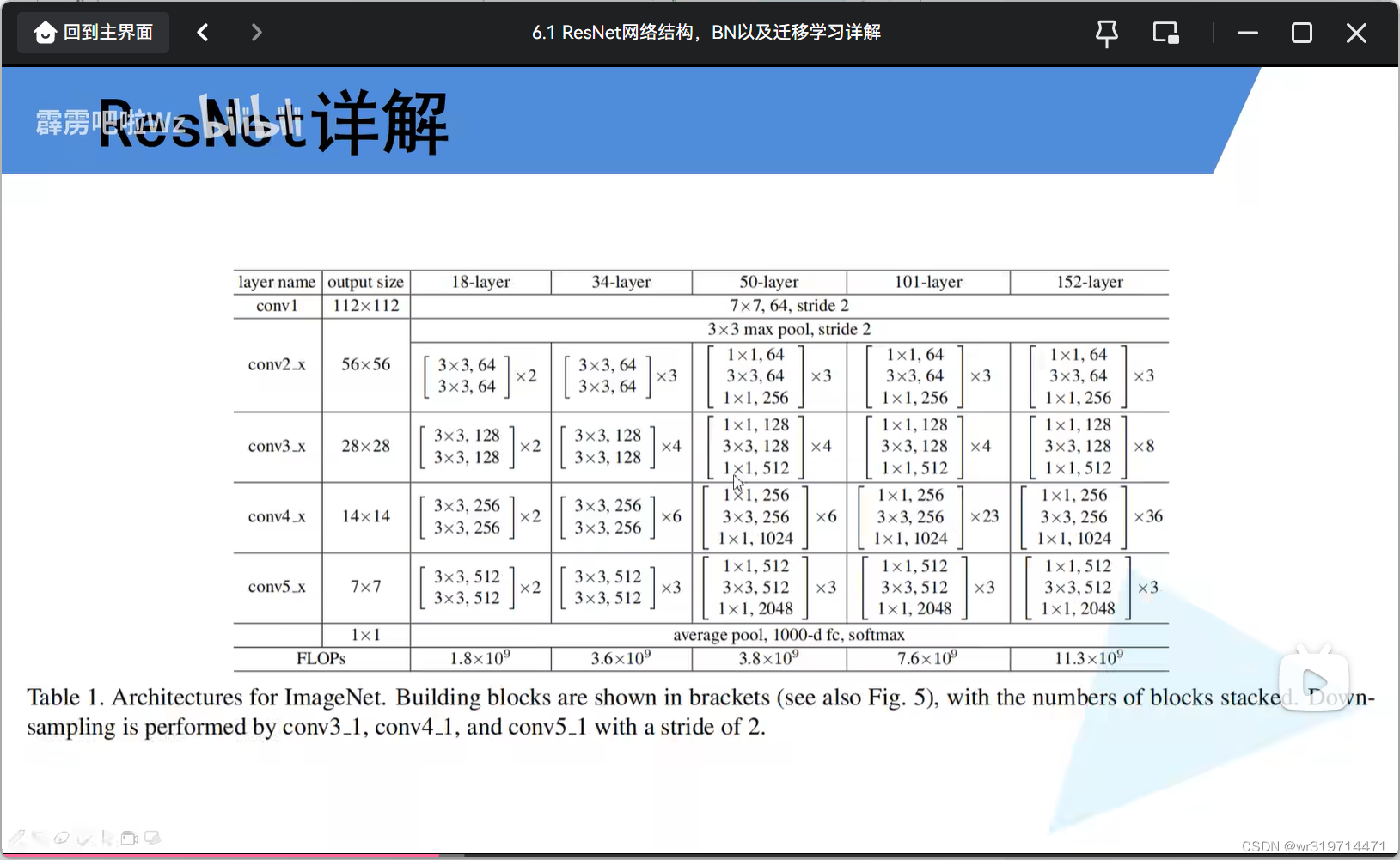
2.网络特点
a.超深的网络结构
b.提出residual模块(残差模块)

左右两个是不同的残差结构
左边针对层数较少的网络结构(34),右边针对层数较多的网络结构(50,101,152)
(1) 以左侧残差结构为例
分为主分支和捷径分支
图中加号的意思是将主分支特征矩阵与捷径分支特征矩阵(高宽和深度应相同 )进行相加,然后通过relu激活函数
(2)右侧残差结构
第一层起降维作用
第三层进行升维
(3)左右对比
右侧所用参数更少
