









Q-learning
算法描述:

Sarsa
算法描述:

假设我们的 Q(s, a) 是一个 Q table ,如下图所示,该表格表示共有三个 state (状态): s 1 s_{1} s1 、 s 2 s_{2} s2、 s 3 s_{3} s3 ,每个状态都有三个可选 action (动作) : a 1 a_{1} a1、 a 2 a_{2} a2、 a 3 a_{3} a3 ,对所有的状态-动作以 0 赋值:
| Q(s, a) | a 1 a_{1} a1 | a 2 a_{2} a2 | a 3 a_{3} a3 |
|---|---|---|---|
| s 1 s_{1} s1 | 0 | 0 | 0 |
| s 2 s_{2} s2 | 0 | 0 | 0 |
| s 3 s_{3} s3 | 0 | 0 | 0 |
Q-learning 算法和 Sarsa 算法都是从状态 s 开始,根据当前的 Q table 使用一定的策略(ε - greedy)选择一个动作 a’ ,然后观测到下一个状态 s’ ,并再次根据 Q table 选择动作 a’ 。
- Q-learning 算法更新 Q(s, a)
- Sarsa 算法更新 Q(s, a)
可以看出更新 Q(s, a) 需要用到下一个状态的动作 a’ ,而两种算法的不同点正是选取 a’ 的方法不同。
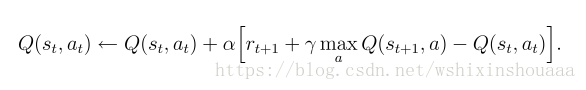
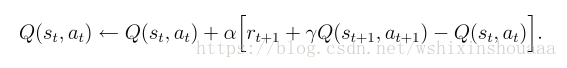
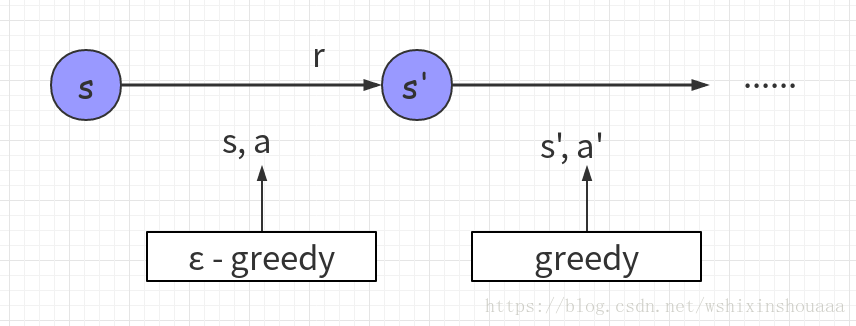
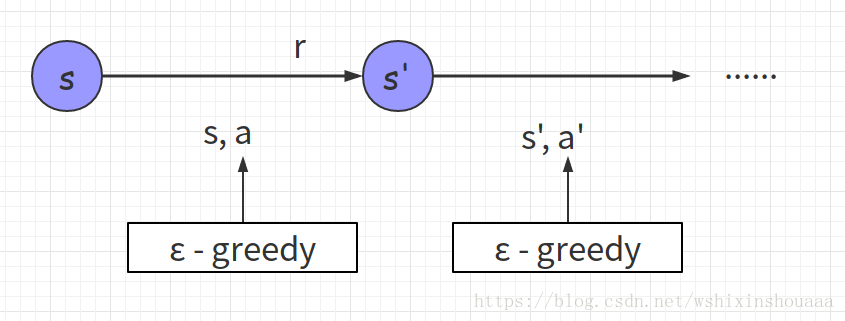
不同点: 根据算法描述,在选择新状态 s‘ 的动作 a’ 时,Q-learning 使用贪心策略(greedy),即选取值最大的 a‘ ,此时只是计算出哪个 a‘ 可以使 Q(s, a) 取到最大值,并没有真正采用这个动作 a‘ ;而 Sarsa 则是仍使用 ε - greedy 策略,并真正采用了这个动作 a‘ 。如下图所示:
- Q-learning 选取 a’
- Sarsa 选取 a’














 5504
5504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









