










在上一篇文章中,我们介绍了基本RAG的构建,也探讨了RAG管道中从小到大检索技术的两种主要技术:父文档检索和句子窗口检索。
在本文,我们将深入探讨一下从小到大检索技术中的父文档检索。
一、块引用:较小的子块引用较大的父块
为了让您快速回顾一下什么是父文档检索或小孩块引用更大的父块,以下是我们在上一篇文章中谈到的内容:
首先检索与回答查询最相关的较小数据段,然后使用它们相关的父标识符访问并返回将作为上下文传递给LLM(大型语言模型)的较大父数据块。在LangChain中,这可以通过ParentDocumentRetriever来完成。
让我们使用此技术构建一个管道。我们将构建一些子块来指向或引用较大父块。在查询期间,我们对较小的块执行搜索,并将他们的父块作为上下文传递给LLM。这样我们能够向LLM传递语音更大、更丰富的上下文,从而减少产生幻觉。
二、数据处理
要将数据存储到矢量存储并永久保存,我们可以使用如下几个步骤来实现这一点。
2.1 项目目录设置
基于我们在上一篇文章中创建的项目目录设置。移动到ParentDocumentRetrieval文件夹,并在其中添加一个main.py文件。

2.2 创建子节点或块
对于1024个字符长的每个文本段,我们将其进一步划分为更小的段:
- 八个段,每个段128个字符;
- 四个段,每个段256个字符;
- 两个段各512个字符。此外,我们还将最初的1024个字符的文本段包含到我们的段集合中。
最后,我们得到173个单独的节点。将chunk_overlap=0至关重要。下面是实现的代码:
from llama_index import (Document,StorageContext,VectorStoreIndex,SimpleDirectoryReader,ServiceContext,load_index_from_storage,)from llama_index.retrievers import RecursiveRetrieverfrom llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.schema import IndexNodefrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)# load datadocuments = SimpleDirectoryReader(input_dir="../dataFiles").load_data(show_progress=True)doc_text = "\n\n".join([d.get_content() for d in documents])docs = [Document(text=doc_text)]# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=docs)# set document IDsfor idx, node in enumerate(base_nodes):node.id_ = f"node-{idx}"# create parent child documentssub_chunk_sizes = [128, 256, 512]sub_node_parsers = [SimpleNodeParser.from_defaults(chunk_size=c, chunk_overlap=0) for c in sub_chunk_sizes]all_nodes = []for base_node in base_nodes:for n in sub_node_parsers:sub_nodes = n.get_nodes_from_documents([base_node])sub_inodes = [IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes]all_nodes.extend(sub_inodes)# also add original node to nodeoriginal_node = IndexNode.from_text_node(base_node, base_node.node_id)all_nodes.append(original_node)all_nodes_dict = {n.node_id: n for n in all_nodes}print(all_nodes[0])print(len(all_nodes_dict))# creating indexindex = VectorStoreIndex(nodes=all_nodes, service_context=service_context)

这是第一步,接下来怎么办?