(4)残差结构的实线和虚线
50层结构
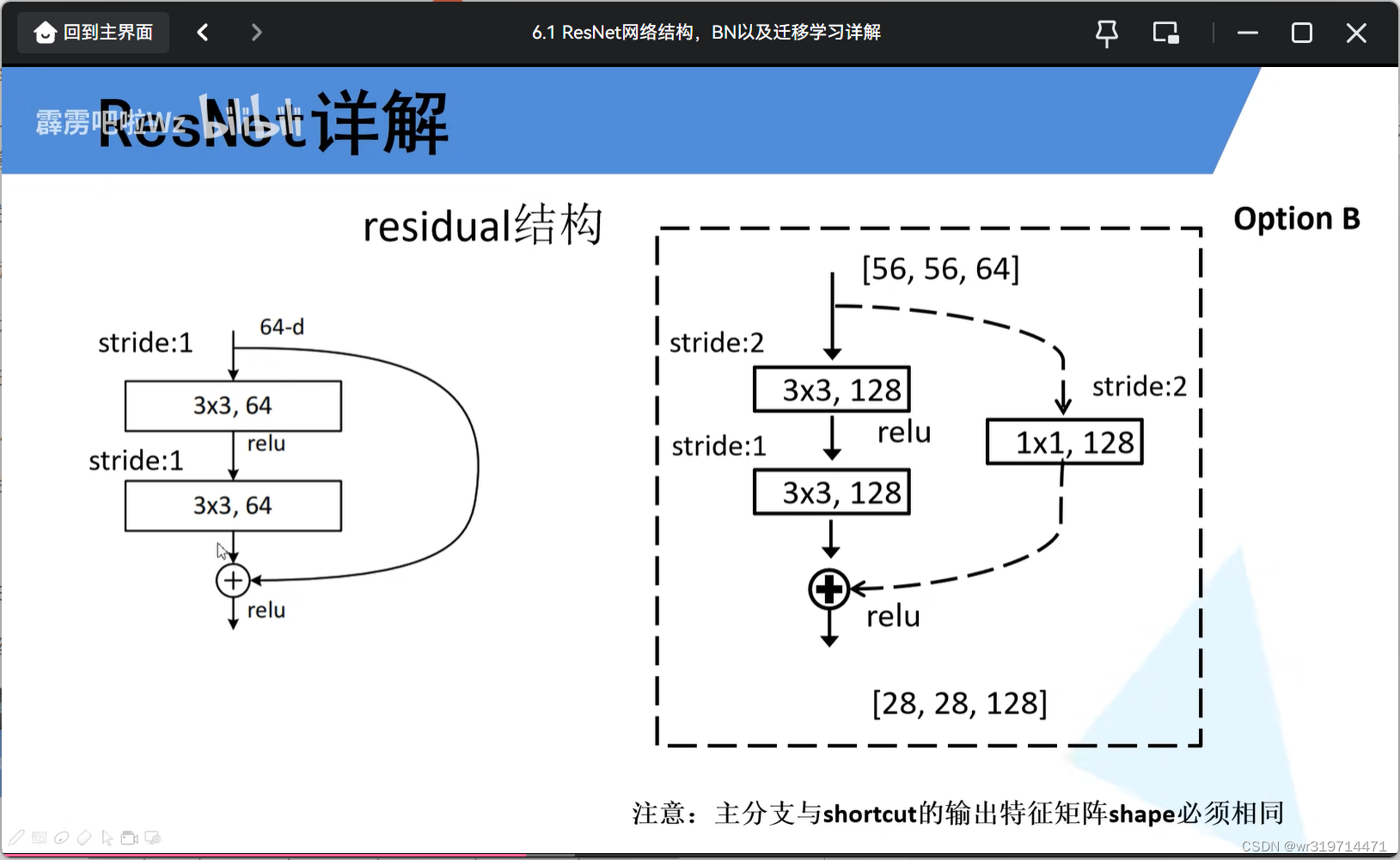
****实线所对应的残差结构输入矩阵和输出矩阵大小和深度相同
而虚线的残差结构得到的·输出矩阵的大小和深度不同于上层(也就是将其改变),而使用于下面一系列残差结构
(1)主分支第一个3*3矩阵的步距改为2(是输出矩阵大小改为28),卷积核个数改为128(使输出特征矩阵深度改为128)
(2)捷径分支加入了一个1*1的卷积层,步距为2,卷积核个数为128,使得到的矩阵与主分支特征矩阵相同
更高层结构
