







什么是JDBC?
JDBC 规范定义接口,具体的实现由各大数据库厂商来实现。
JDBC 是 Java 访问数据库的标准规范,真正怎么操作数据库还需要具体的实现类,也就是数据库驱动。每个数据库厂商根据自家数据库的通信格式编写好自己数据库的驱动。所以我们只需要会调用 JDBC 接口中的方法即可,数据库驱动由数据库厂商提供。
JDBC核心API
- DriverManager 类
- 管理和注册数据库驱动
- 得到数据库连接对象
- Connection 接口:一个连接对象,可用于创建 Statement 和 PreparedStatement 对象;
- Statement 接口:一个 SQL 语句对象,用于将 SQL 语句发送给数据库服务器;
- PreparedStatemen 接口:一个 SQL 语句对象,是 Statement 的子接口;
- ResultSet 接口:返回结果集的接口;
连接Hive
添加依赖及配置文件
添加依赖
- MAVEN工程增加依赖(版本不一致见官网:https://mvnrepository.com/);
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
配置文件
- 增加log4j配置文件:

log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/hadoop.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
* 将配置信息添加至资源包内: 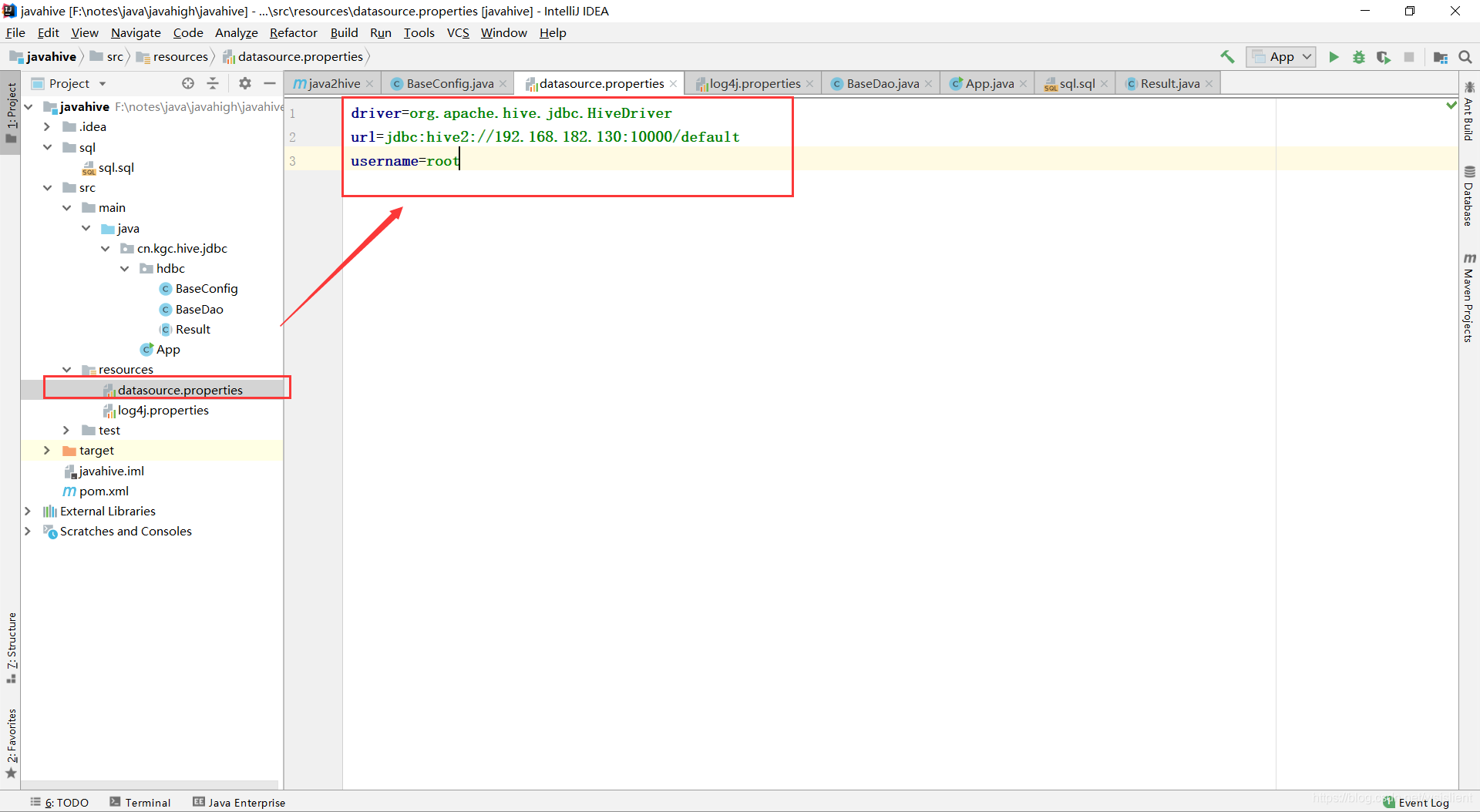
driver=org.apache.hive.jdbc.HiveDriver
url=jdbc:hive2://192.168.182.130:10000/default
username=root
编写BaseConfig类
package cn.kgc.hive.jdbc.hdbc;
import java.io.BufferedReader;
import java.io.FileReader;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class BaseDao extends BaseConfig {
private PreparedStatement getPst(Connection con,String sql,Object...params) throws SQLException {
//创建SQL语句对象PreparedStatement
PreparedStatement pst = con.prepareStatement(sql);
if(params.length>0){
for (int i = 0; i <params.length ; i++) {
pst.setObject(i+1,params[i]);
}
}
return pst;
}
//编写无结果返回方法
public Result exeNoQuery(String sql,Object...params){
Connection con = null;
PreparedStatement pst = null;
try {
con=getCon();
pst=getPst(con,sql,params);
pst.execute();
return Result.succeed();
} catch (SQLException e) {
e.printStackTrace();
return Result.fail();
}finally{
close(pst,con);
}
}
//编写结果返回方法
public Result exeQuery(String sql,Object...params){
Connection con = null;
PreparedStatement pst = null;
ResultSet rst = null;
try {
con = getCon();
pst = getPst(con,sql,params);
rst = pst.executeQuery();
List<List<String>> table = null;
if(null != rst && rst.next()){
table = new ArrayList<>();
final int COL = rst.getMetaData().getColumnCount();
do {
List<String> row = new ArrayList<>(COL);
for (int i = 1; i < COL; i++) {
row.add(rst.getObject(i).toString());
}
table.add(row);
}while(rst.next());
}
return Result.succeed(table);
} catch (SQLException e) {
e.printStackTrace();
return Result.fail();
}finally{
close(rst,pst,con);
}
}
//编写读取SQL语句方法
public String readSql(String...paths) throws Exception {
String path = paths.length==0?"sql/sql.sql":paths[0];
StringBuilder builder = new StringBuilder();
BufferedReader reader= new BufferedReader(new FileReader(path));
String line = null;
if(null !=(line=reader.readLine())){
builder.append(line.trim()+" ");
}
return builder.toString();
}
}
编写BaseConfig类
package cn.kgc.hive.jdbc.hdbc;
