








📃博客主页: 小镇敲码人
💚代码仓库,欢迎访问
🚀 欢迎关注:👍点赞 👂🏽留言 😍收藏
🌏 任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。🍎🍎🍎
❤️ 什么?你问我答案,少年你看,下一个十年又来了 💞 💞 💞

《C语言文件处理:从新手到高手的跃迁》
)
📘 什么是文件
在C语言中,文件是一种用于在磁盘或其他持久化存储介质上存储数据的机制。文件可以是文本文件(包含人类可读的字符数据)或二进制文件(包含机器可读的字节数据)。C语言提供了丰富的文件操作函数,允许程序员创建、打开、读取、写入、关闭和删除文件。
🍵 程序文件
我们在编写程序的时候会生成一系列的文件,像源程序文件(.c),目标文件(windowns系统后缀为.obj),可执行文件(.exe).
🍵 数据文件
数据文件的内容不一定是程序,而可能是程序运行中用于读写的数据,存放这些数据的文件我们就叫做数据文件。
📘 为什么我们需要文件
因为我们在程序中生成的数据,程序运行结束后就被清空了,想让它保存下来我们就可以用到文件,将这些数据在程序运行的时候就保存到文件中去。
📘 文件的打开和关闭
想学习文件的打开和关闭,我们首先要了解文件指针的概念:
🍵 文件指针
在C语言中,文件指针是一个指向
FILE类型结构体的指针,用于在程序中引用文件。FILE是一个在C标准库中定义的类型,它包含了文件操作所需的所有信息,如文件的位置、缓冲区、错误标志等。
每个被使用的文件,系统都会在打开时在内存中给它开辟一段空间,用来保存它的基本信息(文件的缓存区、位置),这些信息是保存在结构体类型FILE中的,下面我们看看VS2013中FILE的结构体的具体实现:
#ifndef _FILE_DEFINEDstruct _iobuf {
char *_ptr; //文件输入的下一个位置
int _cnt; //当前缓冲区的相对位置
char *_base; //指基础位置(即是文件的其始位置)
int _flag; //文件标志
int _file; //文件的有效性验证
int _charbuf; //检查缓冲区状况,如果无缓冲区则不读取
int _bufsiz; //文件大小
char *_tmpfname; //临时文件名
};
typedef struct _iobuf FILE;#define _FILE_DEFINED#endif
我们通过一个指针去指向这个文件的信息区,因为这样方便使用,而且一个指针只需要4字节,内存占用少。
FILE* pf;//创建一个文件指针变量
我们想使用一个文件就需要先打开它,所以下面我们来学习一下fopen函数:
🍵 fopen函数
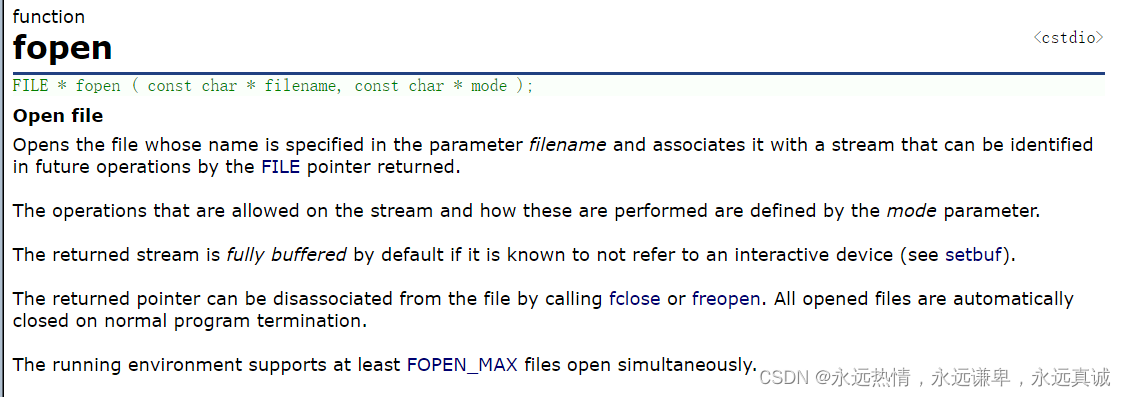
可以看到,这个函数有两个参数。
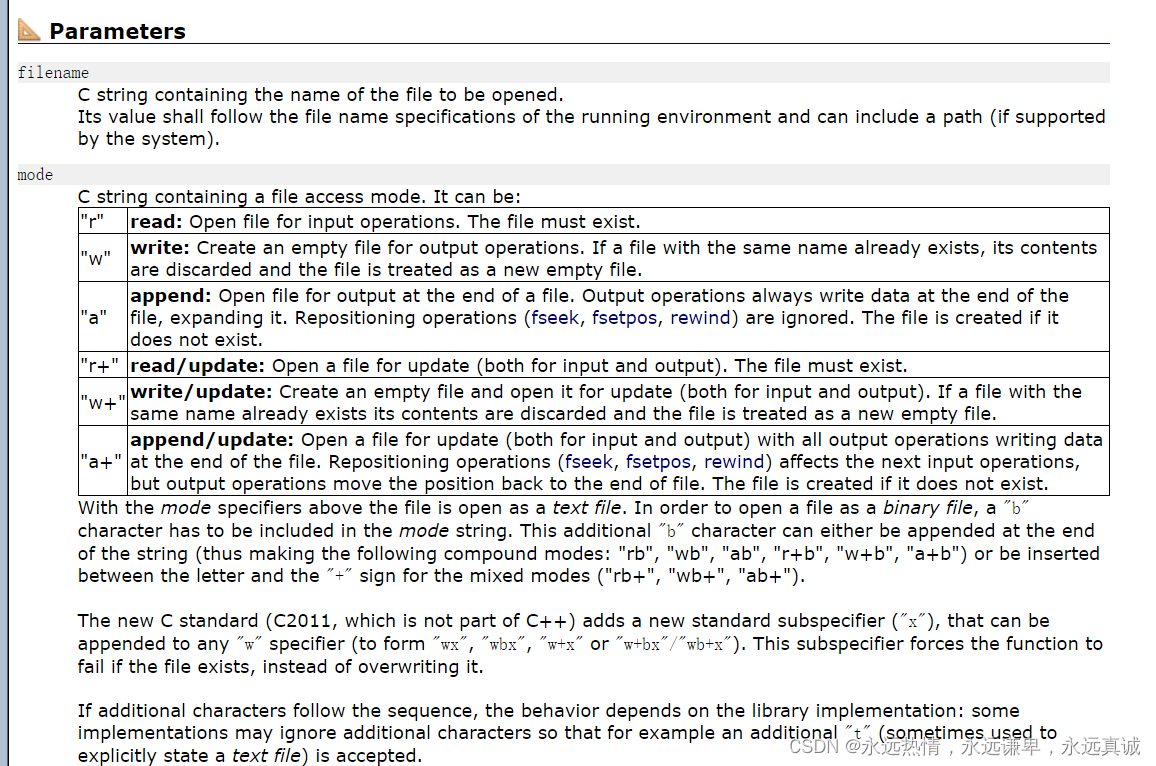
这两个参数都是char*类型,我们应该传一个字符串过去。
| 文件使用方式 | 含义 | 如果指定文件不存在 |
|---|---|---|
“r”(只读) | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
“w”(只写) | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
“a”(追加) | 向文本文件尾添加数据 | 建立一个新的文件 |
“rb”(只读) | 为了输入数据,打开一个二进制文件 | 出错 |
“wb”(只写) | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
“ab”(追加) | 向一个二进制文件尾添加数据 | 出错 |
“r+”(读写) | 为了读和写,打开一个文本文件 | 出错 |
“w+”(读写) | 为了读和写,建立一个新的文件 | 建立一个新的文件 |
“a+”(读写) | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
“rb+”(读写) | 为了读和写打开一个二进制文件 | 出错 |
“wb+”(读写) | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
“ab+”(读写) | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
.bin是二进制文件的常见后缀,所以模式字符串里面有b的都与二进制文件有关。我们介绍完所有的文件函数后,会写一段程序验证。

注意fopen函数的返回值是一个FILE类型的指针,我们要判断一下它是否为空才能使用,如果打开文件失败就会返回空指针。
有打开文件的函数,就有关闭文件的函数。
🍵 fclose函数

使用方法很简单,直接在这个函数里面传文件指针即可。
fclose(pf);//关闭pf指向的文件
那除了打开和关闭文件,我们更重要的是要学习如何读写文件,就会有相应的读写文件的函数,我们一一来介绍:
📘 文件的顺序读写
| 功能 | 函数名 | 适用于 |
|---|---|---|
| 字符输入函数 | fgetc | 所有输入流 |
| 字符输出函数 | fputc | 所有输出流 |
| 文本行输入函数 | fgets | 所有输入流 |
| 文本行输出函数 | fputs | 所有输出流 |
| 格式化输入函数 | fscanf | 所有输入流 |
| 格式化输出函数 | fprintf | 所有输出流 |
| 二进制输入 | fread | 文件 |
| 二进制输出 | fwrite | 文件 |
在介绍这些函数之前,我们首先先介绍一下流的概念:
🍵 流
流是一个抽象的概念,在我们的生活中有水流,在计算机中有数据流等,它是用来管理数据的。
🍋 为什么我们在使用scanf、printf时不需要打开屏幕,或者打开键盘呢?而在文件中写需要打开文件?
