







1.ROCm软件平台
参考:通过 "最差实践 "实验探索 AMD GPU 调度细节(翻译) (qq.com)
本文使用的ROCm(Radeon Open Compute)软件堆栈4.2版本。
在NVIDIA GPU上,术语“CUDA”通常是指GPU编程编译器、API和运行时库,但ROCm不那么单一,通常根据其组件进行描述。图1显示了ROCm中涉及的主要组件堆栈。ROCm的顶部面向用户的组件通常是HIPAPI可移植性接口,它与CUDA几乎相同,主要的实际区别只是API函数的名称。HIP程序中的GPU内核使用LLVM编译器的AMD GPU后端进行编译,并使用ROCclr(ROCm公共语言运行时)运行时库运行。ROCclr下面是一个实现HSA(异构系统架构)API的低级用户空间库,它创建和管理与驱动程序和硬件接口的内存映射队列和命令。
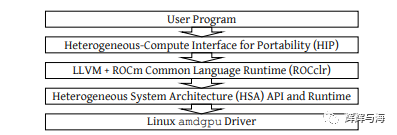
图1 :ROCm 软件栈的组成部分。
2.GPU编程模型
将任务下发到GPU的程序通常使用以下模式(省略分配内存等设置):
-
将输入数据从CPU内存复制到GPU内存.
-
GPU执行一段被称为kernel的GPU代码.
-
等待GPU代码(kernel)执行完毕.
-
将结果数据从GPU内存复制到CPU内存.
从用户空间来看,所有这些步骤都是使用更高级别的API来控制GPU进行的。例如,著名的CUDA API为NVIDIA GPU提供了这种功能。CUDA不支持AMD GPU,因此在本文中我们使用了与CUDA非常相似但适用于AMD的HIP API。还要注意,我们使用术语"kernel"来指代在GPU上运行的代码段(这是GPU文献中常用的术语)。当需要指代操作系统的"kernel code"时,我们使用替代术语,如"driver code"。
3.AMD gpu的计算内核调度
本文将详细说明了kernel如何到达硬件以开始执行。
3.1 调度流程概述
熟悉NVIDIA GPU的读者,应对于了解kernel-launch请求在到达AMD GPU硬件之前经过一系列的过程应该比较熟悉。
图2描述了此请求可能经过的路径。为了帮助简化后面解释的复杂性,首先总结了一个概括性的描述:
-
用户程序调用hipLaunchKernelGGL API函数来启动一个内核。
-
HIP运行时将一个内核启动命令插入由ROCclr运行时库管理的软件队列中。
-
ROCclr将内核启动命令转换为AQL(体系结构队列语言)数据包。
-
ROCclr将AQL数据包插入HSA(异构系统架构)队列中。
-
在硬件中,异步计算引擎(ACE)处理HSA队列,将内核分配给计算硬件。
kernel到达GPU计算硬件的旅程始于hipLaunchKernelGGL API调用,如图2顶部所示,负责将kernel启动请求排入队列。
程序员与队列结构的典型接触点是通过HIP的“流
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









