






目录
E-Permutation Minimization by Deque
A-Casimir's String Solitaire
Casimir has a string ss which consists of capital Latin letters 'A', 'B', and 'C' only. Each turn he can choose to do one of the two following actions:
- he can either erase exactly one letter 'A' and exactly one letter 'B' from arbitrary places of the string (these letters don't have to be adjacent);
- or he can erase exactly one letter 'B' and exactly one letter 'C' from arbitrary places in the string (these letters don't have to be adjacent).
Therefore, each turn the length of the string is decreased exactly by 22. All turns are independent so for each turn, Casimir can choose any of two possible actions.
For example, with ss == "ABCABC" he can obtain a string ss == "ACBC" in one turn (by erasing the first occurrence of 'B' and the second occurrence of 'A'). There are also many other options for a turn aside from this particular example.
For a given string ss determine whether there is a sequence of actions leading to an empty string. In other words, Casimir's goal is to erase all letters from the string. Is there a way to do this?
Input
The first line contains an integer tt (1≤t≤10001≤t≤1000) — the number of test cases.
Each test case is described by one string ss, for which you need to determine if it can be fully erased by some sequence of turns. The string ss consists of capital letters 'A', 'B', 'C' and has a length from 11 to 5050 letters, inclusive.
Output
Print tt lines, each line containing the answer to the corresponding test case. The answer to a test case should be YES if there is a way to fully erase the corresponding string and NO otherwise.
You may print every letter in any case you want (so, for example, the strings yEs, yes, Yes, and YES will all be recognized as positive answers).
Example
Input
6 ABACAB ABBA AC ABC CABCBB BCBCBCBCBCBCBCBC
Output
NO YES NO NO YES YES
题意:
Casimir有一个字符串s,只由大写的拉丁字母“A”、“B”和“C”组成。每个回合他可以选择以下两种行动中的一种:
他可以从字符串的任意位置上精确地擦除一个字母“A”和一个字母“B”(这些字母不必相邻);
或者他可以从字符串任意位置上精确地删除一个字母“B”和一个字母“C”(这些字母不必相邻)。
因此,每转一圈,绳子的长度就减少2。所有回合都是独立的,所以在每个回合中,Casimir可以选择两种可能的行动中的任何一种。
例如,使用s = "ABCABC",他可以在一次循环中获得一个字符串s = "ACBC"(通过删除第一次出现的'B'和第二次出现的' a ')。除了这个例子之外,还有许多其他的选择。
对于给定的字符串,s确定是否存在导致空字符串的操作序列。换句话说,卡西米尔的目标是删除字符串中的所有字母。有办法做到吗?
思路:水题,判断A和C的数量相加是否等于B的数量即可
代码:
#include<iostream>
#include<string>
using namespace std;
int main()
{
int t;
cin>>t;
while(t--)
{
string s;
cin>>s;
int a=0,b=0,c=0;
for(int i=0;i<s.length();i++)
{
if(s[i]=='A')
a+=1;
else if(s[i]=='B')
b+=1;
else if(s[i]=='C')
c+=1;
}
if(a+c==b)
cout<<"YES"<<endl;
else
cout<<"NO"<<endl;
}
}B-Shifting Sort
The new generation external memory contains an array of integers a[1…n]=[a1,a2,…,an]a[1…n]=[a1,a2,…,an].
This type of memory does not support changing the value of an arbitrary element. Instead, it allows you to cut out any segment of the given array, cyclically shift (rotate) it by any offset and insert it back into the same place.
Technically, each cyclic shift consists of two consecutive actions:
- You may select arbitrary indices ll and rr (1≤l<r≤n1≤l<r≤n) as the boundaries of the segment.
- Then you replace the segment a[l…r]a[l…r] with it's cyclic shift to the left by an arbitrary offset dd. The concept of a cyclic shift can be also explained by following relations: the sequence [1,4,1,3][1,4,1,3] is a cyclic shift of the sequence [3,1,4,1][3,1,4,1] to the left by the offset 11 and the sequence [4,1,3,1][4,1,3,1] is a cyclic shift of the sequence [3,1,4,1][3,1,4,1] to the left by the offset 22.
For example, if a=[1,3,2,8,5]a=[1,3,2,8,5], then choosing l=2l=2, r=4r=4 and d=2d=2 yields a segment a[2…4]=[3,2,8]a[2…4]=[3,2,8]. This segment is then shifted by the offset d=2d=2 to the left, and you get a segment [8,3,2][8,3,2] which then takes the place of of the original elements of the segment. In the end you get a=[1,8,3,2,5]a=[1,8,3,2,5].
Sort the given array aa using no more than nn cyclic shifts of any of its segments. Note that you don't need to minimize the number of cyclic shifts. Any method that requires nn or less cyclic shifts will be accepted.