2.3 创建检索器(递归检索器)
现在我们已经创建了嵌入,让我们开始创建一个检索器。以下是执行此操作的代码:
from llama_index import (Document,StorageContext,VectorStoreIndex,SimpleDirectoryReader,ServiceContext,load_index_from_storage,)from llama_index.retrievers import RecursiveRetrieverfrom llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.schema import IndexNodefrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)# load datadocuments = SimpleDirectoryReader(input_dir="../dataFiles").load_data(show_progress=True)doc_text = "\n\n".join([d.get_content() for d in documents])docs = [Document(text=doc_text)]# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=docs)# set document IDsfor idx, node in enumerate(base_nodes):node.id_ = f"node-{idx}"# create parent child documentssub_chunk_sizes = [128, 256, 512]sub_node_parsers = [SimpleNodeParser.from_defaults(chunk_size=c, chunk_overlap=0) for c in sub_chunk_sizes]all_nodes = []for base_node in base_nodes:for n in sub_node_parsers:sub_nodes = n.get_nodes_from_documents([base_node])sub_inodes = [IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes]all_nodes.extend(sub_inodes)# also add original node to nodeoriginal_node = IndexNode.from_text_node(base_node, base_node.node_id)all_nodes.append(original_node)all_nodes_dict = {n.node_id: n for n in all_nodes}# creating indexindex = VectorStoreIndex(nodes=all_nodes, service_context=service_context)# creating a chunk retrievervector_retriever_chunk = index.as_retriever(similarity_top_k=2)retriever_chunk = RecursiveRetriever("vector",retriever_dict={"vector": vector_retriever_chunk},node_dict=all_nodes_dict,verbose=True,)# retrieve needed nodesnodes = retriever_chunk.retrieve("Can you tell me about the key concepts for safety finetuning")for node in nodes:print(node)
上面的代码只检索节点并将其打印到屏幕上,以下是代码的输出:

现在,让我们实现RetrieveQueryEngine:
from llama_index import (Document,StorageContext,VectorStoreIndex,SimpleDirectoryReader,ServiceContext,load_index_from_storage,)from llama_index.retrievers import RecursiveRetrieverfrom llama_index.query_engine import RetrieverQueryEnginefrom llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.schema import IndexNodefrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)# load datadocuments = SimpleDirectoryReader(input_dir="../dataFiles").load_data(show_progress=True)doc_text = "\n\n".join([d.get_content() for d in documents])docs = [Document(text=doc_text)]# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=docs)# set document IDsfor idx, node in enumerate(base_nodes):node.id_ = f"node-{idx}"# create parent child documentssub_chunk_sizes = [128, 256, 512]sub_node_parsers = [SimpleNodeParser.from_defaults(chunk_size=c, chunk_overlap=0) for c in sub_chunk_sizes]all_nodes = []for base_node in base_nodes:for n in sub_node_parsers:sub_nodes = n.get_nodes_from_documents([base_node])sub_inodes = [IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes]all_nodes.extend(sub_inodes)# also add original node to nodeoriginal_node = IndexNode.from_text_node(base_node, base_node.node_id)all_nodes.append(original_node)all_nodes_dict = {n.node_id: n for n in all_nodes}# creating indexindex = VectorStoreIndex(nodes=all_nodes, service_context=service_context)# creating a chunk retrievervector_retriever_chunk = index.as_retriever(similarity_top_k=2)retriever_chunk = RecursiveRetriever("vector",retriever_dict={"vector": vector_retriever_chunk},node_dict=all_nodes_dict,verbose=True,)query_engine_chunk = RetrieverQueryEngine.from_args(retriever_chunk, service_context=service_context)response = query_engine_chunk.query("What did the president say about Covid-19")print(str(response))
在上面的代码中,我去掉了这几行代码:
retriever_chunk = RecursiveRetriever("vector",retriever_dict={"vector": vector_retriever_chunk},node_dict=all_nodes_dict,verbose=True,)# retrieve needed nodesnodes = retriever_chunk.retrieve("Can you tell me about the key concepts for safety finetuning")for node in nodes:print(node)
运行代码,这是输出:
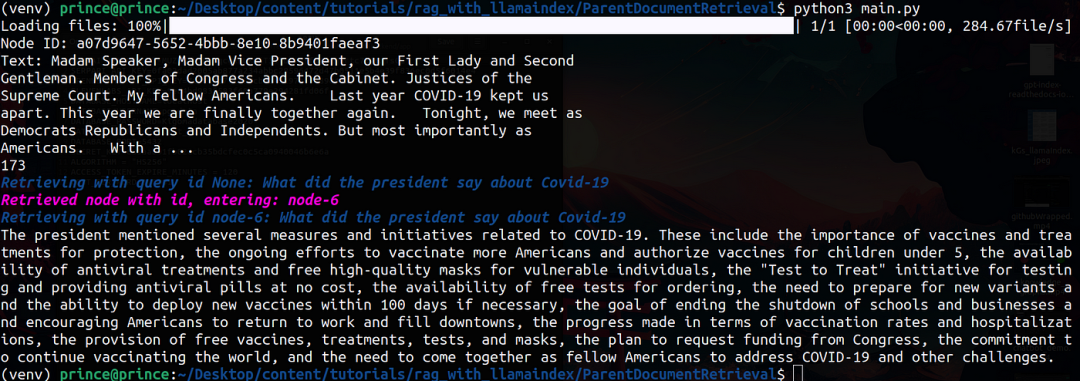
三、评估
现在,让我们继续评估管道的性能。
我要做的第一件事是将Sqlite文件从basicRAG文件夹复制到ParentDocumentRetrieval文件夹中,这样做的目的是为了保留我们从上一篇文章中构建的基本RAG管道的度量,方便进行性能比较,如果您不想这样做,则不必这样做。还有一种方法可以解决此问题:指向Sqlite数据库的路径,这可以通过以下方式完成:
# RAG pipeline evalstru = Tru(database_file="<file_path_to_database_you_want_to_use>")
您可以使用下面的代码来评估管道的性能。复制完default.sqlite文件后,您的项目目录应该如下所示:

您还可以针对一系列问题评估您的最终RAG管道。在这个文件的旁边创建一个名为eval_questions.txt的文件,输入以下问题来进行评估:
-
What measures did the speaker announce to support Ukraine in the conflict mentioned?
-
How does the speaker propose to address the challenges faced by the United States in the face of global conflicts, specifically mentioning Russia’s actions?
-
What is the speaker’s plan to combat inflation and its impact on American families?
-
How does the speaker suggest the United States will support the Ukrainian people beyond just military assistance?
-
What is the significance of the speaker’s reference to the NATO alliance in the context of recent global events?
-
Can you detail the economic sanctions mentioned by the speaker that are being enforced against Russia?
-
What actions have been taken by the U.S. Department of Justice in response to the crimes of Russian oligarchs as mentioned in the speech?
-
How does the speaker describe the American response to COVID-19 and the current state of the pandemic in the country?
-
What are the four common-sense steps the speaker mentions for moving forward safely in the context of COVID-19?
-
How does the speaker address the economic issues such as job creation, infrastructure, and the manufacturing sector in the United States?
eval_questions.txt文件应与main.py文件位于同一目录中。这样做的目的是使我们能够针对多个问题而不是像上一篇文章中那样仅针对一个问题来评估RAG管道。