这是因为C语言程序在运行时,系统就帮助我们默认打开了三个流,标准输入流(
stdin)、标准输出流(stdout)、标准错误流(stderr),而这三个流的类型也是FILE文件结构体类型,所以实际上我们使用scanf、printf时也是打开了文件的,只不过这些工作有系统帮我们做了。
上面谈到了流的概念,实际上引入流是为了对程序员更加友好,因为外设实在是太多了,如果我们在读写数据都需要掌握那个外设的具体使用的话太复杂了,所以引入流的概念,我们读写数据只需要在流里面读写就行了,流相当于一个用于交流的纽带。
- 注意:
scanf是输入对应读数据(从缓冲区读),printf是输出对应写数据(打印在屏幕上)。
🍵 fgetc和fputc函数
这两个函数非常相似,所以我们放在一起看,后面这两个函数的使用条件是适用于所有输入/输出流,意思是这个函数也可以和标准的输入输出流进行数据的交流。
🍋 fgetc函数

这个函数只有一个参数,文件指针类型的流,我们既可以从文件流里面读数据,也可以从stdin里面读数据,注意:读到的数据是一个字符。
我们用代码来演示一下这个函数的使用:
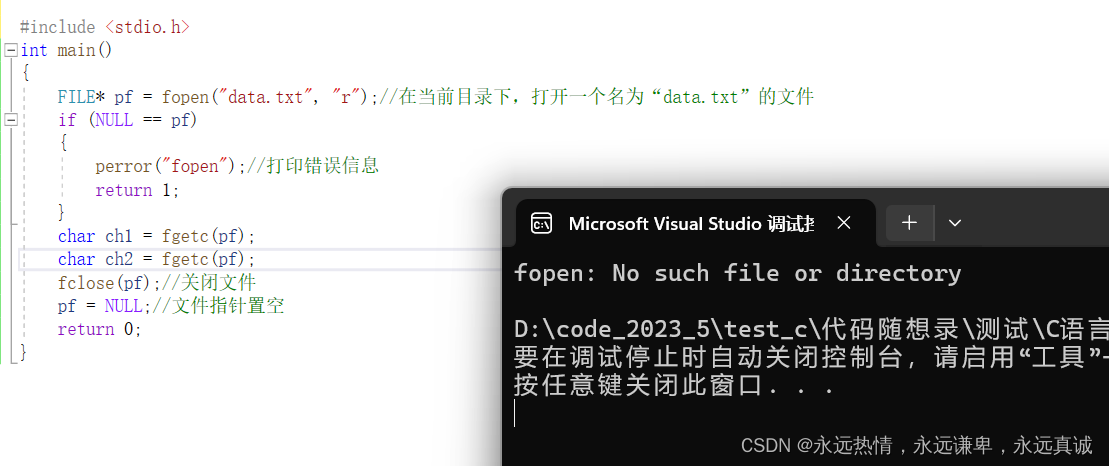
#include <stdio.h>
int main()
{
FILE* pf = fopen("data.txt", "r");//在当前目录下,打开一个名为“data.txt”的文件
if (NULL == pf)
{
perror("fopen");//打印错误信息
return 1;
}
char ch1 = fgetc(pf);
char ch2 = fgetc(pf);
printf("%c %c", ch1, ch2);
fclose(pf);//关闭文件
pf = NULL;//文件指针置空
return 0;
}
如果你没有在当前目录建立一个名为“data.txt”的文件,系统不会帮你建立一个新的文件,而是会将pf指针置空。
这里我们去到当前目录建立一个叫做data.txt的文件,并放入数据abcdef,再来看执行结果:
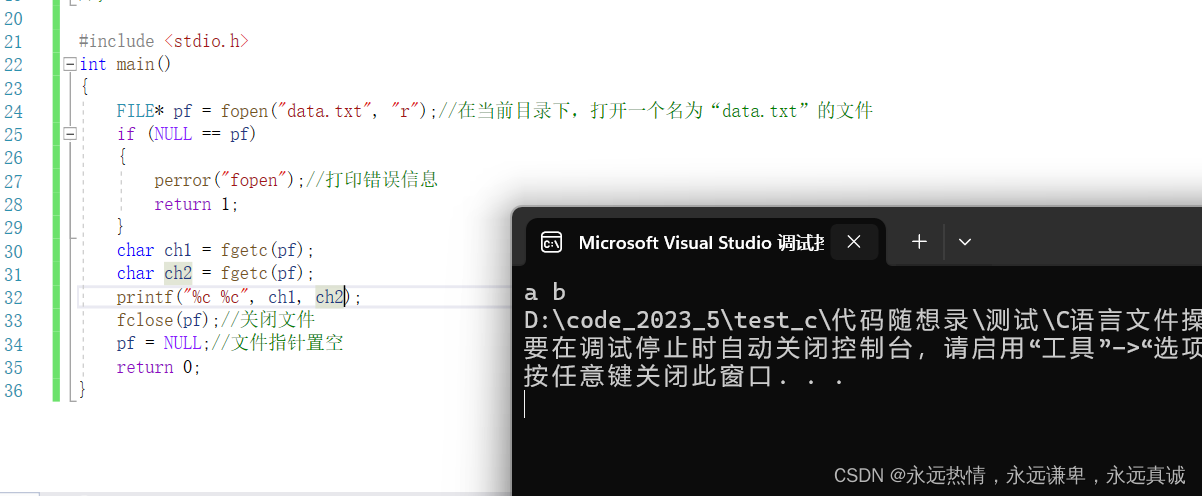
为什么是结果是a b呢,因为文件指针在初始时指向最开始数据a,读完a后文件指针后移一位,指向b。
这个函数也可以从标准输入流里面读数据,也就是我们等价自己从键盘输入,只需要在fgetc函数里传stdin过去即可。
#include <stdio.h>
int main()
{
char ch1 = fgetc(stdin);
char ch2 = fgetc(stdin);
printf("%c %c", ch1, ch2);
return 0;
}
运行结果:
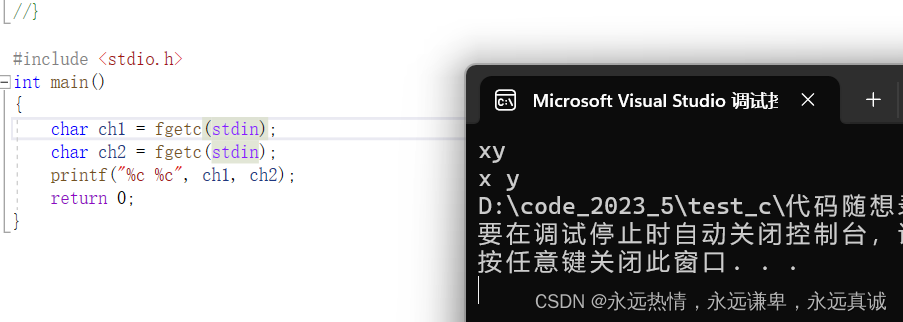
🍋 fputc
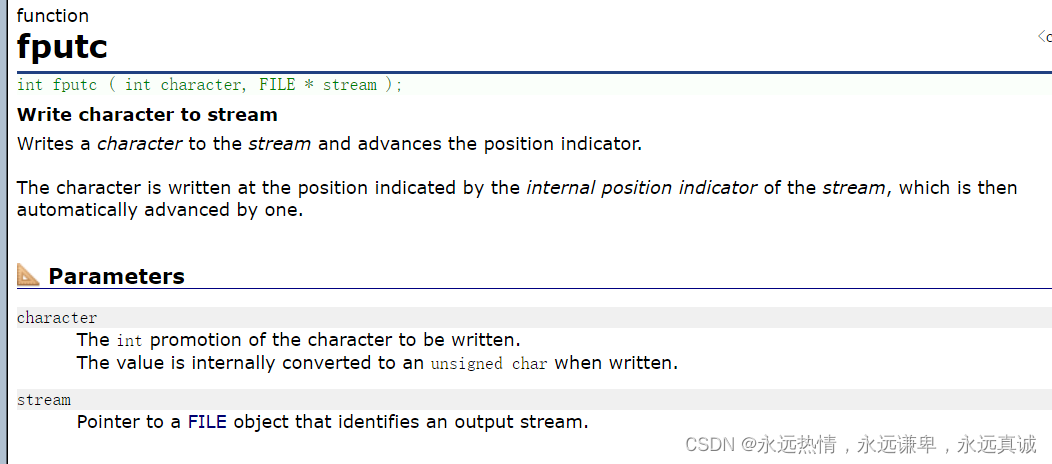
fputc函数和fgetc函数比较相似,都是逐字符对流进行操作,同样的它既可以把字符写到文件中,也可以把字符写到屏幕上(标准输出流)。
💎 写入数据到文件中
注意和模式"r"不一样的是,"w"模式如果文件不存在,则会创建一个新文件再写入,如果之前的文件存在,会将它先清空再写入。 我们用代码来演示一下:
#include <stdio.h> // 引入标准输入输出库,因为使用了FILE*和相关的函数
int main()
{
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "w");