Input
The first line contains an integer tt (1≤t≤10001≤t≤1000) — the number of test cases.
The next 2t2t lines contain the descriptions of the test cases.
The first line of each test case description contains an integer nn (2≤n≤502≤n≤50) — the length of the array. The second line consists of space-separated elements of the array aiai (−109≤ai≤109−109≤ai≤109). Elements of array aa may repeat and don't have to be unique.
Output
Print tt answers to all input test cases.
The first line of the answer of each test case should contain an integer kk (0≤k≤n0≤k≤n) — the number of actions to sort the array. The next kk lines should contain descriptions of the actions formatted as "ll rr dd" (without quotes) where ll and rr (1≤l<r≤n1≤l<r≤n) are the boundaries of the segment being shifted, while dd (1≤d≤r−l1≤d≤r−l) is the offset value. Please remember that only the cyclic shifts to the left are considered so the chosen segment will be shifted by the offset dd to the to the left.
Note that you are not required to find the minimum number of cyclic shifts needed for sorting. Any sorting method where the number of shifts does not exceed nn will be accepted.
If the given array aa is already sorted, one of the possible answers is k=0k=0 and an empty sequence of cyclic shifts.
If there are several possible answers, you may print any of them.
Example
Input
4 2 2 1 3 1 2 1 4 2 4 1 3 5 2 5 1 4 3
Output
1 1 2 1 1 1 3 2 3 2 4 1 2 3 1 1 3 2 4 2 4 2 1 5 3 1 2 1 1 3 1
Note
Explanation of the fourth data set in the example:
- The segment a[2…4]a[2…4] is selected and is shifted to the left by 22: [2,5,1,4,3]⟶[2,4,5,1,3][2,5,1,4,3]⟶[2,4,5,1,3]
- The segment a[1…5]a[1…5] is then selected and is shifted to the left by 33: [2,4,5,1,3]⟶[1,3,2,4,5][2,4,5,1,3]⟶[1,3,2,4,5]
- After that the segment a[1…2]a[1…2] is selected and is shifted to the left by 11: [1,3,2,4,5]⟶[3,1,2,4,5][1,3,2,4,5]⟶[3,1,2,4,5]
- And in the end the segment a[1…3]a[1…3] is selected and is shifted to the left by 11: [3,1,2,4,5]⟶[1,2,3,4,5]
题意:
给你一个长度为n的数组,通过一定的规则在n次内将它变成单调递增的,规则为:每一次可以选取一个区间在区间内左移若干位
例如:数组5 2 4 3 1将区间2~4中的数全部左移一位变成5 4 3 2 1
思路:
1~n 将最小的左移到第一位
2~n 将最小的左移到第二位
...
可以先用另一个容器排序得到排完序的结果,省去找最小数的过程。
代码:
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
using namespace std;
struct point
{
int l,r,x;
point(int a,int b,int c):l(a),r(b),x(c){}
};
int main()
{
int t;
cin>>t;
while(t--)
{
vector<int>ve0;
vector<int>ve1;
int n;
cin>>n;
for(int i=0;i<n;i++)
{
int p;
cin>>p;
ve0.push_back(p);
ve1.push_back(p);
}
sort(ve1.begin(),ve1.end());
int k=0;
vector<point> ve;
for(int i=0;i<n;i++)
{
if(ve0[i]!=ve1[i])
{
k++;
vector<int>ve2;
for(int j=0;j<i;j++)
{
ve2.push_back(ve0[j]);
}
int now;
for(int j=i;j<n;j++)
{
if(ve0[j]==ve1[i])
{
now=j;
break;
}
}
ve.push_back(point(i+1,n,now-i));
for(int j=now;j<n;j++)
{
ve2.push_back(ve0[j]);
}
for(int j=i;j<now;j++)
{
ve2.push_back(ve0[j]);
}
ve0=ve2;
}
}
cout<<k<<endl;
for(int i=0;i<ve.size();i++)
{
cout<<ve[i].l<<" "<<ve[i].r<<" "<<ve[i].x<<endl;
}
}
}C-Ticks
Casimir has a rectangular piece of paper with a checkered field of size n×mn×m. Initially, all cells of the field are white.
Let us denote the cell with coordinates ii vertically and jj horizontally by (i,j)(i,j). The upper left cell will be referred to as (1,1)(1,1) and the lower right cell as (n,m)(n,m).
Casimir draws ticks of different sizes on the field. A tick of size dd (d>0d>0) with its center in cell (i,j)(i,j) is drawn as follows:
- First, the center cell (i,j)(i,j) is painted black.
- Then exactly dd cells on the top-left diagonally to the center and exactly dd cells on the top-right diagonally to the center are also painted black.
- That is all the cells with coordinates (i−h,j±h)(i−h,j±h) for all hh between 00 and dd are painted. In particular, a tick consists of 2d+12d+1 black cells.
