






入门
快速入门
基础概念
- Elasticsearch是一个基于Lucene的搜索服务器。半结构化的文档型数据库基于RESTful web接口; 它被用作全文检索、结构化搜索、分析以及这三个功能的组合;
- 半结构化意味着他有类似关系数据库的基础概念;
- es的数据模型(元数据)是:index-type-id

- index:索引库就是一个拥有相似特征的文档的集合。索引库名称必须是小写的,不能用下划线开头;一个索引库包含若干索引组,每个索引组对应文档的一个字段;
- type:在索引中对数据进行逻辑分区。不同 types 的文档可能有不同的字段,但最好能够非常相似。(之后只能是_doc类型,即文档类型,不再有type的概念)
- documents:一个文档是一个可被索引的基础信息单元(保存数据)
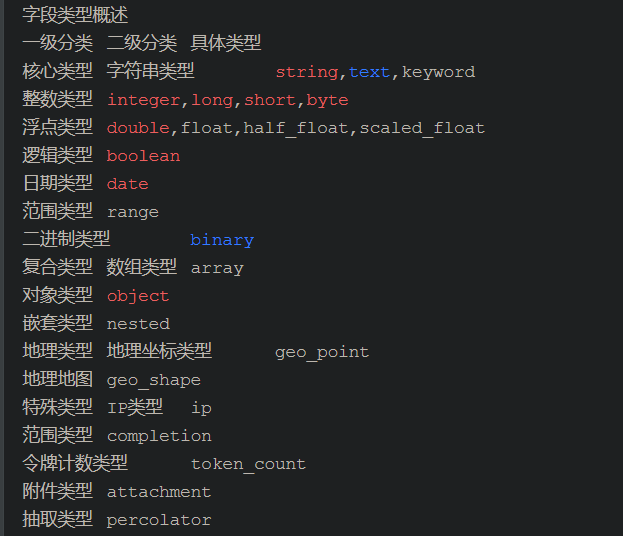
- fields:文档数据的一个字段 ,主要有类型有:
- 字符串类型
- string
- text:自动根据分词器分词
- keyword:关键字,不分词
- 数值类型
- integer、long、short、byte、double、float
- 时间类型
- data
- 对象(数组)
- object、array
- ip
-
- 字符串类型
- es的元数据:
快速使用
- ES通过DSL语句进行操作;
- java通过restFul以http形式进行操作
- Http网址操作;
增删改
-
索引库(index)
-
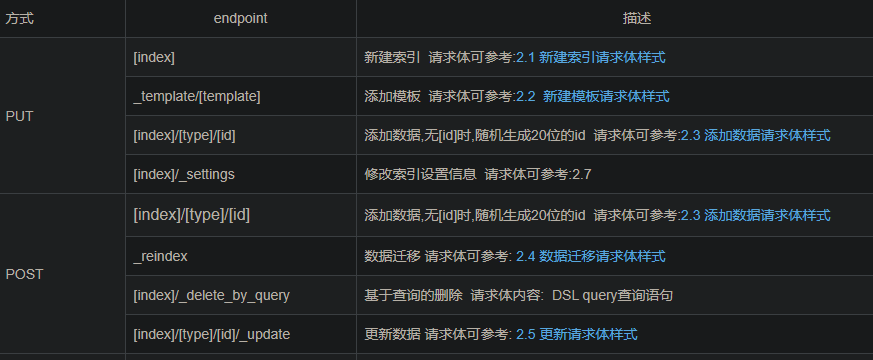
#创建索引库:PUT请求 #下面的node就是es集群中的ip+端口;index就是索引名, <node>/<indexName> #删除索引:DELETE请求 <node>/<indexName>
-
-
文档(documents)
-
#创建documents:POST/PUT请求;POST的请求体必须为JSON格式 #id可以省略,省略时es自动生成id <node>/<indexName>/_doc/<id> #删除:DELETE <node>/<indexName>/_doc/<id> #更新重复和创建一样,当存在该id的文档时则为更新
-
查
- 索引
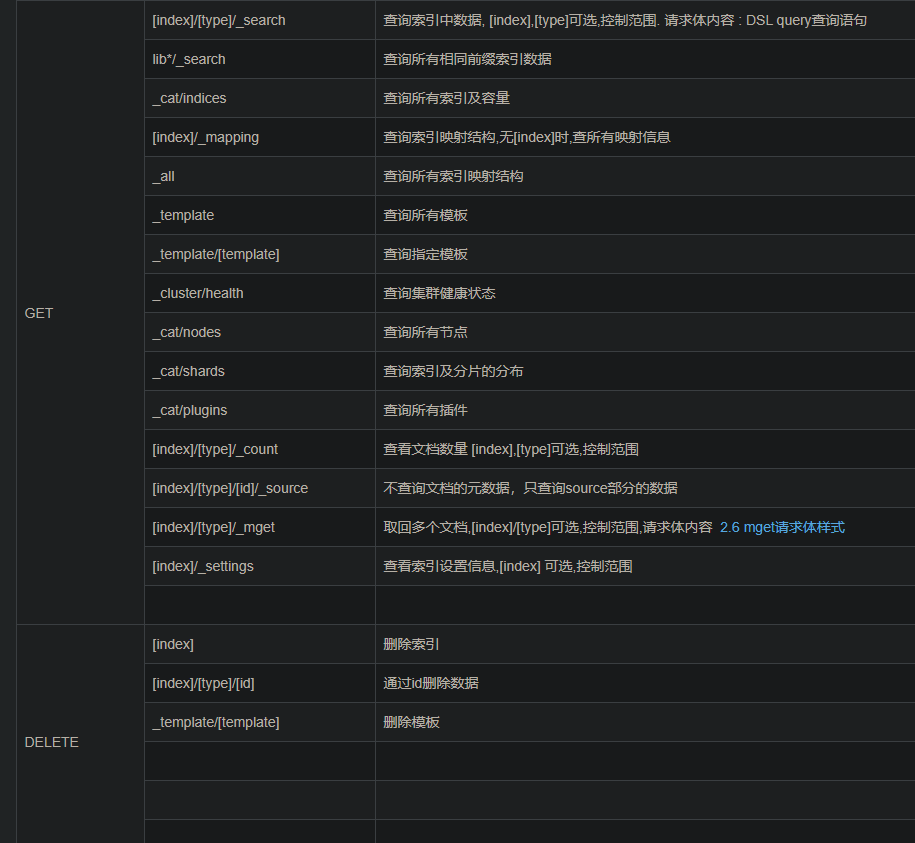
#索引查询:直接GET方式;pretty表示简化返回的JSON,让JSON易读
#获取某一索引
<node>/<indexName>?pretty