// 尝试以写入模式("w")打开名为"data.txt"的文件,并将文件指针赋值给pf
// 如果文件不存在,则创建它;如果文件已存在,则清空其内容
// 检查文件是否成功打开
if (NULL == pf)
{
// 如果pf为NULL,表示文件打开失败
// 使用perror函数输出系统给出的错误信息
perror("fopen");
// 返回1表示程序执行出错
return 1;
}
// 向文件中写入一个字符'a'
fputc('a', pf);
// 接着写入一个字符'b'
fputc('b', pf);
// 关闭文件,释放与之相关的资源
fclose(pf);
// 将pf设置为NULL,这是一个好习惯,以避免在后续代码中误用已关闭的文件指针
pf = NULL;
// 程序正常执行完毕,返回0
return 0;
}
我们来看文件data里的情况:
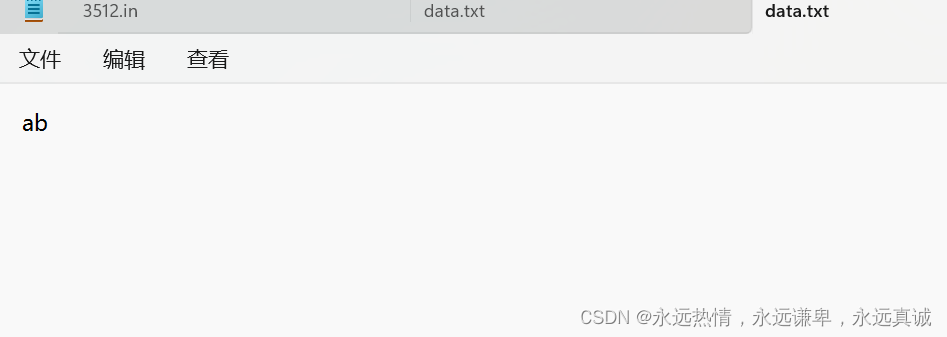
可以看到,我们之前写入的数据abcdefg不见,所以之前的内容应该是被清空了。
我们也可以将数据输出到屏幕上:
💎 写入数据到标准输出流(stdout)
#include <stdio.h> // 引入标准输入输出库,因为程序使用了fputc函数和标准文件指针stdout和stderr
int main()
{
// 使用fputc函数将字符'a'写入标准输出流stdout
// 这通常意味着字符'a'将被打印到控制台(或标准输出设备)
fputc('a', stdout);
// 接着,使用fputc函数将空格字符' '写入标准输出流stdout
// 这同样意味着空格将被打印到控制台,跟在字符'a'后面
fputc(' ', stdout);
// 然后,使用fputc函数将字符'b'写入标准错误流stderr
// 这通常意味着字符'b'将被打印到错误输出设备,它可能与标准输出设备不同
// 例如,在某些系统或配置中,标准输出可能重定向到文件,而标准错误则直接显示在屏幕上
fputc('b', stderr);
// 程序正常执行完毕,返回0
return 0;
}
这里我们stdout和stderr是一样的都是打印在屏幕上:
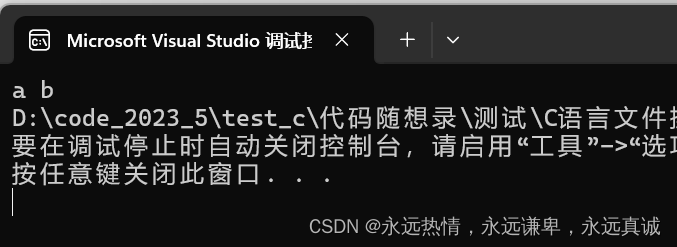
🍵 fputs和fgets函数
这两个函数和
fgetc、fputc系列的唯一区别是一个输入输出的是单个字符,而这两个输入输出的是一个字符串。
我们不做细致的介绍,只演示一下这两个函数的使用:
🍋 fputs
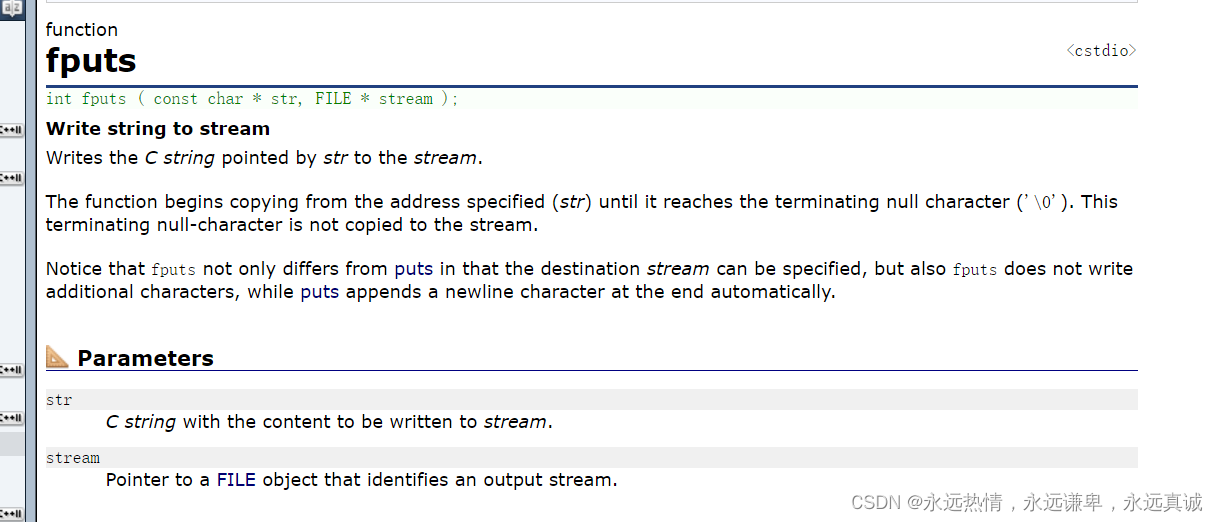
代码演示:
#include <stdio.h> // 引入标准输入输出库,因为使用了FILE*和相关的文件操作函数
int main()
{
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "w");
// 尝试以写入模式("w")打开名为"data.txt"的文件,并将文件指针赋值给pf
// 如果文件不存在,则创建它;如果文件已存在,则清空其内容
// 检查文件是否成功打开
if (NULL == pf)
{
// 如果pf为NULL,表示文件打开失败
// 使用perror函数输出系统给出的错误信息
perror("fopen");
// 返回1表示程序执行出错
return 1;
}
// 写入字符串"abcdeefddd"到文件中
// 使用fputs函数进行写入,它会写入整个字符串,直到遇到字符串的结束符'\0'
fputs("abcdeefddd", pf);