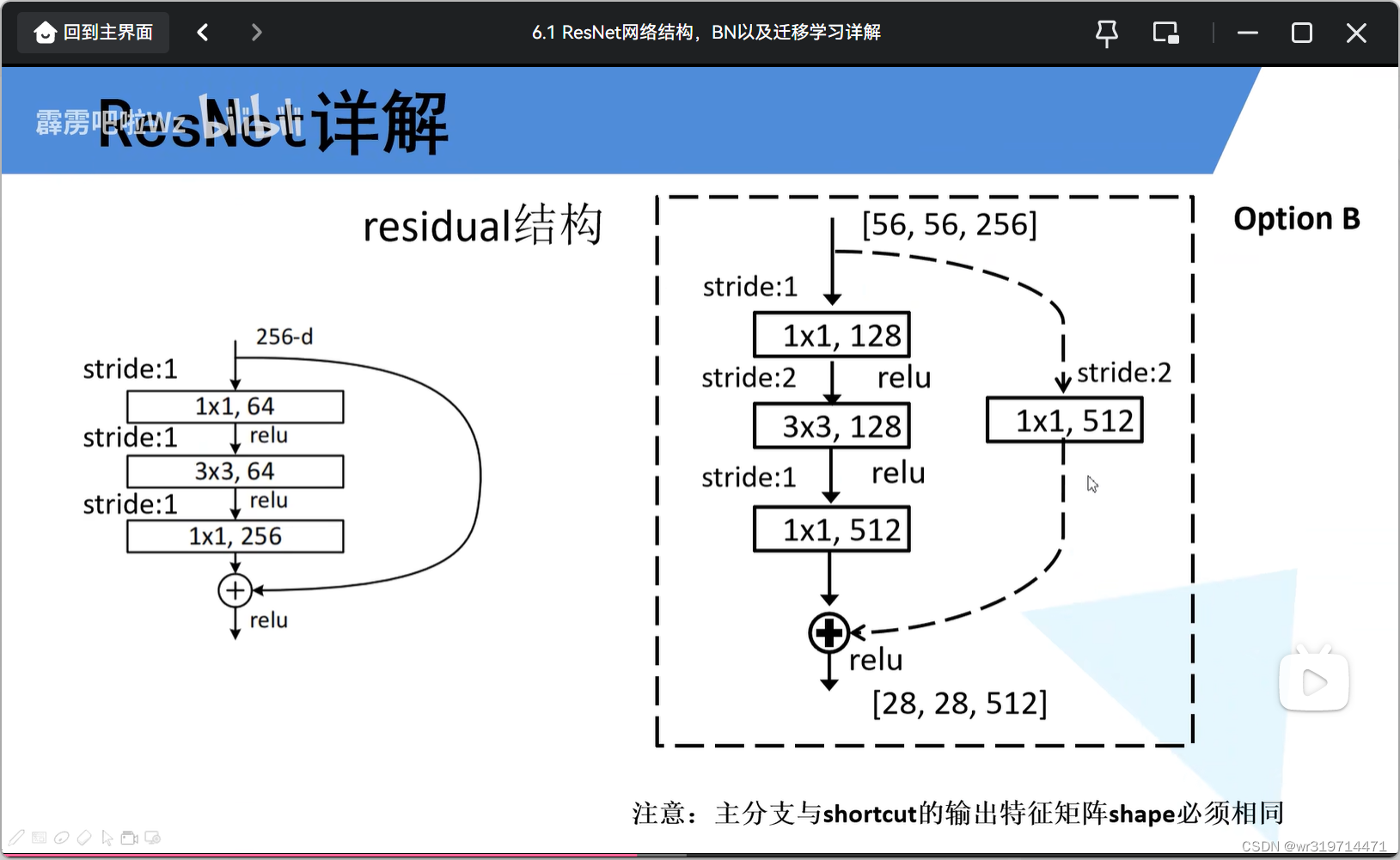
虚线结构中
主分支第一层和第三层作用与实现结构相同,用于降维和升维,第二层用于改变矩阵大小
##下采样操作是通过虚线残差结构实现的
#####对于18层和34层的网络结构,conv2的第一层残差结构不需要用虚线的,因为由上面得到的输出矩阵正好符合下面的结构
#####而对于更高层,conv2的残差结构的第一层也是虚线结构,用于改变深度大小
c.使用Batch Normalization加速训练(这是个标准化方法,用这个就不用dropout了)

