







杭州深度求索人工智能基础技术研究有限公司(简称“深度求索”或“DeepSeek”),成立于2023年,DeepSeek是一家专注通用人工智能(AGI)的中国科技公司,主攻大模型研发与应用,经营范围包括技术服务、技术开发、软件开发等。
2024年1月5日发布DeepSeek LLM(深度求索的第一个大模型)。
2024年1月25日,发布DeepSeek-Coder。
2024年2月5日,发布DeepSeekMath。
2024年3月11日,发布DeepSeek-VL。
2024年5月7日,发布DeepSeek-V2。
2024年6月17日,发布DeepSeek-Coder-V2。
2024年9月5日,更新 API 支持文档,宣布合并 DeepSeek Coder V2 和 DeepSeek V2 Chat ,推出了 DeepSeek V2.5。
2024年12月13日,发布DeepSeek-VL2。
2024年12月26日,正式上线DeepSeek-V3首个版本并同步开源。
2025年1月31日,英伟达宣布DeepSeek-R1模型登陆NVIDIANIM。同一时段内,亚马逊和微软也接入DeepSeek-R1模型。英伟达称,DeepSeek-R1是最先进的大语言模型。
2025年2月5日,DeepSeek-R1、V3、Coder 等系列模型,已陆续上线国家超算互联网平台。
目录
DeepSeek-R1是其开源的推理模型,擅长处理复杂任务且可免费使用。主要支持联网搜索和深度思考模式。
- 基础模型(V3):通用模型(2024.12),高效便捷,适用于绝大多数任务,适合“规范性”的任务(操作规范清晰、结果有明确要求、按规则执行、稳定可控)。
- 深度思考(R1):推理模型,复杂推理和深度分析任务,适合“开放性”的任务(操作路径开发、对结果没有明确要求、结果多样性、自主决策、不确定性高)。代码编程相关首选。
- 联网搜索:RAG(检索增强生成)。
总结:AI + 国产 + 免费 + 开源 + 强大
1 DeepSeek能做什么?
■ 文本生成
文本创作、摘要与改写、结构化生成(表格、列表生成;代码注释、文档撰写)。
■ 自然语言理解与分析
语义分析、文本分类、知识推理(逻辑问题解答、因果分析)。