from typing import Listfrom llama_index import (Document,VectorStoreIndex,SimpleDirectoryReader,ServiceContext,)from llama_index.retrievers import RecursiveRetrieverfrom llama_index.query_engine import RetrieverQueryEnginefrom llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.schema import IndexNodefrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport osfrom trulens_eval import Feedback, Tru, TruLlamafrom trulens_eval.feedback import Groundednessfrom trulens_eval.feedback.provider.openai import OpenAI as OpenAITruLensimport numpy as np# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)# load datadocuments = SimpleDirectoryReader(input_dir="../dataFiles").load_data(show_progress=True)doc_text = "\n\n".join([d.get_content() for d in documents])docs = [Document(text=doc_text)]# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=docs)# set document IDsfor idx, node in enumerate(base_nodes):node.id_ = f"node-{idx}"# create parent child documentssub_chunk_sizes = [128, 256, 512]sub_node_parsers = [SimpleNodeParser.from_defaults(chunk_size=c, chunk_overlap=0) for c in sub_chunk_sizes]all_nodes = []for base_node in base_nodes:for n in sub_node_parsers:sub_nodes = n.get_nodes_from_documents([base_node])sub_inodes = [IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes]all_nodes.extend(sub_inodes)# also add original node to nodeoriginal_node = IndexNode.from_text_node(base_node, base_node.node_id)all_nodes.append(original_node)all_nodes_dict = {n.node_id: n for n in all_nodes}# creating indexindex = VectorStoreIndex(nodes=all_nodes, service_context=service_context)# creating a chunk retrievervector_retriever_chunk = index.as_retriever(similarity_top_k=2)retriever_chunk = RecursiveRetriever("vector",retriever_dict={"vector": vector_retriever_chunk},node_dict=all_nodes_dict,verbose=True,)query_engine_chunk = RetrieverQueryEngine.from_args(retriever_chunk, service_context=service_context)# RAG pipeline evalstru = Tru()openai = OpenAITruLens()grounded = Groundedness(groundedness_provider=OpenAITruLens())# Define a groundedness feedback functionf_groundedness = Feedback(grounded.groundedness_measure_with_cot_reasons).on(TruLlama.select_source_nodes().node.text).on_output().aggregate(grounded.grounded_statements_aggregator)# Question/answer relevance between overall question and answer.f_qa_relevance = Feedback(openai.relevance).on_input_output()# Question/statement relevance between question and each context chunk.f_qs_relevance = Feedback(openai.qs_relevance).on_input().on(TruLlama.select_source_nodes().node.text).aggregate(np.mean)tru_query_engine_recorder = TruLlama(query_engine_chunk,app_id='Parent_document_retrieval',feedbacks=[f_groundedness, f_qa_relevance, f_qs_relevance])eval_questions = []with open("./eval_questions.txt", "r") as eval_qn:for qn in eval_qn:qn_stripped = qn.strip()eval_questions.append(qn_stripped)def run_eval(eval_questions: List[str]):for qn in eval_questions:# eval using context windowwith tru_query_engine_recorder as recording:query_engine_chunk.query(qn)run_eval(eval_questions=eval_questions)# run dashboardtru.run_dashboard()
一旦运行了代码,您就可以点击终端中的链接
这将打开一个Streamlit web应用程序,界面如下所示:
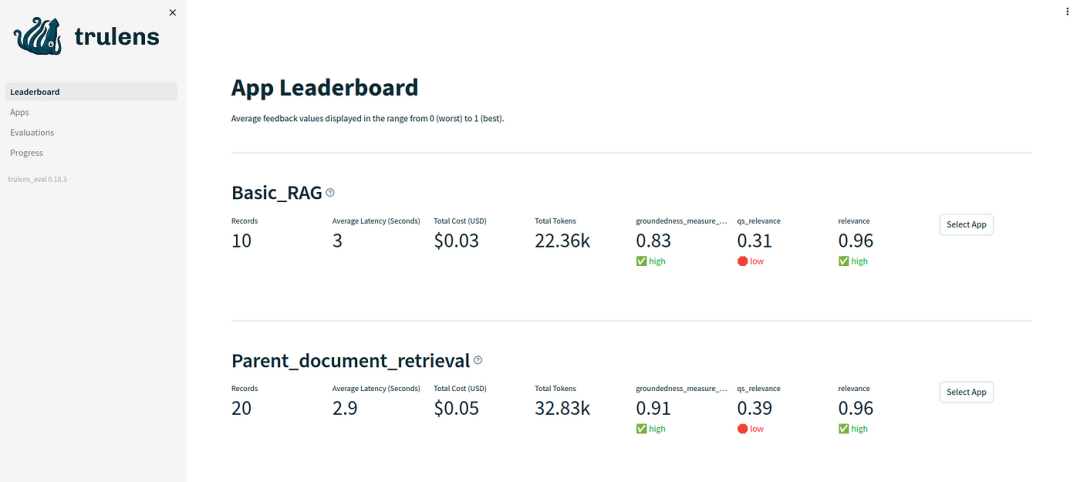
从上图中,我们可以看到Parent Document Retrieval管道比基本的RAG管道LlamaIndex_App1应用程序好很多。
参考文献:
[1] https://ai.gopubby.com/advanced-retrieval-techniques-in-rag-part-02-parent-document-retrieval-334cd924a36e















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