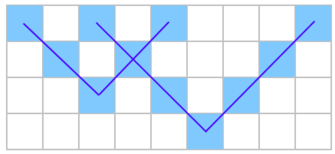
An already painted cell will remain black if painted again. Below you can find an example of the 4×94×9 box, with two ticks of sizes 22 and 33.
You are given a description of a checkered field of size n×mn×m. Casimir claims that this field came about after he drew some (possibly 00) ticks on it. The ticks could be of different sizes, but the size of each tick is at least kk (that is, d≥kd≥k for all the ticks).
Determine whether this field can indeed be obtained by drawing some (possibly none) ticks of sizes d≥kd≥k or not.
Input
The first line contains an integer tt (1≤t≤1001≤t≤100) — the number test cases.
The following lines contain the descriptions of the test cases.
The first line of the test case description contains the integers nn, mm, and kk (1≤k≤n≤101≤k≤n≤10; 1≤m≤191≤m≤19) — the field size and the minimum size of the ticks that Casimir drew. The following nn lines describe the field: each line consists of mm characters either being '.' if the corresponding cell is not yet painted or '*' otherwise.
Output
Print tt lines, each line containing the answer to the corresponding test case. The answer to a test case should be YES if the given field can be obtained by drawing ticks of at least the given size and NO otherwise.
You may print every letter in any case you want (so, for example, the strings yEs, yes, Yes, and YES will all be recognized as positive answers).
Example
Input
8 2 3 1 *.* ... 4 9 2 *.*.*...* .*.*...*. ..*.*.*.. .....*... 4 4 1 *.*. **** .**. .... 5 5 1 ..... *...* .*.*. ..*.* ...*. 5 5 2 ..... *...* .*.*. ..*.* ...*. 4 7 1 *.....* .....*. ..*.*.. ...*... 3 3 1 *** *** *** 3 5 1 *...* .***. .**..
Output
NO YES YES YES NO NO NO NO
Note
The first sample test case consists of two asterisks neither of which can be independent ticks since ticks of size 00 don't exist.
The second sample test case is already described in the statement (check the picture in the statement). This field can be obtained by drawing ticks of sizes 22 and 33, as shown in the figure.
The field in the third sample test case corresponds to three ticks of size 11. Their center cells are marked with blueblue, redred and greengreen colors:
| *.*. |
| ***** |
| .****. |
| .... |
The field in the fourth sample test case could have been obtained by drawing two ticks of sizes 11 and 22. Their vertices are marked below with blueblue and redred colors respectively:
| ..... |
| *...* |
| .*.*. |
| ..**.* |
| ...**. |
The field in the fifth sample test case can not be obtained because k=2k=2, and the last asterisk in the fourth row from the top with coordinates (4,5)(4,5) can only be a part of a tick of size 11.
The field in the sixth sample test case can not be obtained because the top left asterisk (1,1)(1,1) can't be an independent tick, since the sizes of the ticks must be positive, and cannot be part of a tick with the center cell in the last row, since it is separated from it by a gap (a point, '.') in (2,2)(2,2).
In the seventh sample test case, similarly, the field can not be obtained by the described process because the asterisks with coordinates (1,2)(1,2) (second cell in the first row), (3,1)(3,1) and (3,3)(3,3) (leftmost and rightmost cells in the bottom) can not be parts of any ticks.
题意:
在nxm的格子中,画√,一个√有两个参数,顶点(i,j)和高度h,即从(i,j)出发左上角h个格子和右上角h个格子构成一个√,输入n,m,k以及nxm个格子,‘*’表示格子被涂了,‘.’表示格子空白,问这些被涂的格子是否可以全部由若干个h>=k的√得到,重复涂抹也ok
思路:
建立两个二维数组,一个来装格子,一个标记被涂抹的格子是否由√得到,然后以每一个’*‘为顶点先判断能否形成一个h==k的√,如果可以就标记可以形成最大√的所有’*‘;最后看所有的’*‘是否都被标记了。
代码:
#include<iostream>
#include<algorithm>
#include<cstring>
#include<vector>
using namespace std;
typedef long long ll;
char a[100][100];
int v[100][100];
int main()
{
int t;
cin>>t;
while(t--)
{
memset(v,0,sizeof(v));
int n,m,k;
cin>>n>>m>>k;
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
cin>>a[i][j];
}
}
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
if(i>=k && j>=k && m-1-j>=k && a[i][j]=='*')
{
int flag=1;
for(int h=0;h<=k;h++)
{
if(a[i-h][j-h]=='.' || a[i-h][j+h]=='.')