#获取全部索引
<node>/_cat/indices?v&pretty
document的查询
- 中文只支持单个单词进行分词,所以需要插件
#URL
<node>/<indexName>/_search?pretty
基础语法(DSL)
- 匹配度查询:query
- 过滤查询:filter
- 选取结果:_sources
- 条件查询:match和term
- match类型
- match:所有匹配的分词
- match_all:空查询(和不带参数查询一样,返回index的全部文档)
- match_phrase:单词查询
- match_phrase_prefix:最左前缀查询
- multi_match:多字段(多个字段查询同一query)
- term:不分词查询(精确查询)
- term:匹配单个词
- terms:匹配(多个中)任意一个词
- bool:合并查询语句
- 多条件同时满足(相当于AND):must
- 多条件只需一个满足(相当于OR):should
- 一定不是:must_not
- match类型
- 分组、排序和分页:
- 分页:from 、size
- 排序:sort
- 分组:ranges
- 运算:
- 数值运算:
- 范围(range),大于(gt)、小于(lt)、大于等于(gte)、小于等于(lte)

- 聚合运算:
- aggs:avg、max、min、sum
- 数值运算:
//假设存在一个index的document,而且有中文分词器,结构为:
//title_id(long),fid(long),ctime(data),context(text)、title(text)、writer(keyword)、tip(keyword)、like(integer)
//即:说说id,发布者id,发布时间、发布内容、作者单位名、标题、标签、点赞数
/**
SELECT
fid,ctime,context,like
FROM
index._doc.document
WHERE
(context LIKE '%震惊%' OR title LIKE '%震惊%')
AND
(
(writer = 'UC新闻部' OR writer = 'UC震惊部')
OR
(like>=100)
)
ORDER BY
like DESC
LIMIT
0,10
*/
//下面语句相当于上面SQL
{
"query":{
"_sources":["fid","ctime","context","like"],
"bool":{
"must":[