搭建网络构成中,第一步我们通常会对图像进行预处理,使其满足某一分布规律,进行加速训练,但经过一个卷积层后得到特征层(feature map)就不一定满足所期望的某一分布规律了。
而bn就是使每一个特征层都满足均值为0,方差为1的分布规律(处理的是一批图像,不是一个)
d.网络结构
2.迁移学习
将学习好的网络的浅层网络的参数迁移到新的网络中
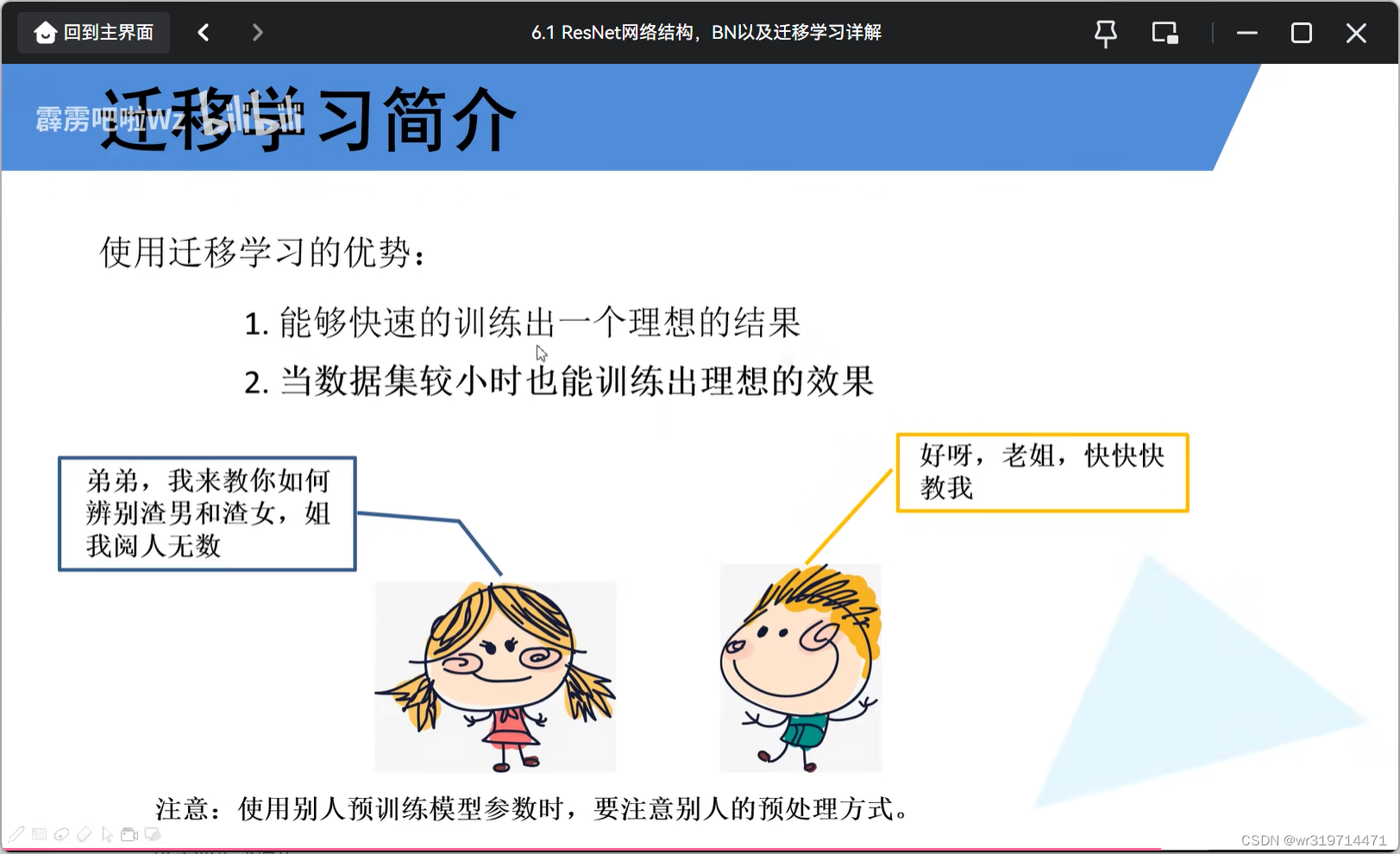
如果网络特别大,网络参数特别多,而数据集又特别小,会出现过拟合的现象