// 接着写入另一个字符串"xxxxxxxxxxxxxxxxxxxx"到文件中
// 同样使用fputs函数进行写入
fputs("xxxxxxxxxxxxxxxxxxxx", pf);
// 关闭文件,释放与之相关的资源
fclose(pf);
// 将pf设置为NULL,这是一个好习惯,以避免在后续代码中误用已关闭的文件指针
pf = NULL;
// 程序正常执行完毕,返回0
return 0;
}
如果你想换行,需要自己加上换行符\n,写文件时是顺序写,默认不会换行:

同样的,这个函数适用于所有流,也可以打印在屏幕上,这里我们不再演示。
🍋 fgets
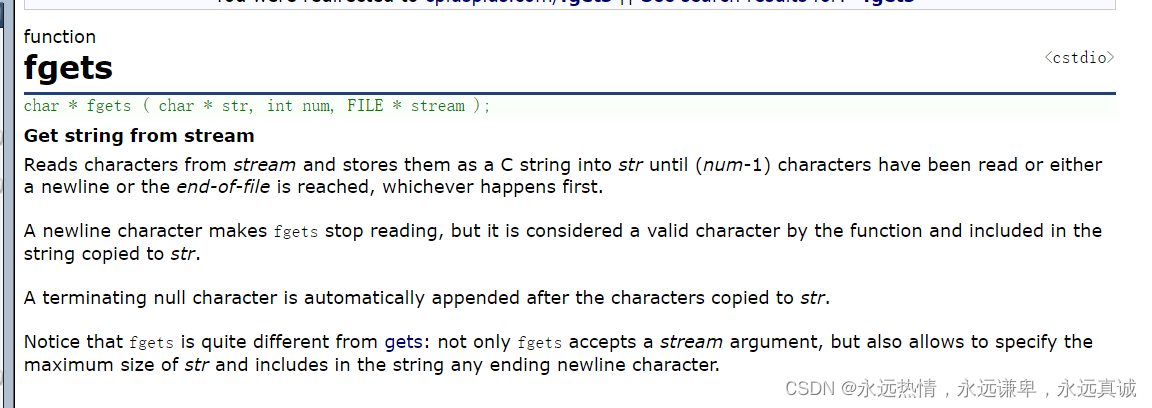
这个函数的参数有三个,从文档中可以看到,它会从流中读num-1个字符给我们的str,返回值也是char*.
代码演示:
#include <stdio.h>
int main()
{
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "r");
// 尝试以读取模式("r")打开名为"data.txt"的文件,并将文件指针赋值给pf
// 如果文件不存在,则fopen返回NULL
// 检查文件是否成功打开
if (NULL == pf)
{
// 如果pf为NULL,表示文件打开失败
// 使用perror函数输出系统给出的错误信息
perror("fopen");
// 返回1表示程序执行出错
return 1;
}
// 读文件
// 定义一个字符数组s,用于存储从文件中读取的字符串
char s[100];
// 使用fgets函数从文件中读取最多3个字符(因为fgets会读取直到遇到换行符或读取了n-1个字符,再加上字符串的结束符'\0')
// 注意:这里我们传入了10作为第二个参数,但fgets实际只会读取9个字符加上'\0'
fgets(s,10, pf);
// 打印读取到的字符串
printf("%s", s);
// 关闭文件,释放与之相关的资源
fclose(pf);
// 将pf设置为NULL,这是一个好习惯,以避免在后续代码中误用已关闭的文件指针
pf = NULL;
// 程序正常执行完毕,返回0
return 0;
}
运行结果:
文件中放入的数据为:

程序运行结果:

可以看到,程序将\和0当成了两个字符存进去了,而不是转义字符\0。
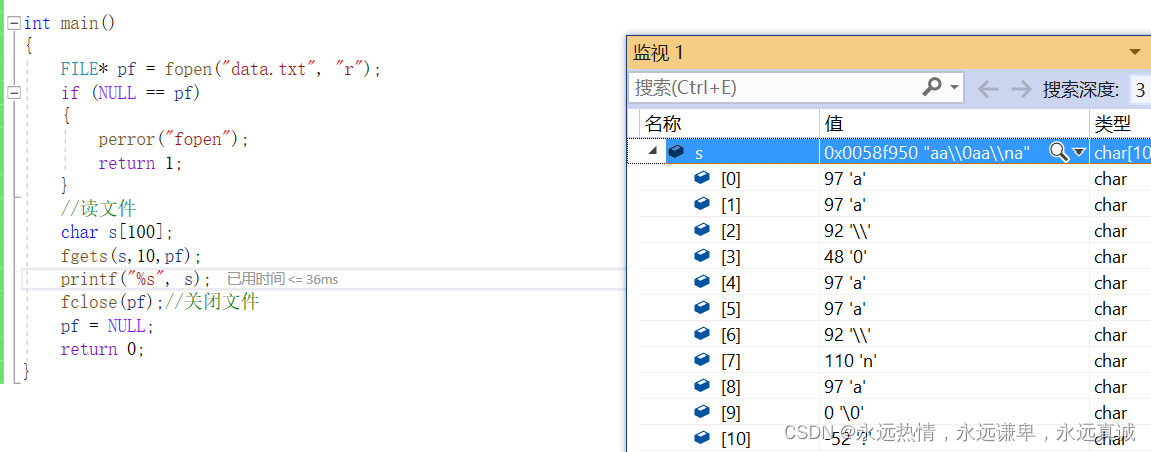
这里为什么只读了num-1个字符呢,因为字符串的结尾要加上\0作为结束符,\0也占了一个字符的空间,这里编译器自动给我们添加上了。
🍵 fscanf和fprintf函数
🍋 fprintf函数
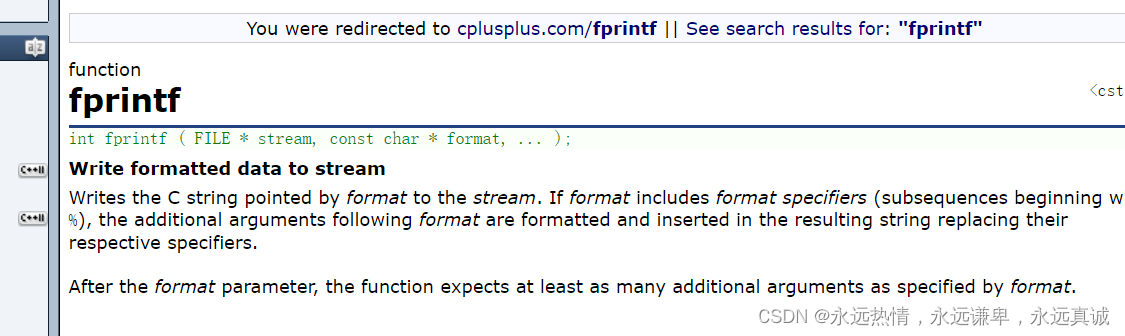
fprintf函数的作用是数据格式化的写到流中去,适用于所有流,我们来演示一下这个函数的使用:
#include <stdio.h> // 引入标准输入输出库
// 定义一个结构体类型 Student,并使用typedef关键字为它定义别名 Stu
typedef struct Student
{
char name[20]; // 存储学生姓名的字符数组,最多可以包含19个字符(加一个'\0'结尾)
char id[20]; // 存储学生ID的字符数组,最多可以包含19个字符(加一个'\0'结尾)
char sex[10]; // 存储学生性别的字符数组,这里长度设为10可能有点大,通常"男"或"女"加上'\0'即可
int age; // 存储学生年龄的整数