"multi_match":{
"query":"震惊"
"fields":["context","title"]
"type": "phrase"
},
"should":{
"terms":{
"writer":["UC新闻部","UC震惊部"]
},
"range":{
"like": {
"gte":100
}
}
}
]
},
"from":0,
"size":10
},
"sort":{
"ctime":{
"order":"desc"
}
}
}
使用
函数库
- ES和MongoDB一样提供了一些快捷函数处理常用的操作
DSL(查询)语言
- 前面介绍了ES的基本操作,下面为了方便记忆介绍DSL语法
query和filter
- filter和query最大的区别是是否进行评分(即匹配度评分)
- query:查询结果不可缓存,计算评分、按评分排序。
- filter : 条件和文档是否匹配。
- 使用query查询语句做全文本搜索或其他需要进行相关性评分的时候,剩下的全部用filter 过滤语句
- 也就是说filter和query都相当于关系数据库的select
query子句
- 和MongoDB的query子句一样:
SpringBoot-ES
索引
- 在学习MongoDB的时候索引模型是 document-index(也就是所谓的正排索引);
- ES则使用index-documents,这种index-document的形式就是倒排索引;
- 倒排索引最大的优先是多文档比较,特别适合用于搜索(一个关键词对应多个文档)
倒排索引
- 特点:不可变
- 优点:
- 不需要加解锁(由于不可变,所以显然是线程安全的);
- 支持高并发;
- 高效io(缺页的时候直接替换,不需要写回)、方便压缩;
- 缺点:每次需要更新,需要重新构建整个索引
- 优点:
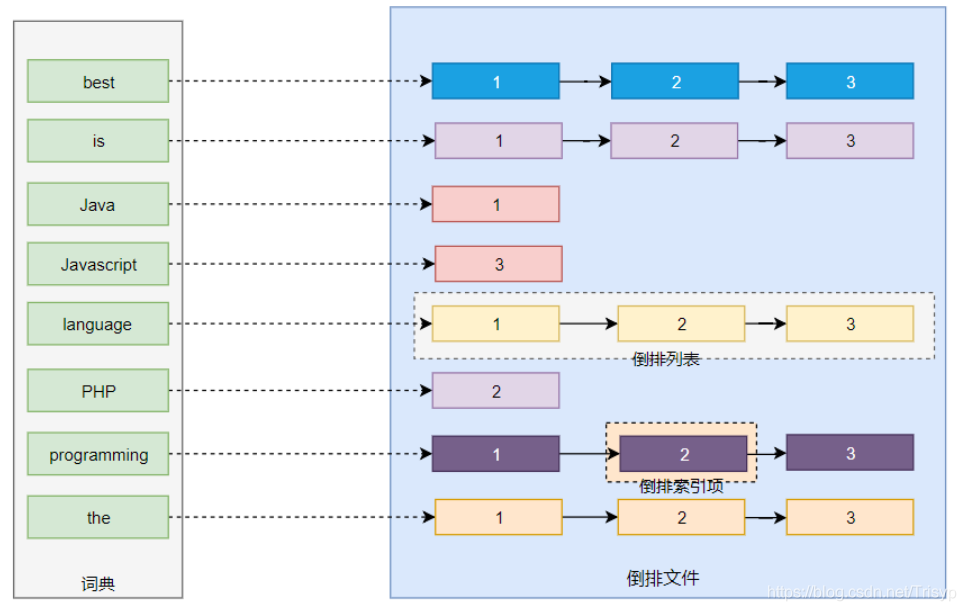
- 结构:
- 字典词根—文档列表节点链
- 文档列表节点一般包括:<文档id>、<出现次数>、<出现位置(行列偏移)>
-
分词
- 分词是建立倒排索引的前提:分词;分词决定了索引能够搜索的数据
- 分词是倒排索引(索引)的关键,分词直接决定了能搜索到的内容
- 英文分词一般只需要通过空格或者标点符号即可,中文分词则相对比较复杂,一般通过字典进行
- 开源的中文分词器:HanIP、IK、结巴等
分词原理
- 前面说过,不同的分词对索引(搜索)有显著影响,所以针对,分词策略决定了索引的精度;
- ES根据用户指定数据类型(分词策略)进行分词;