■ 编程
代码生成、代码调试、技术文档处理。
■ 绘图
SVG矢量图、Mermaid图表、React图表。
2 DeepSeek的使用
DeepSeek官网:DeepSeek

点击“开始对话”,进入交互页面。
Chat:DeepSeek
在上图中,输入问题,即可获取AI生成的结果。
提示库资料:Prompt Library | DeepSeek API Docs
3 深度理解,更好运用
■ AI缺陷
AI幻觉(AI Hallucinations)是指生成式人工智能模型在生成文本或回答问题时,尽管表面上呈现出逻辑性和语法正确的形式,但其输出内容可能包含完全虚构、不准确或与事实不符的信息。AI幻觉的产生通常是由于模型在缺乏相关信息的情况下,通过概率性选择生成内容。
除了AI幻觉这一关键缺陷外,潜在的缺点与局限还包括可解释性、计算成本、数据偏见、实时更新、数据安全、个人隐私、恶意输出等。
■ 推理大模型
推理大模型是指能够在传统的大语言模型基础上,强化推理、逻辑分析和决策能力的模型。它们通常具备额外的技术,比如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
提示词设计指令简洁、关注目标。
不需要角色扮演及定义角色。
■ 非推理大模型
非推理大模型适用于大多数任务,非推理大模型一般侧重于语言生成、上下文理解和自然语言处理,而不强调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像推理模型那样复杂的推理和决策能力。
通用模型提示词设计需要结构化、缺什么补充即可。
不要对通用模型“过度信任”。
■ 模型分类
CoT(Chain-of-Thought)链式思维的出现将大模型分为了两类:概率预测(快速反应)模型和链式推理(慢速思考)模型。
◎ 概率预测(快速反应)模型
适合快速反馈,处理即时任务;算力成本低;基于概率预测,通过大量数据训练来快速预测可能的答案;擅长解决结构化和定义明确的问题;作为受控工具,几乎没有伦理问题。
◎ 链式推理(慢速思考)模型
通过推理解决复杂问题。