} Stu; // 注意这里是大写的S,定义了一个结构体别名Stu
int main()
{
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "w");
// 尝试以写入模式("w")打开名为"data.txt"的文件,并将文件指针赋值给pf
// 如果文件不存在,则创建它;如果文件已存在,则清空其内容
if (NULL == pf)
{
// 如果pf为NULL,表示文件打开失败
// 使用perror函数输出系统给出的错误信息
perror("fopen");
// 返回1表示程序执行出错
return 1;
}
// 定义一个Stu类型的变量s,并初始化它的各个字段
Stu s = { "张三", "123456789", "男", 12 };
// 使用fprintf函数将结构体s的各个字段写入到文件中
// 这里使用格式化字符串来指定输出的格式和内容
fprintf(pf, "%s %s %s %d", s.name, s.id, s.sex, s.age);
// 关闭文件,释放与之相关的资源
fclose(pf);
// 将pf设置为NULL,避免后续误用已关闭的文件指针
pf = NULL;
// 程序正常执行完毕,返回0
return 0;
}
我们来看看文件中是否已经写入了相应的结果:
🍋 fscanf函数
fscanf适用于所有流,但是scanf函数规定死了,只适用于标准输入流。
下面我们来演示一下这个函数的使用:
#include <stdio.h> // 引入标准输入输出库
// 定义一个结构体类型 Student,并使用typedef关键字为它定义别名 Stu
typedef struct Student
{
char name[20]; // 存储学生姓名的字符数组
char id[20]; // 存储学生ID的字符数组
char sex[10]; // 存储学生性别的字符数组
int age; // 存储学生年龄的整数
} Stu; // 注意这里是大写的S,定义了一个结构体别名Stu
int main()
{
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "r");
// 尝试以读取模式("r")打开名为"data.txt"的文件,并将文件指针赋值给pf
// 如果文件不存在或无法打开,则fopen返回NULL
if (NULL == pf)
{
// 如果pf为NULL,表示文件打开失败
// 使用perror函数输出系统给出的错误信息
perror("fopen");
// 返回1表示程序执行出错
return 1;
}
// 定义一个Stu类型的变量s,并初始化所有字段为0(对于int类型,是0;对于char数组,是'\0')
Stu s = { 0 };
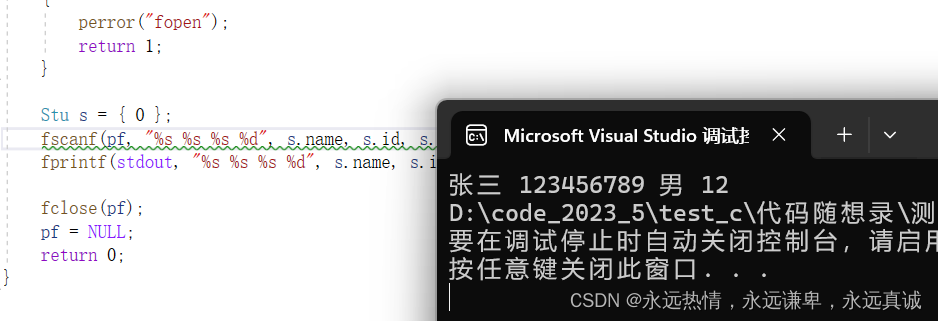
// 使用fscanf函数从文件中读取数据到s的各个字段中
// 注意:这里应该检查fscanf的返回值以确保成功读取了4个字段
fscanf(pf, "%s %s %s %d", s.name, s.id, s.sex, &s.age);
// 使用fprintf函数将s的各个字段打印到标准输出(通常是终端或控制台)
fprintf(stdout, "%s %s %s %d\n", s.name, s.id, s.sex, s.age);
// 关闭文件,释放与之相关的资源
fclose(pf);
// 将pf设置为NULL,避免后续误用已关闭的文件指针