- 精确匹配(不分词):将整个字段作为一个完整的词,这种情况下(1999-11-11 和1999.11.11)都是不同的;
- 全文分词:根据分词器对文本划分分词;
- 分析分词基本步骤:
- 字符过滤:过滤标签之类的无用符号(例如html标签、图片标签)
- 分词:将文本拆分成词条
- token过滤:token过滤器链,每个过滤器实现特定的过滤功能,例如:大小写转换、去掉无畏的修饰符分词等
- 映射:ES数据类型决定了分词的策略,映射决定了字段数据类型;ES不支持一个字段多个映射类型;(这点和MongoDB不同);
- 特点
- 映射是决定分词策略的关键,ES内置了常用的数据类型的映射;
- ES和MongoDB一样支持动态映射,也可以实现对文档的字段映射进行约束;
- 动态映射:ES对在索引库未出现过的字段自动根据JSON数据类型推动ES数据类型
- 非动态映射(校验器):和MongoDB一样,可以首先设置文档的字段和ES类型的映射关系,插入是自动校验,没有规定的字段进行动态映射
- 严格映射:设置文档的字段和ES类型的映射关系后,不允许出现校验器外的映射关系
- ES映射决定了索引库的分词组,所以字段的映射一旦确定就不能更改;
- 映射类型https://www.cnblogs.com/huangzhoudaxia/articles/14160473.html
- 字符串映射
- keyword:关键字,不进行分词
- text:文本,需要分词
- 数值映射
- Numbers
- 时间映射
- Dates
- 字符串映射
- 特点
映射
-
下面逐一介绍映射的索引处理策略
boost 字段级索引加权,接收浮点型数字,默认值是1.0 ignore_malformed 如果是true,畸形日期会被忽略,如果是false(默认值),畸形日期会抛出异常并丢弃整个文档。 doc_values 定义字段是否应该以列跨度的方式存储到磁盘上,以便于排序、聚合或者脚本。接收true或者false参数。对于不可分词字段,默认值为true。可分词字段不支持这个参数。 include_in_all 字段是否应该包含在_all字段中,接收true或者false值。如果索引被设置为false或者父对象字段设置 include_in_all为false,参数默认为false;在其他情况下,默认值为true。index 决定字段否可以被用户搜索到。接收true或者false,默认为true。 store 决定字段是否应该被存储以及从_source字段分别获取。接收true或者false值。
