







需求:hive里面对数据进行行处理,删除重复项
思路:1、根据指定的一个字段,将数据分类查询,并添加记录数做标记
2、保留下标为1的记录
拓展:1、去除多个字段重复项
2、保留下标最大的那条记录
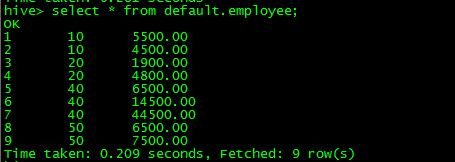
步骤:假设有如下数据 employee(empid,deptid,salary)
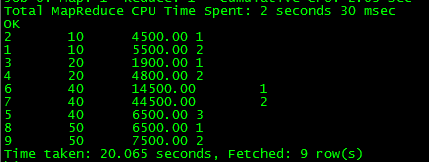
(1)先根据deptid 分组,在分组内部根据 salary排序,查询结果rank为每组排序后的顺序编号
select *,row_number() over (partition by deptid order by salary) rank from employee;
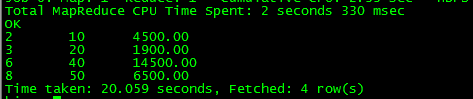
(2)匹配rank=1的记录,得出结果
select empid,deptid,salary from (select *,row_number() over (partition by deptid order by salary) rank from employee) d where d.rank = 1















 6万+
6万+
评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