pf = NULL;
// 程序正常执行完毕,返回0
return 0;
}
运行结果:
🍵 sscanf和sprintf
🍋 sprintf

根据文档,这个函数和前面两个printf系列函数的区别就是,第一个参数变成了字符指针,这个函数的功能是把格式化的数据写进字符串里面。
我们通过一段代码来了解一下它的使用:
#include <stdio.h> // 引入标准输入输出库
// 定义一个结构体类型 Student,并使用typedef关键字为它定义别名 Stu
typedef struct Student
{
char name[20]; // 存储学生姓名的字符数组
char id[20]; // 存储学生ID的字符数组
char sex[10]; // 存储学生性别的字符数组
int age; // 存储学生年龄的整数
} Stu; // 定义了一个结构体别名Stu
int main()
{
// 创建一个Stu类型的变量s,并初始化其成员
Stu s = { "张三", "12345678", "男", 13 };
// 定义一个字符数组s1,用于存储格式化后的字符串
char s1[40]; // 足够大以存储格式化后的字符串,包括空格和可能的空字符'\0'
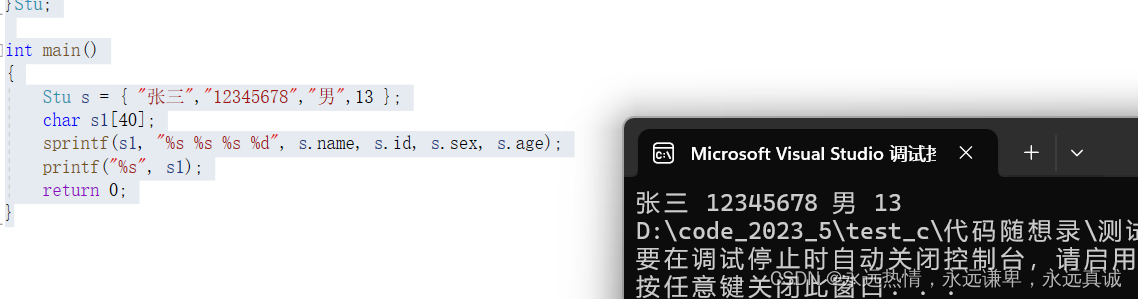
// 使用sprintf函数将s的各个成员格式化为一个字符串,并存储在s1中
sprintf(s1, "%s %s %s %d", s.name, s.id, s.sex, s.age);
// 使用printf函数将s1的内容打印到控制台
printf("%s\n", s1); // 在末尾添加了一个换行符'\n'以使输出更整洁
// 程序正常执行完毕,返回0
return 0;
}
运行结果:
🍋 sscanf
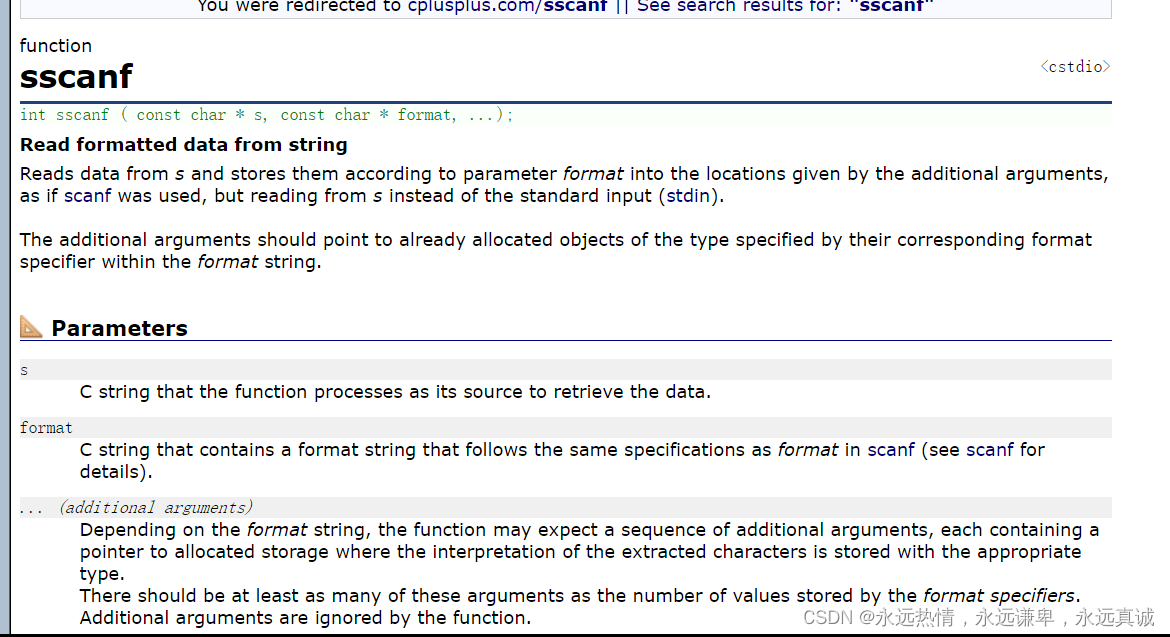
sscanf是从字符串中提取格式化的数据:
#include <stdio.h>
// 使用typedef为结构体Student定义别名Stu
typedef struct Student
{
char name[20]; // 学生姓名,最多20个字符
char id[20]; // 学生ID,最多20个字符
char sex[10]; // 学生性别,最多10个字符
int age; // 学生年龄
} Stu;
int main()
{
Stu s = {0}; // 初始化Stu类型的变量s,所有成员设置为0(或'\0'对于char数组)
// 定义一个字符数组s1,并初始化为包含学生信息的字符串
char s1[40] = "张三 12345678 男 12";
// 使用sscanf从s1中读取数据到s的各个成员中
// 注意:添加了宽度限制以防止缓冲区溢出
sscanf(s1, "%19s %19s %9s %d", s.name, s.id, s.sex, &s.age);
// 打印学生信息
printf("%s %s %s %d\n", s.name, s.id, s.sex, s.age);
// 程序正常结束,返回0
return 0;
}
运行结果:
🍵 三组格式化输入输出函数的区别
| 函数 | scanf/printf | fscanf/fprintf | sscanf/sprintf |
|---|---|---|---|
| 共同点 | 都是格式化输入输出函数 | 都是格式化输入输出函数 | 都是格式化输入输出函数 |