字符串映射
-
{ analyzer: 分词器类型 }
分词器
- 内置分词器:
-
- ik分词器有两种分词模式:ik_max_word和ik_smart模式。

索引库
- 索引库:是一类文档的集合(或者说类似数据库的表),由于倒排索引,所以表就是索引库,表的字段就是索引库的中文档的分词;
- 索引库的创建:当加入文档的时候,就是在向索引库加入索引;所以,加入文档也就是创建索引;
- 搜索文档:就是在索引库中搜索文档的分词,根据匹配程度得到结果;
基础
- ES是基于分布式产生的下面将先介绍ES实现分布式的核心概念,再介绍ES的单机框架(Lucene);
核心概念
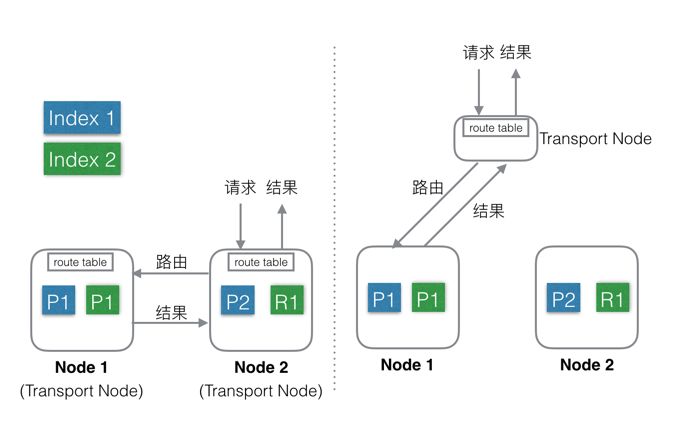
- 节点:存取数据的物理节点(ES运行实例)
- 分片:包括分片算法和分片字段
- 根据分片算法和分片字段将数据划分到某一节点
- 索引(索引库):即倒排索引文件
- 索引保存索引组的mapping和索引数据(即倒排索引文件)
- 副本集:就是节点的分片的数据备份,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致
- 字段:隐式字段和MySQL的字段一样主要用于:1.事务控制、2.分布式
-
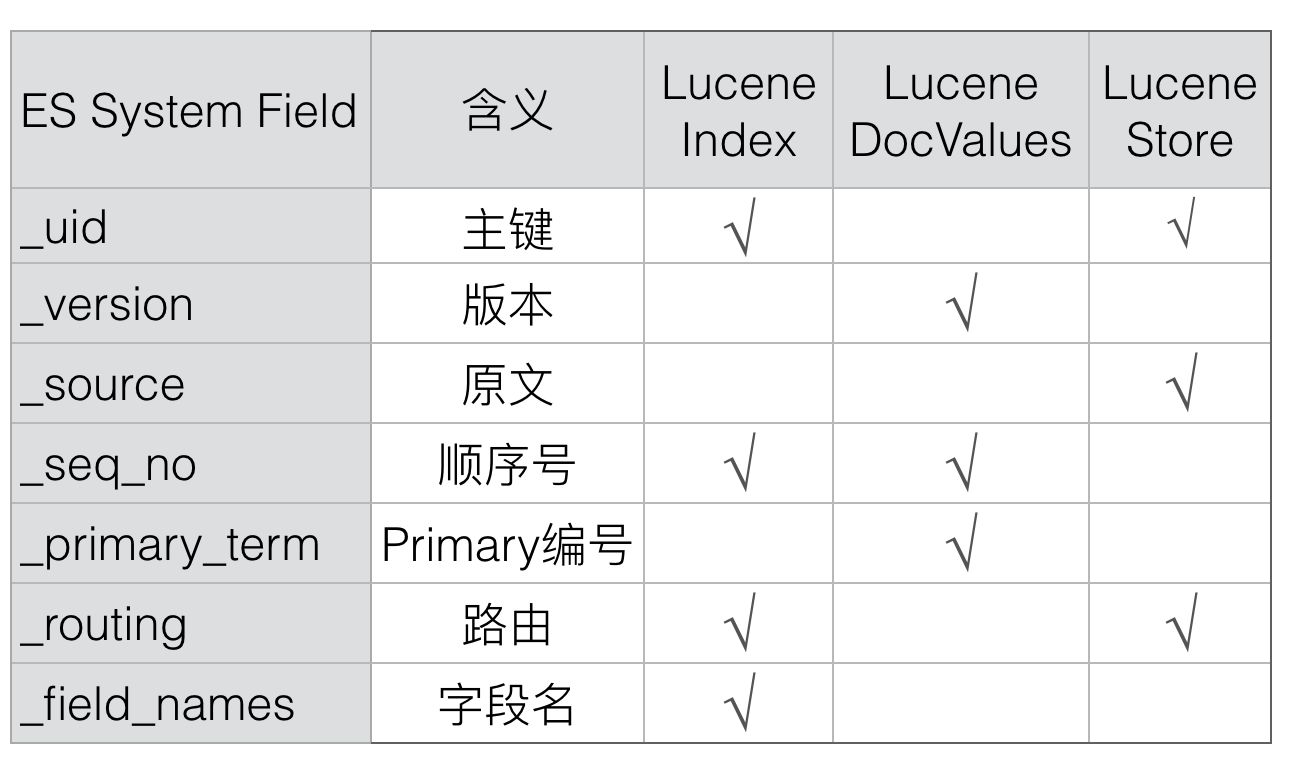
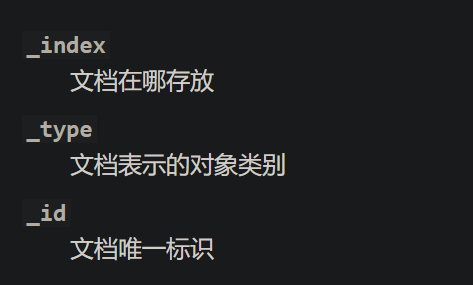
- id:为了区分文档,ES为每个文档设置了一个唯一的id标识(_id),id字段本身不会单独保存,而是通过uid保存
- uid:Elasticsearch中会存储_uid,其中_uid =type + ‘#’ + id(ES后期没有了type的概念,uid就等于id)
- _version:文档数据版本号是实现原子修改的关键(即保证分布式下,文档的修改是顺序的)
- _source:数据原始版本,主要用于数据的修改
- Update:部分更新时,需要从读取文档保存在_source字段中的原文,然后和请求中的部分字段合并为一个完整文档。如果没有_source,则不能完成部分字段的Update操作。
- Rebuild:最新的版本中新增了rebuild接口,可以通过Rebuild API完成索引重建,过程中不需要从其他系统导入全量数据,而是从当前文档的_source中读取。如果没有_source,则不能使用Rebuild API。
- Script:不管是Index还是Search的Script,都可能用到存储在Store中的原始内容,如果禁用了_source,则这部分功能不再可用。