import java.io.FileReader;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Properties;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class BaseConfig {
private class Config{
private String driver;
private String url;
private String username;
private String password;
}
Config config;
//编写url正则匹配方法
private boolean vaild(String url){
Pattern p = Pattern.compile("jdbc:\\w+://((\\d{1,3}\\.){3}\\d{1,3}|\\w+):\\d{1,5}/\\w+");
Matcher m = p.matcher(url);
return m.matches();
}
//编写初始化方法
private void init() throws Exception {
String path = Thread.currentThread().getContextClassLoader()
.getResource("datasource.properties").getPath();
Properties pro = new Properties();
pro.load(new FileReader(path));
String url = pro.getProperty("url");
if(null == url && !vaild(url)){
throw new Exception("no or invaild url exception!");
}
config = new Config();
config.url = url;
config.driver = pro.getProperty("driver","com.mysql.jdbc.Driver");
config.username = pro.getProperty("username","root");
config.password = pro.getProperty("password","");
}
//初始化
{
try {
init();
Class.forName(config.driver);
} catch (Exception e) {
e.printStackTrace();
}
}
//创建数据库连接对象
Connection getCon() throws SQLException {
return DriverManager.getConnection(
config.url,
config.username,
config.password);
}
//关闭连接对象方法类
void close(AutoCloseable...closeables){
for (AutoCloseable closeable : closeables) {
if(null!= closeable){
try {
closeable.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
编写Result类
package cn.kgc.hive.jdbc.hdbc;
public abstract class Result<T> {
private boolean err;
private T data;
public Result(boolean err, T...data) {
this.err = err;
this.data = data.length>0?data[0]:null;
}
public boolean isErr() {
return err;
}
public T getData() {
return data;
}
public static Result fail(){
return new Result(true) {};
}
public static <T> Result succeed(T...t){
return new Result(false,t) {};
}
}
测试结果
编写sql
select
b.continent,
b.cname,
b.month,
b.count
from(
select
a.continent,
a.countryname cname,
substr(a.recorddate,1,6) month,
a.recorddate day,
a.confirmedcount count,
row_number() over(distribute by a.continent, substr(a.recorddate,1,6) sort by cast(a.recorddate as int) desc,a.confirmedcount desc ) rownum
from
ex_exam_record a)b
where
b.rownum =1
测试
package cn.kgc.hive.jdbc;
import jdbc.hdbc.BaseDao;
import jdbc.hdbc.Result;
import java.util.List;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args ) throws Exception {
BaseDao dao = new BaseDao();
Result<List<List<String>>> tables =dao.exeQuery(dao.readSql());
tables.getData().forEach(row->{
row.forEach(cell->{
System.out.print(cell+"\t");
});
});
System.out.println();
}
}
PS:如果有写错或者写的不好的地方,欢迎各位大佬在评论区留下宝贵的意见或者建议,敬上!如果这篇博客对您有帮助,希望您可以顺手帮我点个赞!不胜感谢!
| 原创作者:wsjslient |















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









