






目录
1.背景
-
会不会写 makefile ,从一个侧面说明了一个人是否具备完成大型工程的能力
-
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中, makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率
-
make 是一个命令工具,是一个解释 makefile 中指令的命令工具,一般来说,大多数的 IDE 都有这个命令,比如:Delphi 的 make , Visual C++ 的 nmake , Linux 下 GNU 的 make 。可见, makefile 都成为了一种在工程方面的编译方法
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2.理解
在正式理解makefile之前,我们先创建一个test.c文件,并编写一点代码。
#include<stdio.h>
int main()
{
printf("hello Linux!\n");
return 0;
} 这是一段简单的代码,我们可以使用gcc对其进行编译运行:
gcc test.c -o code.out
./code.out我们得到了以下的输出:

这当然没什么问题,那么我怎么使用makefile呢?
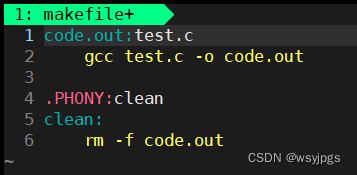
首先我们需要创建一个makefile文件,这个文件名可以是Makefile也可以是makefile,并写入以下内容:
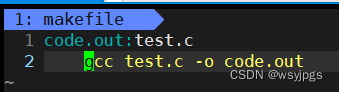
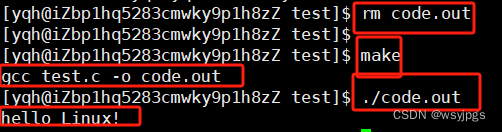
然后我们输入make,它就会自动编译我们的test.c文件生成了code.out(前面的rm就是删除掉上次编译后的可执行程序,避免产生干扰)
3.依赖关系和依赖方法
在正式讲这个之前,我们举一个例子:假设你这个月工资忘记发了,然后你找到了你的财务,提供了证据,跟他讲了你工资忘发的事情,最后财务把工资补给你了。
在这个小故事中,你忘记发工资为什么是找到你的财务,而不是HR?这个财务就可以类比成依赖关系,因为你的工资只与他有关,所以你才找到了他。你找到财务之后,如果什么都不说,他会知道你少了工资么?不一定吧!所以你提供证据跟他讲忘发工资了,这个就可以类比成依赖方法。
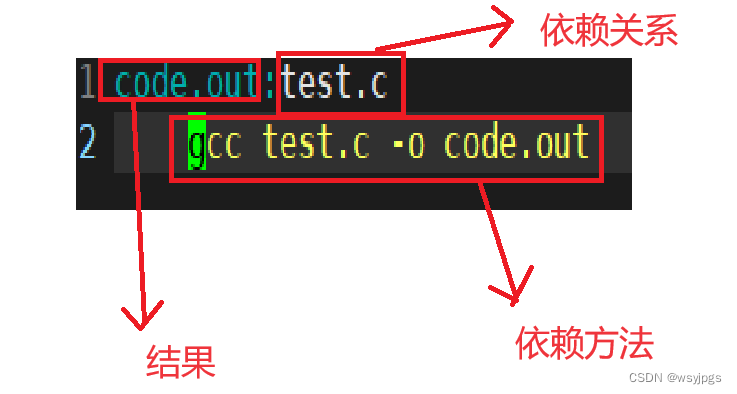
也就是说依赖关系和依赖方法,可以理解成:找谁,干什么。当然,做完事情之后也得有个结果,也就是我们冒号左边的东西,如下图解释:
4.项目清理
我们现在有了方便的代码编译方法,当然有时候也需要项目清理。所以我们就可以写个项目清理方法,并且使用它:
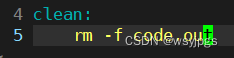
make clean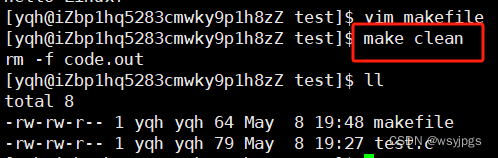
执行完后我们看到,它自动执行了我们写的rm指令,当然这个clean类似于C语言中的函数名,这个名字是可以自定义的,不一定要写成clean。
5. .PHONY
我们上面讲过makefile也讲了使用,那么如果我多次使用make,是不是会让代码多次编译呢?答案是不会,如下图:
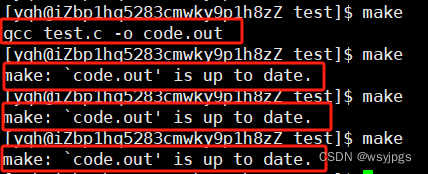
为什么呢?其实是Linux的一个优化,我们完全相同的代码,其实没有重复编译的必要对吧,所以Linux就会判断现在需要编译的代码是不是与之前的代码一样,如果没有改变,那么就不会重新编译。
那么问题又来了?它是怎么判断的呢?Linux呢用了一个十分聪明的方法,就是判断代码的修改时间,在一般情况下如果test.c 的修改时间在code.out 之前,那么这个代码就一定没有被修改过,如果test.c修改时间在code.out之后,那么说明这个代码是需要被编译的。
既然如此,我们有办法让他强制编译么?答案是有的。就是用 .PHONY将其设置成伪目标。
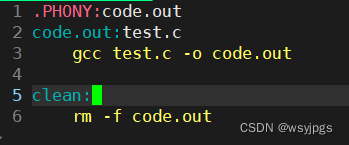
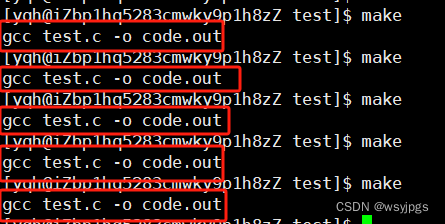
当然我们这个.PHONY一般不用在编译这里,一般是用在项目清理上如下图所示:因为重复编译是会带来性能损耗的,我们并不提倡。
6.执行顺序
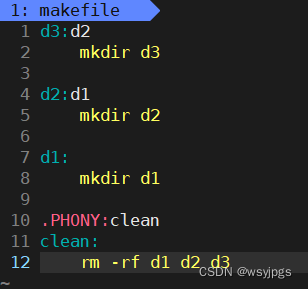
我们先写一个makefile文件,这里就是创建三个目录:d1、d2、d3这里的d2是依赖d1的,d3是依赖d2的,我们make一下,看看执行的步骤。
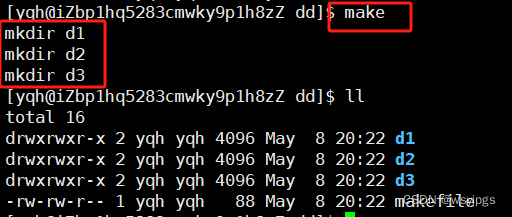
我们这里看到,它似乎是倒着执行的,先创建的d1再创建d2d3,那么我们把顺序打乱一下呢?
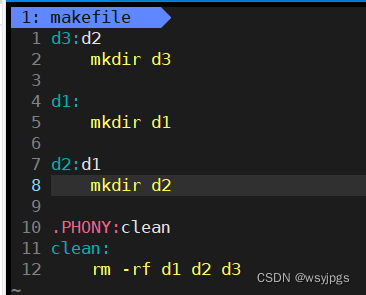
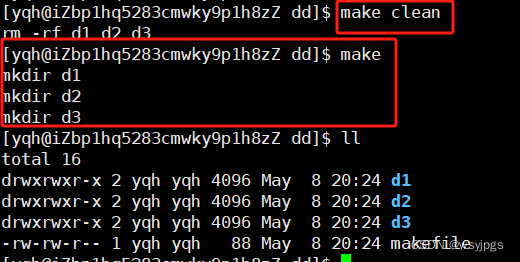
我们发现它依然是先d1,再d2d3,为什么呢?其实是这个依赖关系的原因,这个d3依赖d2,它就去找d2,找到d2,发现它依赖d1,它又去找d1,发现d1没有依赖,就直接创建d1,然后返回来创建d2,再创建d3,这个过程有点像我们的函数递归。所以这个“函数”摆在哪里并没有关系,只要“递归”的关系是对的就可以了。
7.结语
今天Linux的makefile就讲解到这里,如果有问题,欢迎评论区讨论哈。















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