- Summary:摘要信息也是来源于_source字段。
- _seq_no:分片级别(或者说索引库级别)的更改操作的逻辑序列号,保证修改是按顺序进行的
- _primary_term:数据的主节点编号,类似redis的年代(主要用于数据迁移和崩溃恢复时选举主节点)
- _routing:路由规则
- field_name:文档拥有的字段名,用来判断某个Doc中是否存在某个Field,用于exists或者missing请求。
-
Lucene
LSM树
https://zhuanlan.zhihu.com/p/415799237
LSM树的定义:
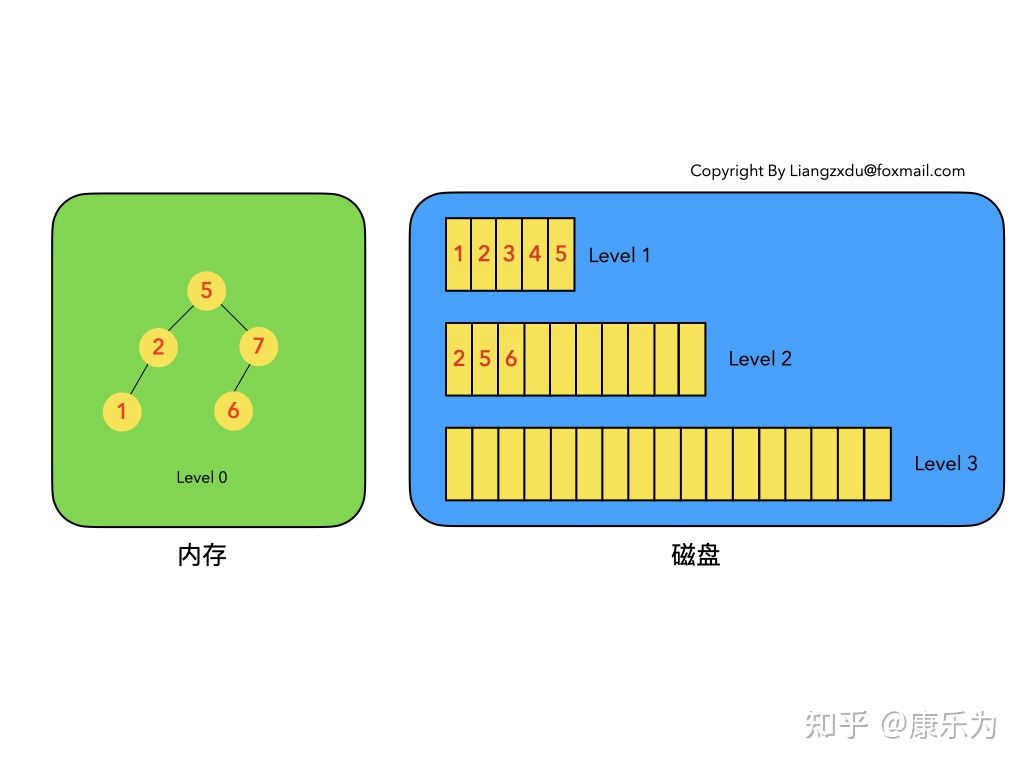
- LSM树是一个横跨内存和磁盘的,包含多颗"子树"的一个森林。
- LSM树分为Level 0,Level 1,Level 2 … Level n 多颗子树,其中只有Level 0在内存中,其余Level 1-n在磁盘中。
- 内存中的Level 0子树一般采用排序树(红黑树/AVL树)、跳表或者TreeMap等这类有序的数据结构,方便后续顺序写磁盘。
- 磁盘中的Level 1-n子树,本质是数据排好序后顺序写到磁盘上的文件,只是叫做树而已。
- 每一层的子树都有一个阈值大小,达到阈值后会进行合并,合并结果写入下一层。
- 只有内存中数据允许原地更新,磁盘上数据的变更只允许追加写,不做原地更新。
特点
- 快速增删改(增删改操作都只在内存进行);
- 较快进行查找(如果数据段控制得好,只需要log(n1*n2*n3*n4……*n)即可遍历整个树;
- 尽可能减少段的数量(使得n1*n2变为n1+n2);但是不能过大,否则不方便读写,且合并时间过长;
- 需要合并,合并规则如下:
- 合并只需合并内存的新段和磁盘中的小段
- 按照归并排序的思想进行合并
- 重复的数据替换、标记删除的数据则保留删除标记;
-
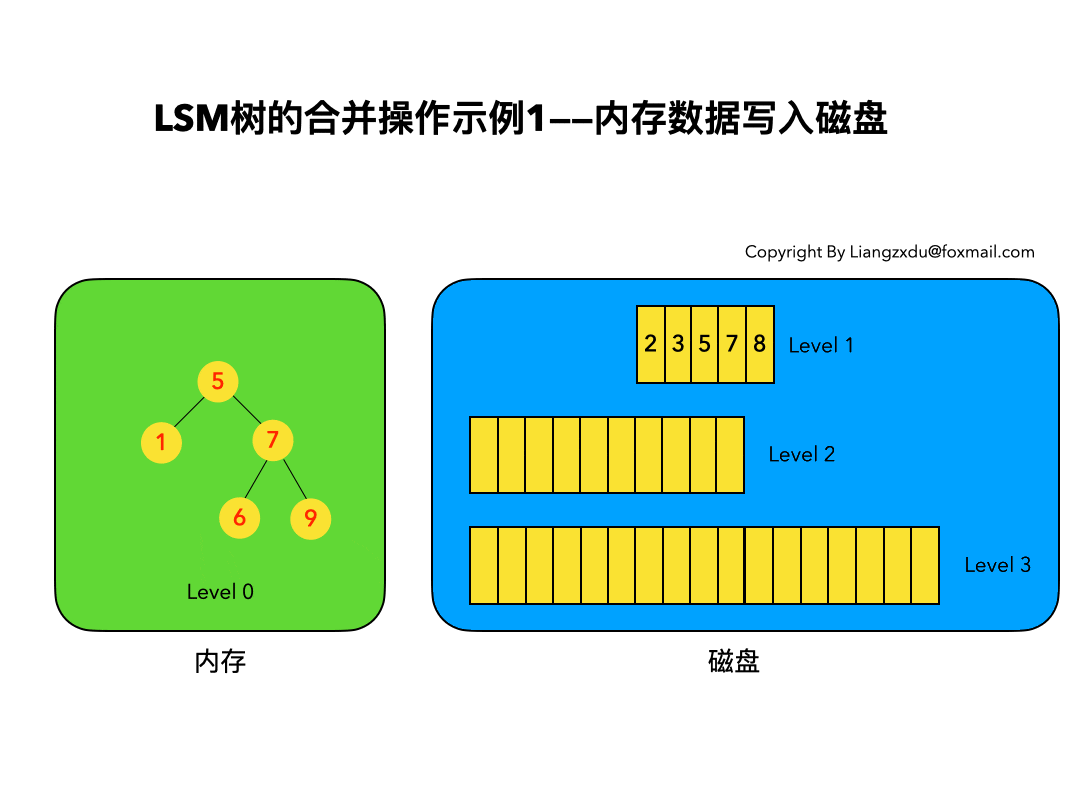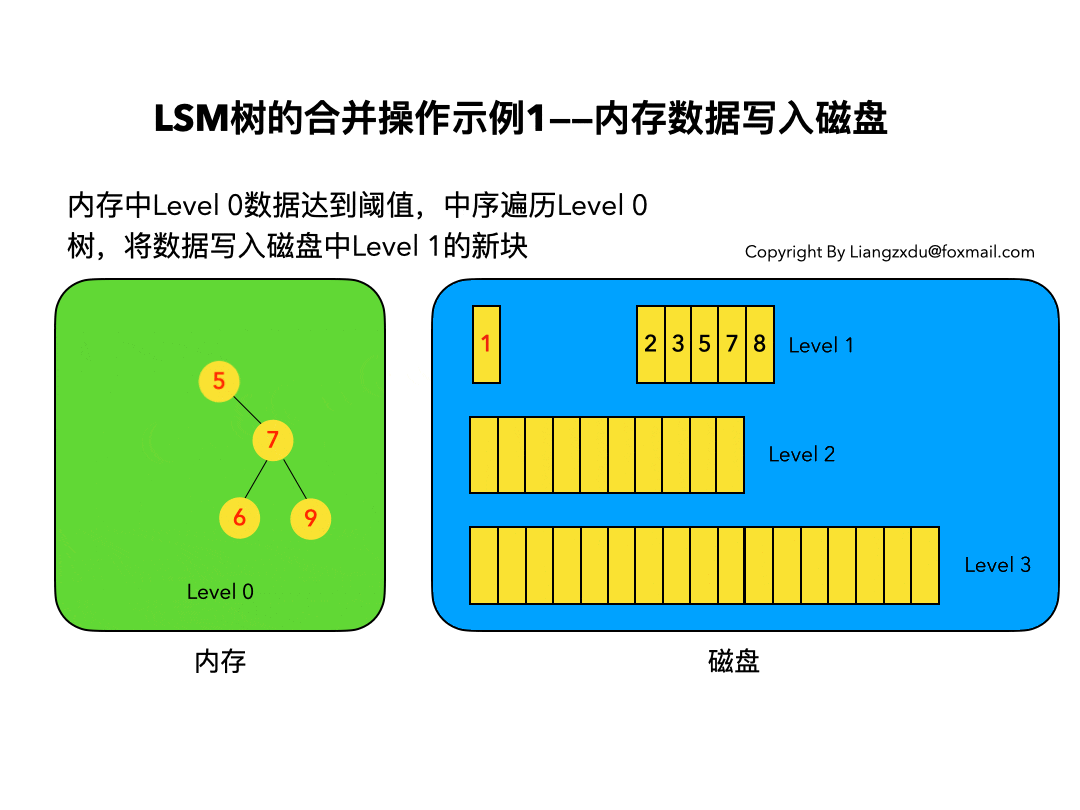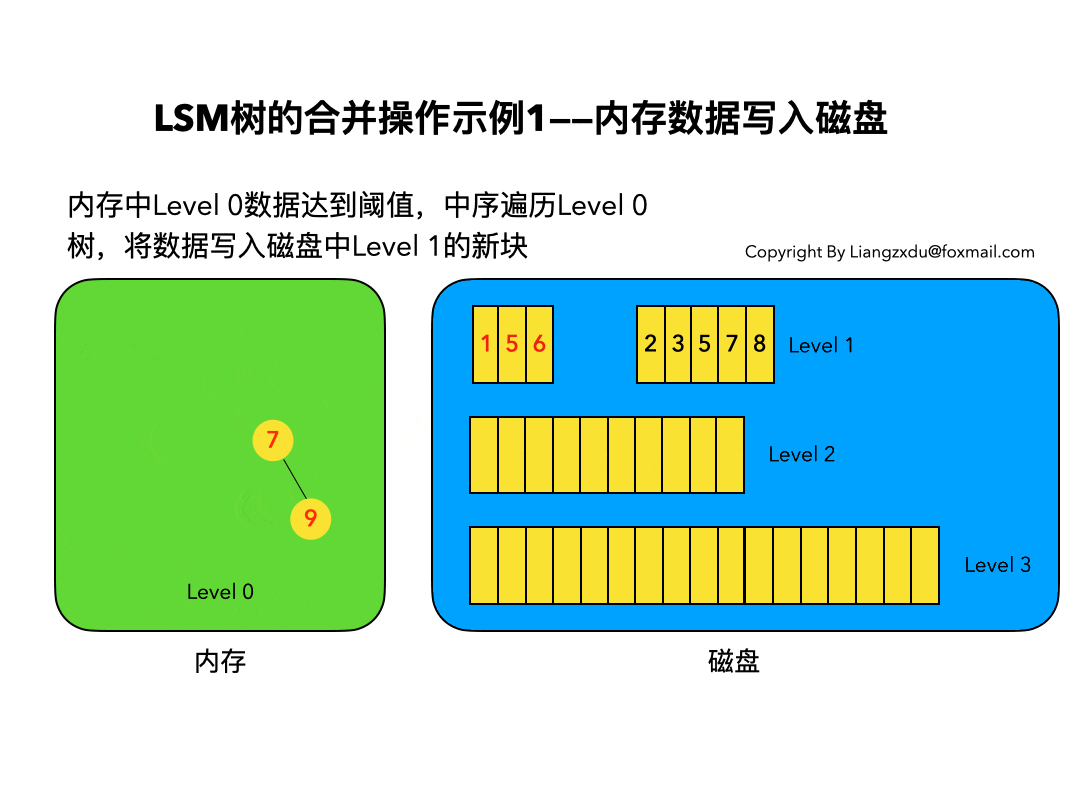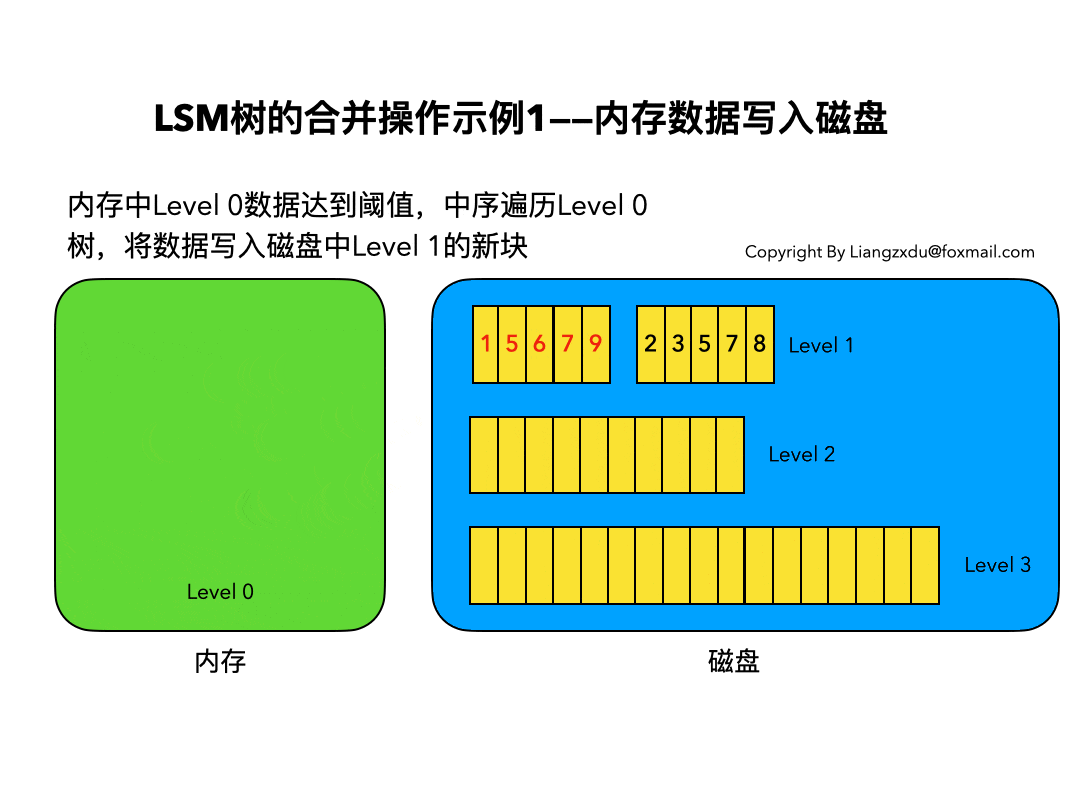
Lucene是apache的开源的单机搜索引擎框架,ES基于其进行分布式开发和NoSQL数据库级别的支持;
Lucene索引的类型