| 区别 | 只能进行标准输入输出流的格式化的写或者读 | 适用于所有流的格式化的写或者读 | 从字符串中写或者读格式化的数据 |
🍵 fread和fwrite函数
🍋 fwrite
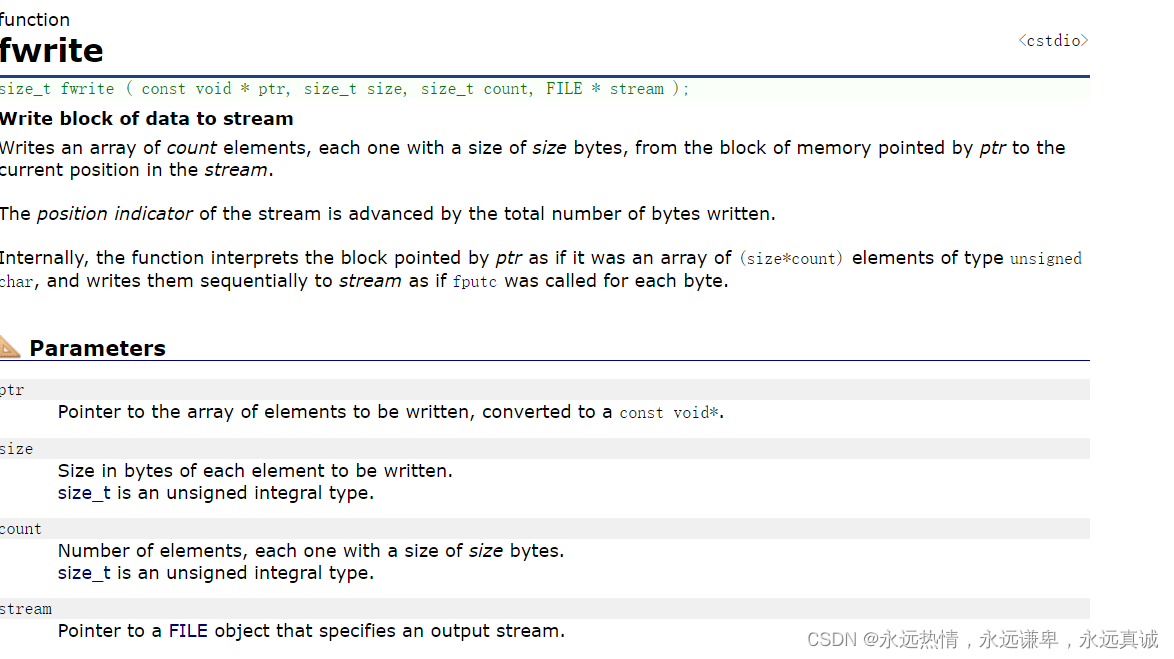
根据文档,这个函数的功能是将count个大小为size的对象写入文件中,这些对象的起始地址为ptr,这个函数的返回值是返回成功被写入的数据的个数,如果一个都没被写入,就会返回0。写入的是二进制,我们需要将模式加上b。
代码演示:
#include <stdio.h>
#include <stdlib.h> // 包含perror函数所需的头文件
// 使用typedef为结构体Student定义别名Stu
typedef struct Student
{
char name[20]; // 学生姓名,最多20个字符
char id[20]; // 学生ID,最多20个字符
char sex[10]; // 学生性别,最多10个字符
int age; // 学生年龄
} Stu;
int main()
{
// 初始化一个Stu类型的变量s,并为其成员赋值
Stu s = { "李四", "1233311", "男", 14 };
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "wb"); // 以二进制写入模式("wb")打开名为"data.txt"的文件
// 检查文件是否成功打开
if (pf == NULL)
{
// 如果文件打开失败,使用perror函数输出错误信息
perror("fopen"); // 输出系统错误信息,并附加"fopen"字符串
// 返回1表示程序异常退出
return 1;
}
// 使用fwrite函数将s的内容写入文件
// 第一个参数是s的地址,第二个参数是每个数据块的大小(即s的大小),第三个参数是要写入的数据块数量(这里为1),第四个参数是文件指针
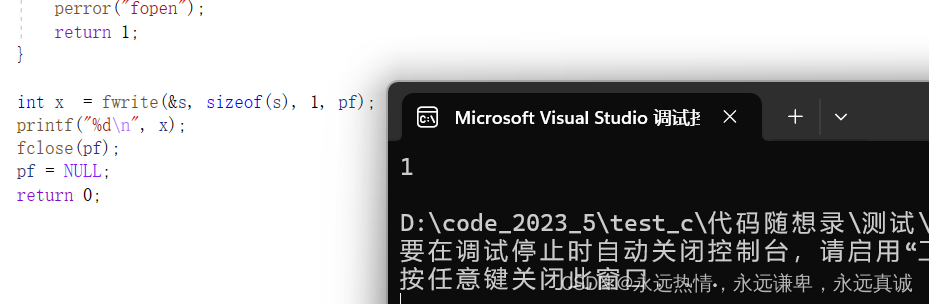
int x = fwrite(&s, sizeof(s), 1, pf);
// 打印写入的数据块数量(应为1,如果成功)
printf("%d\n", x);
// 关闭文件
fclose(pf);
// 将文件指针设置为NULL,防止野指针
pf = NULL;
// 程序正常结束,返回0
return 0;
}
写入结果:
二进制文件中的内容在文本编辑器中看起来像乱码,是因为文本编辑器尝试解释二进制数据为文本,导致显示不可读的字符。
成功写入的数据的个数:
🍋 fread
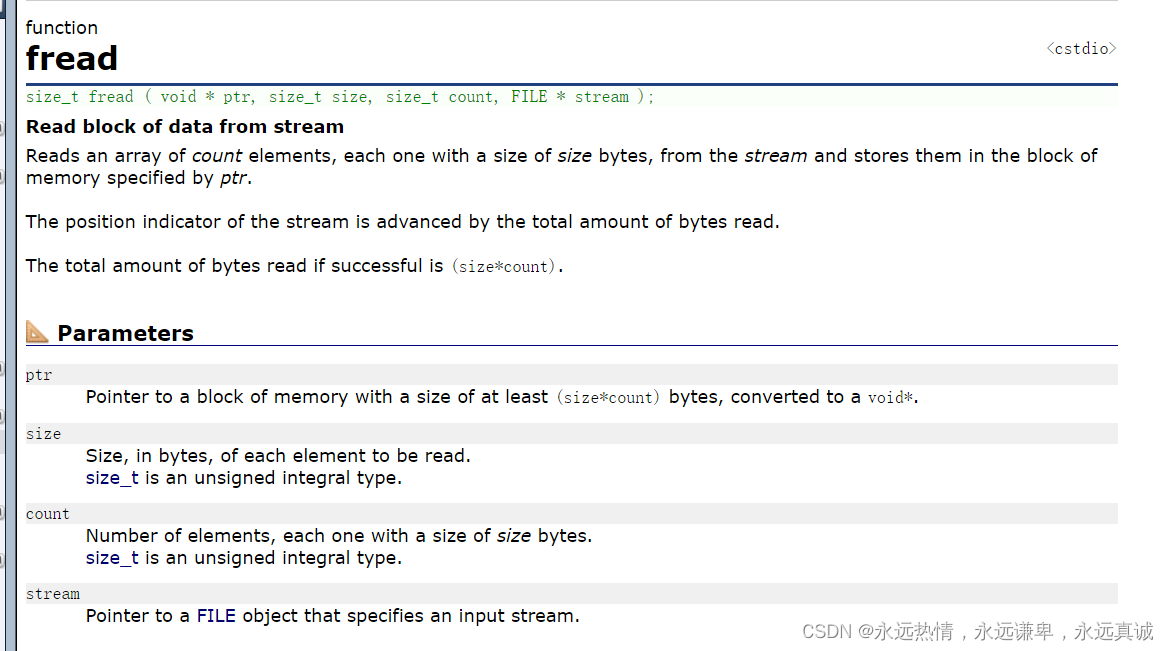
这个函数的功能就是从文件中读入count个大小为size的二进制数据到地址ptr中。同样返回值是数据被成功读入的个数。
我们用代码来演示:
#include <stdio.h>
#include <stdlib.h> // 引入stdlib.h以使用perror函数
// 使用typedef为结构体Student定义别名Stu
typedef struct Student
{
char name[20]; // 学生姓名,最多20个字符
char id[20]; // 学生ID,最多20个字符
char sex[10]; // 学生性别,最多10个字符
int age; // 学生年龄
} Stu;
int main()
{
// 初始化一个Stu类型的变量s,将所有成员设置为0(对于char数组,这意味着它们将被填充为'\0')
Stu s = {0};
