







transformer可能是替代了restnet
transformer文章 attention is all you need
restnet 文章 deepl residual learning for image recognition
- restnet
task
解决layer层多了,result 的train error增加了,即defradation problem
method
added the identity layers
copy from the shallower model
网络结构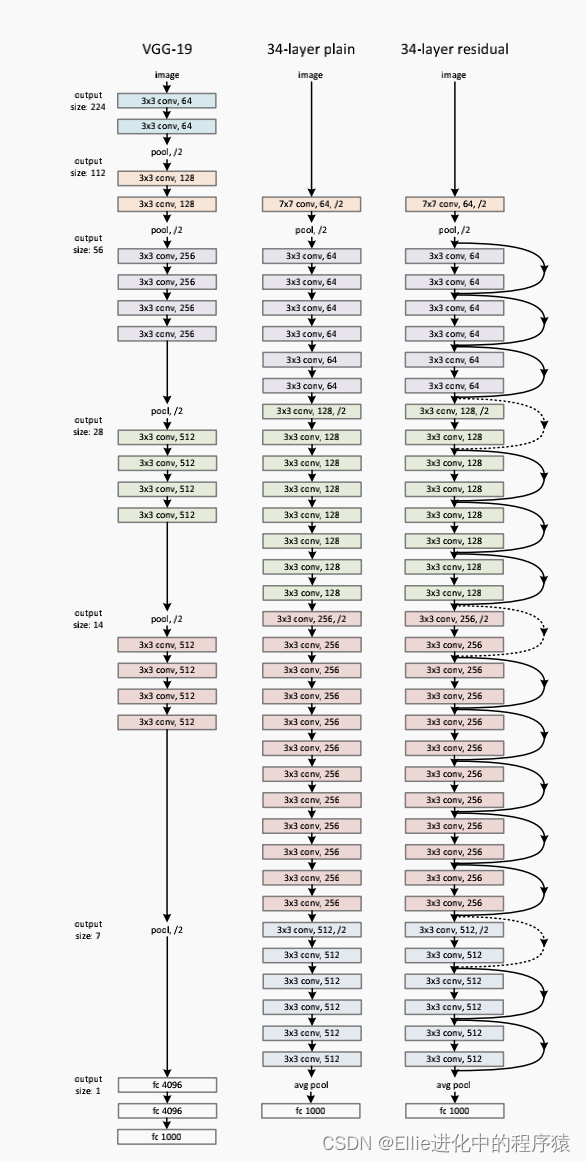
其中
shortcut connection 就是跳过1 or many层。
y = F(x, {Wi}) + Wsx ,这个Ws就是为了match the dimensions
都加到这个stacked layer 堆叠层
这种设计不增加网络复杂性,仍然用SGD的 backpropagation(反向传播)来实现端到端的训练
结果对比
plain net (只有stacked layers)
rest net (加了shortcut)
Residual Representations
For vector quantization,encoding residual vectors [17] is shown to be more effective than encoding original vectors.
也就是说residual 向量比原始的编码向量更好
them are powerful shallow representations for image retrieval and classification
是图像检索和分类的一种强大的浅层表示方法。
- transformer
一个宝贝综述
https://www.cvmart.net/community/detail/4032
结构
插播
CNN是可以同步(parallel),RNN是异步必须等着上面的整完下面的再弄,似乎是上面的output是下面的input。但CNN就很独立,做自己,不管那么多他们可以一起进步。
CNN也有问题,可能会信息丢失,不会考虑前面全部的vector,没有记忆功能。所以说咱就给它shortcut,把前面的信息加进来。
为了解决这个CNN的问题
出来一个self-attension
q(query),k(key),v(原本提取出来的信息)
q*k 看和v的match程度
去看上面的链接,他写的比较明白!!!!!
muti-head-attention就是把上面单个出来的结果给它concat一下,然后再调成和一个一样的维度
embadding
就是做这个scaled inner product 就是缩放内积,转化成feature?
经历了这个
CNN+attention就是yyds 又能并行,又可以记录下前面的信息也放到网络里面
position encoding是由于整个模型的设计中所有的input 都是统一对待的,而在NLP的任务中,所有的输入的顺序是很关键的,一句话如果字的顺序发生颠倒,可能会变成完全另一个意思,因此,加入一个了position encoding 的特征来表示这个input (文中用token 表示) 是输入的顺序信息.
scale dot-product attention 中的mask 则是为了防止在实时翻译任务中, 输出利用到尚未当前时刻之后的输入的信息,在全量的input上面加上一个mask 这样就可以防止模型未卜先知利用到当前时刻后的输入的信息,防止实时NLP中任务中实际无法得到这些信息造成的问题.
这个引用的https://zhuanlan.zhihu.com/p/326892493 这个文章
vit2021 这个需要再继续看一下
文章:AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
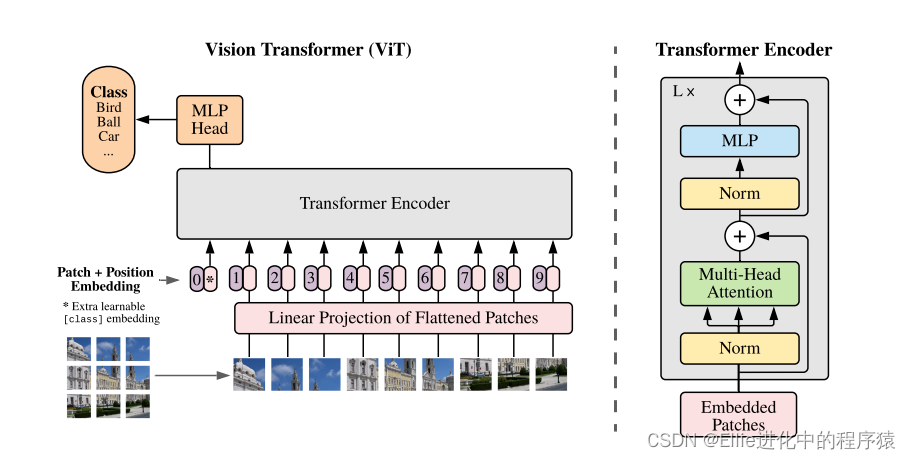
效果
在大规模的数据集上面做了预训练之后效果就会发生根本性的改变

下一期maybe
Vision Transformer and Swing Transformer














 8701
8701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