Index:索引库支持是进行数据查询的基础,除了前面说到的倒排索引,Lucene还有key-value类型的正排索引和数据内容存储
-
Invert Index:倒排索引,或者简称Index,通过Term可以查询到拥有该Term的文档。可以配置为是否分词,如果分词可以配置不同的分词器。索引存储的时候有多种存储类型,分别是:
- DOCS:只存储DocID。
- DOCS_AND_FREQS:存储DocID和词频(Term Freq)。
- DOCS_AND_FREQS_AND_POSITIONS:存储DocID、词频(Term Freq)和位置。
- DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:存储DocID、词频(Term Freq)、位置和偏移。
-
DocValues:正排索引,采用列式存储。通过DocID可以快速读取到该Doc的特定字段的值。由于是列式存储,性能会比较好。一般用于sort,agg等需要高频读取Doc字段值的场景。
-
Store:字段原始内容存储,同一篇文章的多个Field的Store会存储在一起,适用于一次读取少量且多个字段内存的场景,比如摘要等。
数据模型
逻辑结构
- 前面介绍了ES和数据库对应的数据模型,下面学习Lucene怎么组织其这部分模型的;
- Index:索引(库):索引库是一个逻辑的概念,索引库包含若干文档和若干term;
- Term和Term Dictionary:
- term:就是通过分词器分词出来的一系列的单词;
- term dictionary:词典,是索引库的term的集合,通过词典查找相应的单词,即可找到相关的文档
- Segment:一个Index会由一个或多个sub-index构成,sub-index被称为Segment。
- 增删改:在内存中进行操作(类似LSM树,但是不允许在其中进行查找),实现快速增删改;
- 查操作:通过倒排索引到磁盘进行(有别于LSM,有效提升读效率);
- 基于id的读操作:通过id的正排索引获取段的位置(然后按照LSM树,先在内存找,再到磁盘找),允许在内存(未落盘的段中)获取;
- Term和Term Dictionary:
- Document:文档,就是实际的数据的组织形式;
- Lucene不支持修改文档:
- 所以ES通过获取原文档,然后合并最后删除原文档,最后插入新文档;
- Lucene不支持文档唯一性(即每次都会创建新文档);
- 所以ES通过增加id字段,并将id作为正排索引,在增删改时都先删除原id文档,再替换操作;
- Lucene不支持修改文档:
- Field:文档由一系列字段组成;Lucene有丰富的映射支持(就是支持多种数据类型),对不同的数据类型支持不同的索引操作;
- Index:索引(库):索引库是一个逻辑的概念,索引库包含若干文档和若干term;
物理模型
https://blog.csdn.net/alex_xfboy/article/details/83052206#6.3%20FST%E5%AD%98%E5%82%A8%E7%BB%93%E6%9E%84
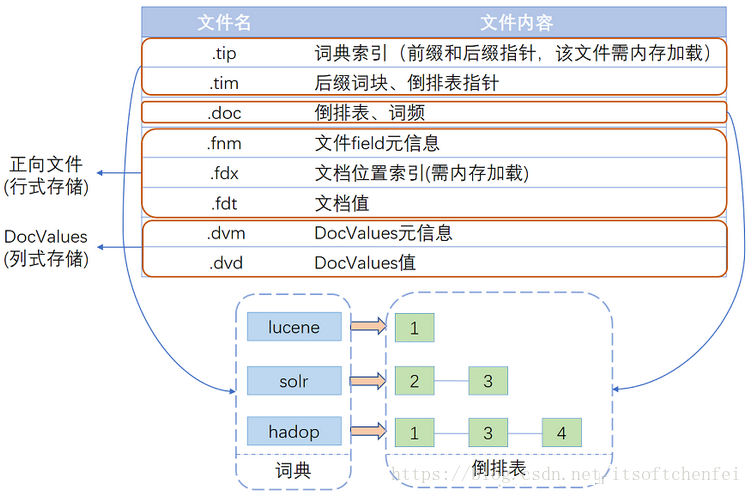
| 名称 | 文件扩展名 | 描述 |
|---|---|---|
| Lock File | write.lock | 锁文件;防止多个IndexWriter同时写到一份索引文件中 |
| frq | 倒排索引表 | |
| 数据文件(segment、field、field data) | 数据文件 | 数据文件 |
| 数据件(term、Term Vector Index等) | 字典文件 | |
Lucene基本结构
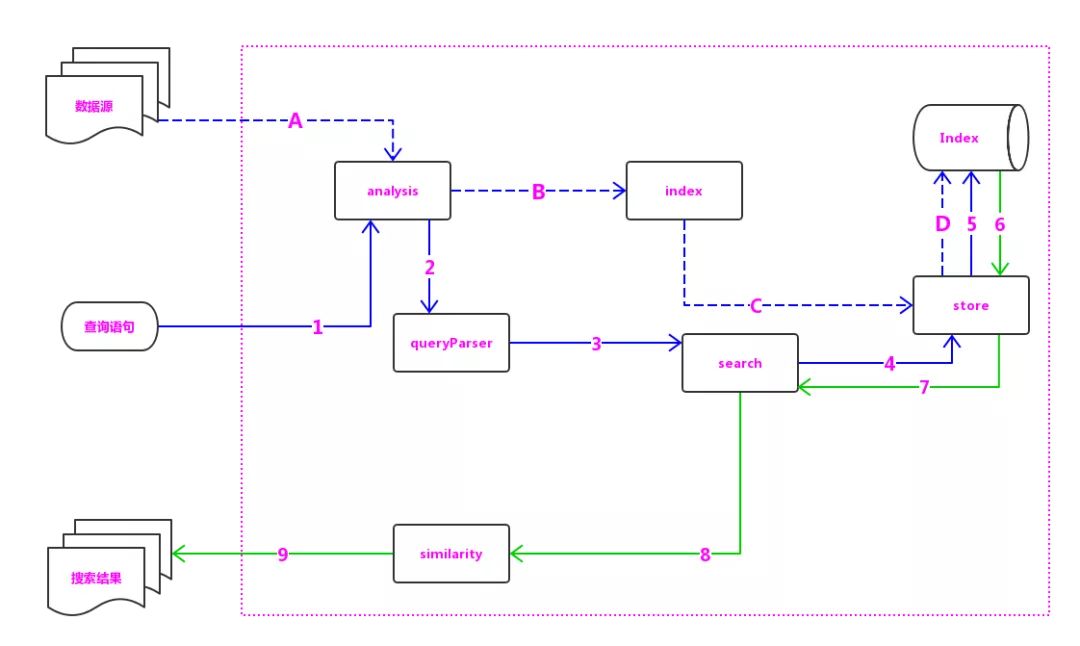
- 分词器(组):将文档的需要分词的字段进行分词
- 索引构建器:创建倒排、正排索引;
- 语法分析器:对查询语句拆分成可执行的语句、优化查询语句;
- store引擎:索引和数据保存到文件系统和在文件系统获取;
- 查询执行器:对索引的搜索工作。
- 评分器:负责相关性打分和排序的实现。
Segment
- Lucene的增删改查都是基于段,段的大小直接影响查询的效率;
- 前面提到Lucene通过模仿LSM树实现快速的增删改;
- 段数据是有序的,段内查询是
log(n),所以索引库查询是log(n0)*log(n1)*……log(nm);所以控制段的数量十分重要,但是段又不能太大(否则不方便读入内存); - Lucene通过合并段减少段的数量,通过控制合并段的大小避免段太大;
读写
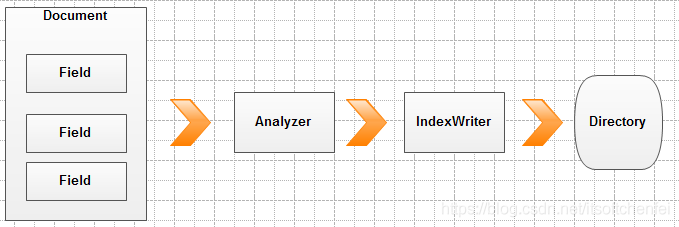
写
Lucene写
- IndexWriter:索引写入
ES写
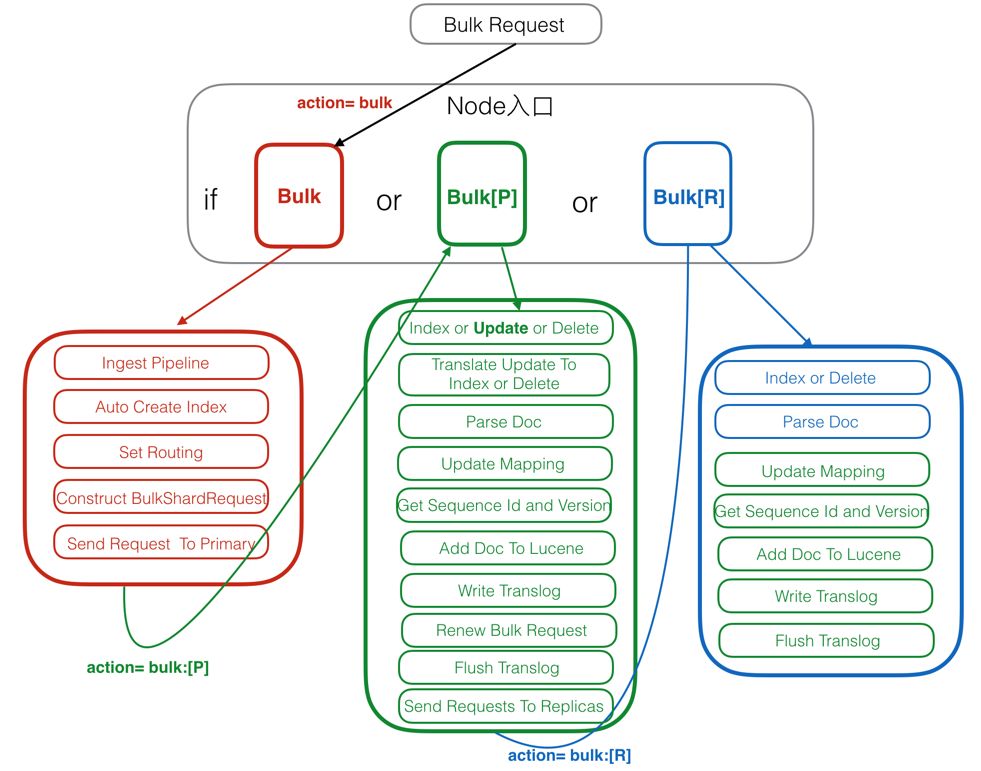
- ES的写入是通过Lucene进行的,但是ES增加了:
- 分片
- 更新
- 路由
















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