{
flag=0;
break;
}
}
if(flag==0)
continue;
int maxh=min(i,j);
maxh=min(maxh,m-1-j);
for(int h=0;h<=maxh;h++)
{
if(a[i-h][j-h]=='*' && a[i-h][j+h]=='*')
{
v[i-h][j-h]=1;
v[i-h][j+h]=1;
}
else
break;
}
}
}
}
int ans=1;
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
if(a[i][j]=='*' && v[i][j]==0)
{
cout<<"NO"<<endl;
ans=0;
break;
}
}
if(ans==0)
break;
}
if(ans==1)
cout<<"YES"<<endl;
}
}
E-Permutation Minimization by Deque
In fact, the problems E1 and E2 do not have much in common. You should probably think of them as two separate problems.
A permutation pp of size nn is given. A permutation of size nn is an array of size nn in which each integer from 11 to nn occurs exactly once. For example, [1,4,3,2][1,4,3,2] and [4,2,1,3][4,2,1,3] are correct permutations while [1,2,4][1,2,4] and [1,2,2][1,2,2] are not.
Let us consider an empty deque (double-ended queue). A deque is a data structure that supports adding elements to both the beginning and the end. So, if there are elements [1,5,2][1,5,2] currently in the deque, adding an element 44 to the beginning will produce the sequence [4,1,5,2][4,1,5,2], and adding same element to the end will produce [1,5,2,4][1,5,2,4].
The elements of the permutation are sequentially added to the initially empty deque, starting with p1p1 and finishing with pnpn. Before adding each element to the deque, you may choose whether to add it to the beginning or the end.
For example, if we consider a permutation p=[3,1,2,4]p=[3,1,2,4], one of the possible sequences of actions looks like this:
| 1. | add 33 to the end of the deque: | deque has a sequence [3][3] in it; |
| 2. | add 11 to the beginning of the deque: | deque has a sequence [1,3][1,3] in it; |
| 3. | add 22 to the end of the deque: | deque has a sequence [1,3,2][1,3,2] in it; |
| 4. | add 44 to the end of the deque: | deque has a sequence [1,3,2,4][1,3,2,4] in it; |
Find the lexicographically smallest possible sequence of elements in the deque after the entire permutation has been processed.
A sequence [x1,x2,…,xn][x1,x2,…,xn] is lexicographically smaller than the sequence [y1,y2,…,yn][y1,y2,…,yn] if there exists such i≤ni≤n that x1=y1x1=y1, x2=y2x2=y2, ……, xi−1=yi−1xi−1=yi−1 and xi<yixi<yi. In other words, if the sequences xx and yy have some (possibly empty) matching prefix, and the next element of the sequence xx is strictly smaller than the corresponding element of the sequence yy. For example, the sequence [1,3,2,4][1,3,2,4] is smaller than the sequence [1,3,4,2][1,3,4,2] because after the two matching elements [1,3][1,3] in the start the first sequence has an element 22 which is smaller than the corresponding element 44 in the second sequence.
Input
The first line contains an integer tt (1≤t≤10001≤t≤1000) — the number of test cases.
The next 2t2t lines contain descriptions of the test cases.
The first line of each test case description contains an integer nn (1≤n≤2⋅1051≤n≤2⋅105) — permutation size. The second line of the description contains nn space-separated integers pipi (1≤pi≤n1≤pi≤n; all pipi are all unique) — elements of the permutation.
It is guaranteed that the sum of nn over all test cases does not exceed 2⋅1052⋅105.
Output
Print tt lines, each line containing the answer to the corresponding test case. The answer to a test case should contain nn space-separated integer numbers — the elements of the lexicographically smallest permutation that is possible to find in the deque after executing the described algorithm.
Example
Input
5 4 3 1 2 4 3 3 2 1 3 3 1 2 2 1 2 2 2 1
Output
1 3 2 4 1 2 3 1 3 2 1 2 1 2
Note
One of the ways to get a lexicographically smallest permutation [1,3,2,4][1,3,2,4] from the permutation [3,1,2,4][3,1,2,4] (the first sample test case) is described in the problem statement.
题意:
输入n个数,按照输入顺序根据双端队列的插入规则使得字典序最小
思路:
每次输入的时候和第一个数比大小,如果比第一个数小就从左边插入,大就从右边插入
代码:
#include<iostream>
#include<string>
#include<vector>
#include<deque>
using namespace std;
int main()
{
int t;
cin>>t;
while(t--)
{
int n;
cin>>n;
deque<int> dq;
for(int i=0;i<n;i++)
{
int a;
cin>>a;
if(dq.empty())
{
dq.push_front(a);
}
else
{
if(a<dq[0])
dq.push_front(a);
else if(a>dq[0])
dq.push_back(a);
else
{
if(dq.size()==1)
dq.push_back(a);
else
{
if(dq[0]>a)
dq.push_back(a);
else
dq.push_front(a);
}
}
}
}
for(int i=0;i<dq.size();i++)
{
cout<<dq[i]<<" ";
}
cout<<endl;
}
}















 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