慢速思考,算力成本高;基于链式思维(Chain-of-Thought),逐步推理问题的每个步骤来得到答案;能够自主分析情况,实时做出决策;能够处理多维度和非结构化问题,提供创造性的解决方案;引发自主性和控制问题的伦理讨论。
综上,了解它们的差异有助于根据任务需求选择合适的模型,实现最佳效果。
■ 提示语
提示语(Prompt)是用户输入给AI系统的指令或信息,用于引导AI生成特定的输出或执行特定的任务。。
提示语的基本结构包括指令、上下文和期望:
◎ 指令(Instruction):提示语的核心,明确告诉AI你希望它执行什么任务。
◎ 上下文(Context):为AI提供背景信息,帮助它更准确地理解和执行任务。
◎ 期望(Expectation):明确或隐含地表达你对AI输出的要求和预期是什么。
提示语的基本元素:
◎ 信息类元素决定了AI在生成过程中需要处理的具体内容,包括主题、背景、数据等,为AI提供了必要的知识和上下文。
◎ 结构类元素用于定义生成内容的组织形式和呈现方式,决定了AI输出的结构、格式和风格。
◎ 控制类元素用于管理和引导AI的生成过程,确保输出符合预期并能够进行必要的调整,是实现高级提示语工程的重要工具。
■ 提示语链
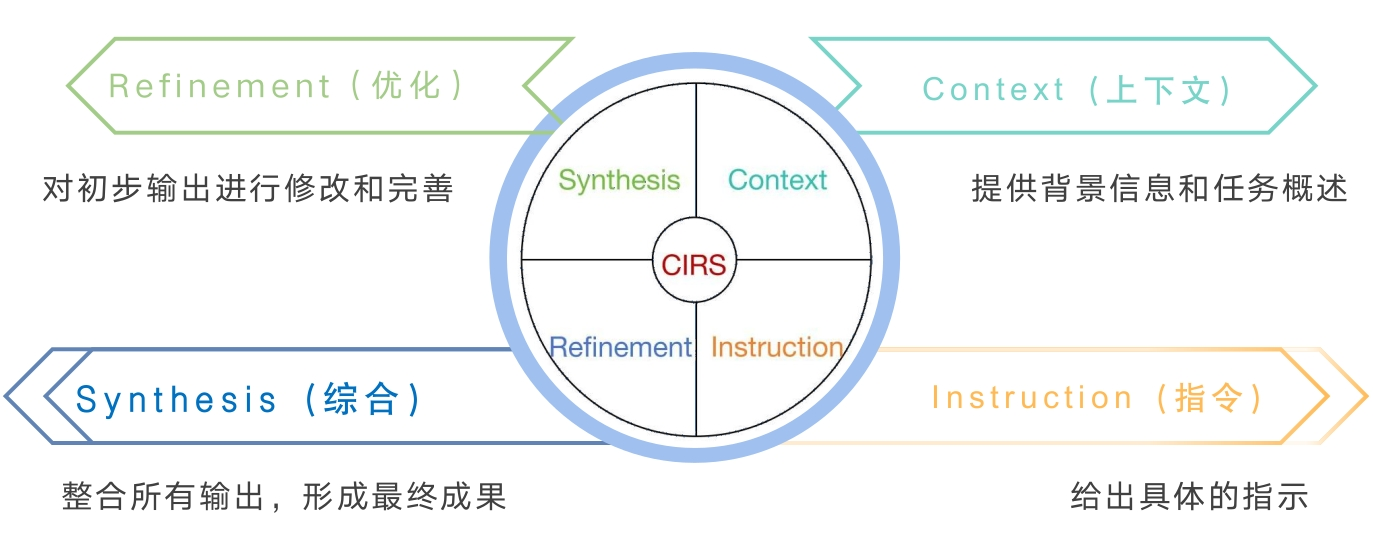
提示语链是用于引导AI生成内容的连续性提示语序列。通过将复杂任务分解成多个可操作的子任务,确保生成的内容逻辑清晰、主题连贯。从本质上看,提示语链是一种“元提示”(meta-prompt)策略,它不仅告诉AI“做什么”,更重要的是指导AI“如何做”。
为了更好地理解和设计提示语链,可采用CIRS模型(Context, Instruction, Refinement, Synthesis)。
■ 人机共生
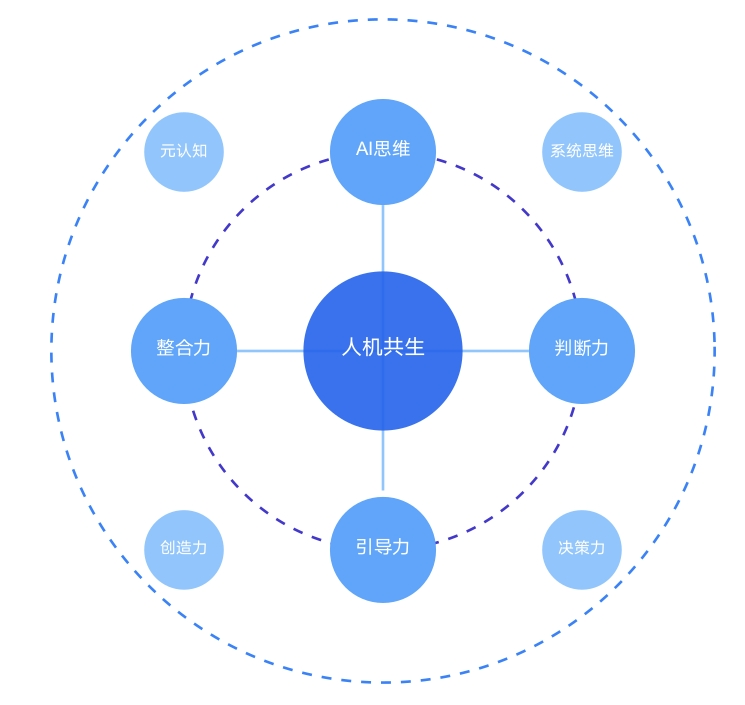
人的关键影响路径:提示词、质量控制、创意引导。
机器的关键影响路径:基础生成能力、理解准确度、一致性保证。
4 DeepSeek-V3 的综合能力
DeepSeek-V3 是一款具备多模态理解能力的智能助手,在文本、图像、文件解析等方面表现优异。
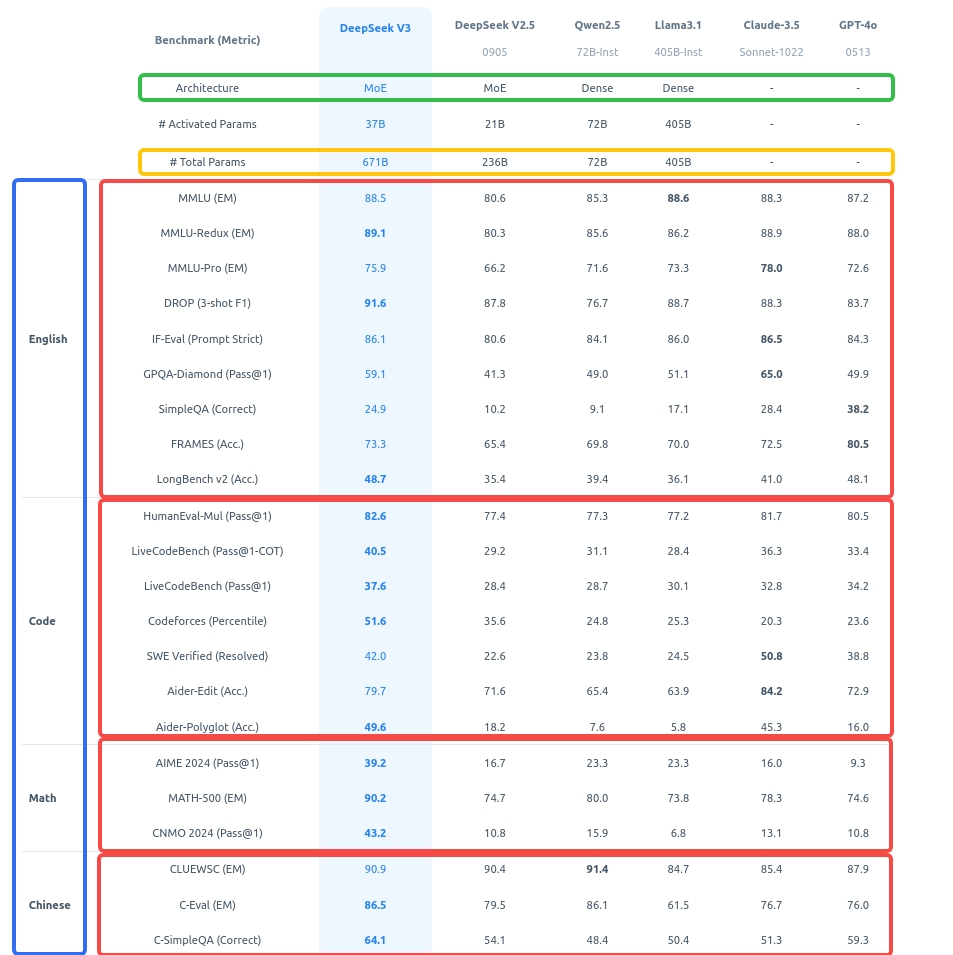
以下是其综合能力概述:
①文本处理
多语言支持:能够理解和生成多种语言的文本,包括中文、英文等。
上下文理解:具备长上下文记忆,能够根据对话历史提供连贯的回复。
文本生成:能够生成高质量的文章、摘要、翻译、代码等。
情感分析:能够识别文本中的情感倾向,提供情感支持或建议。
②图像理解
图像描述:能够分析图像内容并生成详细的文字描述。
OCR 识别:能够从图像中提取文字信息。
图像分类与标注:能够识别图像中的物体、场景并进行分类和标注。
③文件解析
多格式支持:能够处理 PDF、Word、Excel、PPT 等多种文件格式。
内容提取:能够从文件中提取关键信息,如表格、文本、图表等。
结构化输出:能够将文件内容转化为结构化数据,便于进一步分析。
④多模态交互
图文结合:能够同时处理文本和图像信息,提供综合性的回答。
跨模态推理:能够在文本和图像之间建立关联,进行复杂的推理任务。
⑤知识问答
广泛知识覆盖:涵盖科学、技术、文化、历史等多个领域。
实时信息检索:能够结合搜索引擎提供最新的实时信息。
⑥编程与代码生成
代码生成:能够根据需求生成多种编程语言的代码。
代码解释:能够解释代码的功能和逻辑。
调试与优化:能够帮助用户调试代码并提供优化建议。
⑦个性化服务
用户偏好学习:能够根据用户的历史交互学习偏好,提供个性化服务。
任务定制:能够根据用户需求定制化完成任务,如日程安排、提醒等。
⑧安全与隐私
数据保护:严格遵守隐私保护原则,确保用户数据安全。
内容过滤:能够识别并过滤不当内容,确保交互的合规性。
⑨持续学习与优化
模型更新:通过持续学习优化模型性能,提升准确性和响应速度。
用户反馈机制:支持用户反馈,快速改进服务质量。
综上,DeepSeek-V3 是一款功能强大、多模态融合的智能助手,能够高效处理文本、图像、文件等多种形式的信息,并提供个性化、智能化的服务。其广泛的应用场景和持续优化的能力使其成为用户生活和工作的得力助手。
说明:文中部分内容来源于网络,仅作为学习用途,如有侵权,请联系作者删除。
至此,本文的内容就结束了。



















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