但如果用迁移学习,就可以用别人预训练好的模型参数去训练自己的比较小的数据集,也能由比较好的效果
##注意别人的预处理方式
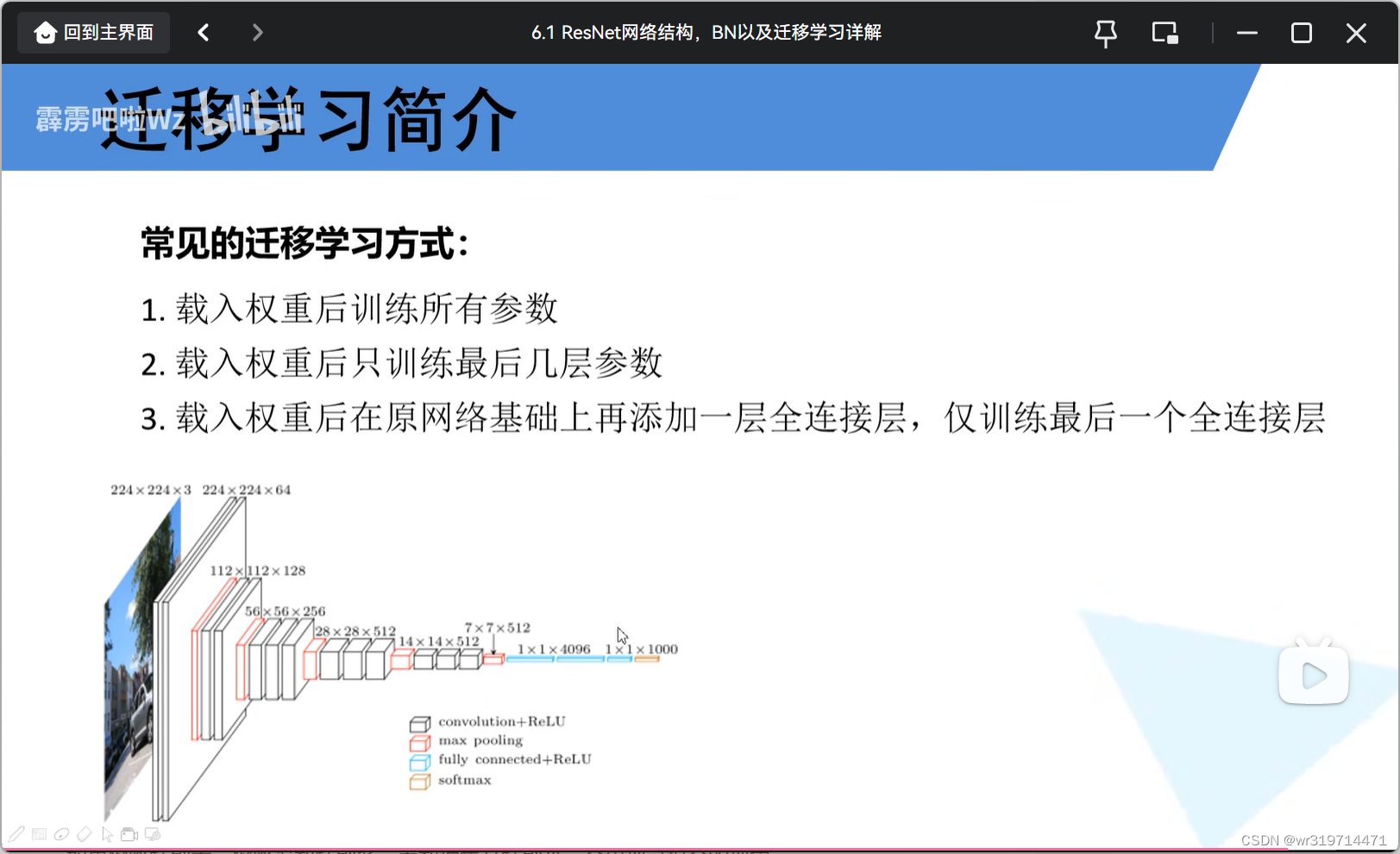
1.载入权重之后,针对自己的数据集训练所有层的网络参数(将最后一层全连接层的节点格式改为自己的类别的个数,最后一层无法载入预训练模型参数,只针对第一种方式)















 6207
6207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









