







ASCII 编码
American Standard Code for Information Interchange(美国标准信息交换码)
定义
- 它只是一种编码格式,规定了字符如何在计算机中用二进制数字进行表示
- 标准的单字节字符编码方案,用于基于文本的数据。起始于50年代后期,在1967年定案。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准
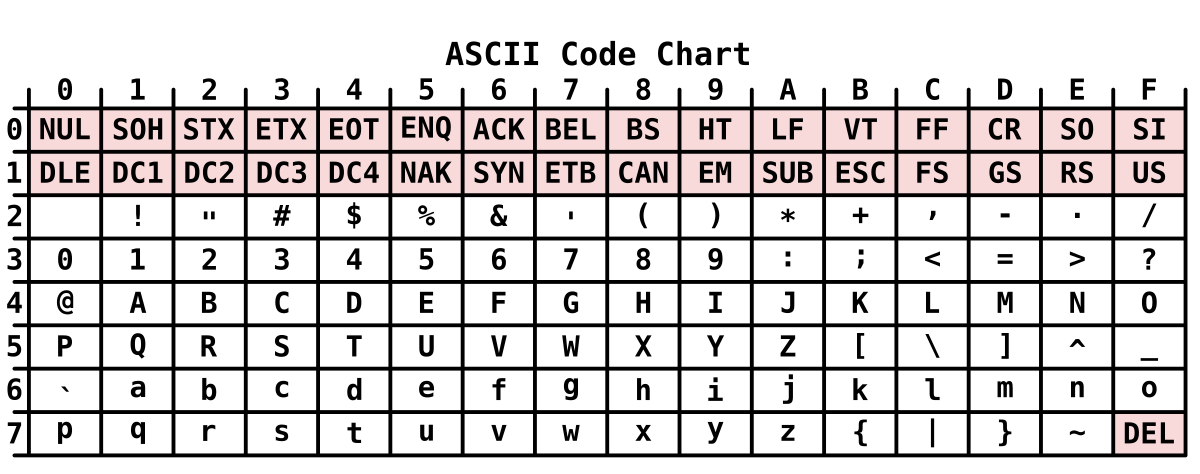
- [外链图片转存失败(img-pGDnFVAM-1563845537408)(https://upload.wikimedia.org/wikipedia/commons/thumb/4/4f/ASCII_Code_Chart.svg/1200px-ASCII_Code_Chart.svg.png)]
属性
- 是编码
- 不是存储(没有对应的文件格式)
占用字节、位
- 每个ASCII字符占用1个字节(8bits)
现状
- 只占用了一个字节的后面7位,最前面的一位统一规定为0;
优缺点
- 对其他国家太少了,中国一万多个汉字,于是美帝主义产生了ANSI
ANSI 编码
ANSI:美国国家标准学会

定义
- ANSI编码是一种对ASCII码的拓展:ANSI编码用0x00~0x7f (即十进制下的0到127)范围的1 个字节来表示 1 个英文字符;
- 为使计算机支持更多语言,通常使用 0x80~0xFFFF 范围的 2 个字节来表示 1 个字符。
- 不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准
属性
- 是编码
- 也是存储(WIN可以直接按照ANSI存储)
占用字节、位
- 每个ANSI占用2个字节(16bits)
现状
- ANSI码仅在前128(0-127)个与ASCII码相同,之后的字符全是某个国家语言的所有字符,中国则是GB2312;日本是Shift-jls,各国扩展各不相同
优缺点
- 除了前128个字符,其他导致在多语言混合的文本中会有乱码
- 不利于互联网时代发展需求,于是,又产生了unicode
GBK、GB2312 编码
GBK全称《汉字内码扩展规范》
定义
- GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。
属性
- 是编码(中文编码)
- 不是存储,存储依赖ANSI
占用字节、位
- 占用2个字节(16bits)
现状
- 其实就是一种一一对应汉字的编号方式,不能国际通用
存储方式

- 没有特殊的头部信息
- “你好IT” 汉字每个占两字节,字符占一字节
unicode 编码
Unicode :通用字符集(Universal Character Set, UCS)
定义
- 是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
- Unicode和UCS合并,对于码空间,两者同意以一百一十万为限(即两者都认为虽然65536不够,但2的31次方又太大,一百一十万是个双方都可接受的码空间大小;
- 现在再讲Unicode只包含65536个字符是不对的。除了对已经定义的字符进行统一外,Unicode联盟与ISO工作组也同意今后任何的扩展工作两者均保持同步,因此虽然从历史的意义上讲Unicode与UCS不是一回事(甚至细节上说也不是一回事),但现在提起Unicode,指代两者均无不妥;
属性
-
是编码
-
是存储 (很多文本工具可选择 unicode 存储)
-
码点
- 一个字符集一般可以用一张或多张由多个行和多个列所构成的二维表来表示
- 二维表中行与列相交的点,称之为码点(Code Point代码点),也称之为码位(Code position代码位);
- 除开非字符码点和保留码点,码点值(即码点编号)通常来说就是其所对应的字符的编号,所以码点值有时也可以直接称之为字符编号,虽然不够准确,但更为直接
-
编码空间
- 字符集中所有码点数量的总和,称之为编号空间
-
码点范围
- 码点值最初用两个字节的十六进制数字表示,比如字母A的Unicode码点值为0041,常写作U+0041,这种形式称为Unicode码点名称
- 后来随着Unicode字符集的不断增补扩大(比如现在的Unicode字符集至少需要21位才能全部表示),码点值也扩展为用三个字节或以上的十六进制数字表示
- 将字符按照一定的类别划分到0~16这17个平面(Plane层面)中,每个平面中拥有2^16 = 65536个码点,因此,目前Unicode字符集所拥有的码点总数,也就是Unicode的编号空间为17×65536=1114112

- BMP官网
- BMP表
- 两字节码点[0xABCD] A. 默认0,B.表位,C.行号,D.列号
占用字节、位
- 对于BMP部分,每个码点占用两字节(16位)
- 另外部分大于2字节
存储方式

- FF FE 标示小头序存储 (反过来标示大头)
- ‘你好IT’ 四个字符占八个字节
现状
- 由于Unicode字符集非常大,有些字符的编号(码点值)需要两个或两个以上字节来表示,而要对这样的编号进行编码,也必须使用两个或两个以上字节;
问题点
1.如何才能区别Unicode字符和ASCII字符的编码?计算机怎么知道三个字节表示的是一个字符,而不是分别表示三个字符呢?
2.我们知道,英文字母只用一个字节来编码就够了,而如果Unicode统一硬性规定,每个字符都用两个、三个或四个字节来编码,那么每个英文字母编码的前面都必然有一个、两个到三个字节全是0,这对于存储和传输来说是极大的浪费。
3. 至此,UTF编码应运而生,旨在解决过长编码问题,使通讯更国际化。
UTF编码
(Unicode Transformation Format)是一种针对Unicode的可变长度字符编码
包含 UTF-8、UTF-16、UTF-32
定义
- UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
- 其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用
属性
- 是编码
- 也是存储
占用字节、位
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------±--------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
举个栗子
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
1.
严的 Unicode 是4E25(100111000100101),
根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),
因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。
然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。
这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,
转换成十六进制就是E4B8A5
你(unicode= 4F 60 )二进制 0100111101100000
放入 1110xxxx 10xxxxxx 10xxxxxx
得到 11100100 10111101 10100000

存储方式

- 有三字节的头,标示UTF-8文件格式
- 汉字一般为三字节(依赖汉字的unicode码点值),字符一定为一字节

















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}