// 定义一个文件指针pf,用于后续的文件操作
FILE* pf = fopen("data.txt", "rb"); // 以二进制读取模式("rb")打开名为"data.txt"的文件
// 检查文件是否成功打开
if (pf == NULL)
{
// 如果文件打开失败,使用perror函数输出错误信息
perror("fopen"); // 输出系统错误信息,并附加"fopen"字符串
// 返回1表示程序异常退出
return 1;
}
// 使用fread函数从文件中读取数据到s中
// 第一个参数是s的地址,第二个参数是每个数据块的大小(即s的大小),第三个参数是要读取的数据块数量(这里为1),第四个参数是文件指针
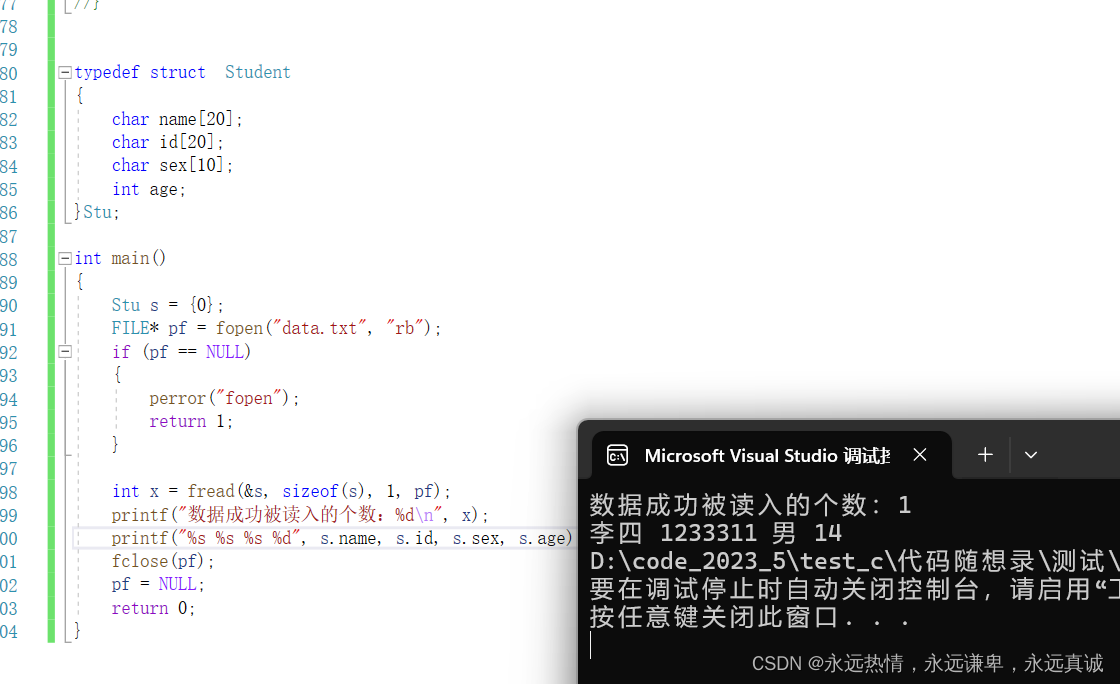
int x = fread(&s, sizeof(s), 1, pf); // 尝试读取一个Stu结构体大小的数据块
// 打印成功读取的数据块数量(对于结构体,这通常是1或0,表示是否成功读取了一个完整的结构体)
printf("数据成功被读入的个数:%d\n", x);
// 打印读取到的学生信息
printf("%s %s %s %d\n", s.name, s.id, s.sex, s.age); // 添加了换行符使输出更清晰
// 关闭文件
fclose(pf);
// 将文件指针设置为NULL,防止野指针
pf = NULL;
// 程序正常结束,返回0
return 0;
}
运行结果:
虽然以二进制来输入输出数据,以文本来显示我们可能看不懂,但是编译器能看懂就行,我们不需要深究其底层是如何运转的。
📘 文件的随机读写
🍵 fseek函数
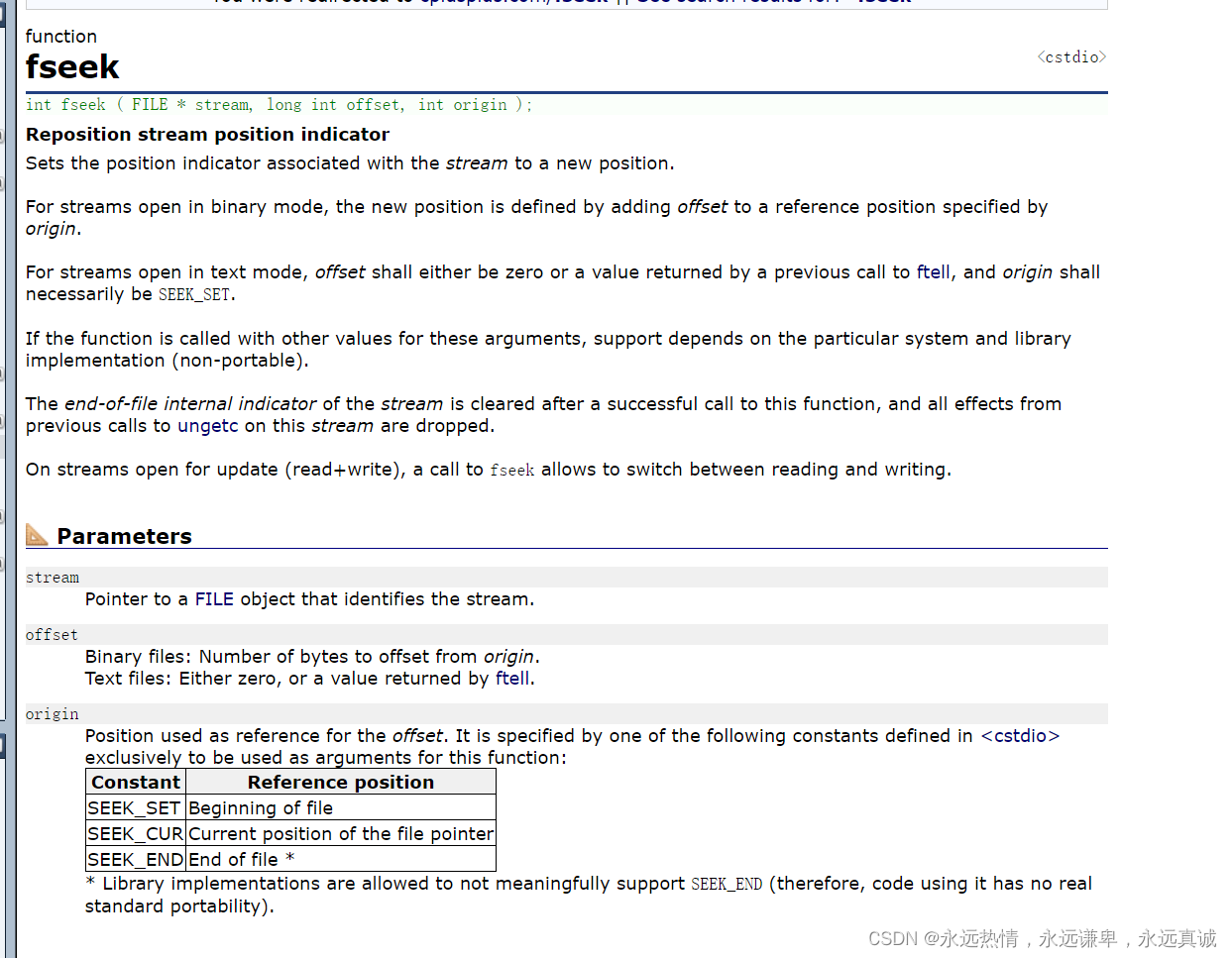
这个函数的功能是来改变文件指针的位置的,三个参数分别是文件指针、偏移量、文件指针偏移的起始位置。
我们从文档中可以看到,第三个参数可以传三个常数过去,我们可以看看其底层:

这样设计可以增加代码的可读性,可以看到,这三个常数是用宏来是实现的。另外文档中还说使用fseek函数文件必须以二进制的模式来打开,这样我们使用一些函数往文本中写入的就是二进制数据了。我们用代码来演示一下这个函数的使用:
#include <stdio.h>
int main()
{
FILE* pFile;
// 以二进制读写模式("wb+")打开名为 "data.txt" 的文件
pFile = fopen("data.txt", "wb+");
if (pFile == NULL) {
// 如果文件打开失败,输出错误信息并退出程序
printf("文件打开失败!\n");
return 1;
}
// 使用 fwrite 写入字符串 "This is an apple." 到文件
// 注意:sizeof("This is an apple.") 会计算包括结尾 '\0' 在内的整个字符串的大小
// 但由于我们是在二进制模式下写入,并且不希望写入 '\0',因此这里应该减去 1
fwrite("This is an apple.", sizeof(char), sizeof("This is an apple.") - 1, pFile);
// 将文件指针移动到文件的第 9 个字节位置(从文件开始计算)
fseek(pFile, 9, SEEK_SET);
// 写入字符串 " sam" 到文件(不包括结尾的 '\0')
// 使用 sizeof(" sam") - 1 来确保只写入 " sam" 这 4 个字符
fwrite(" sam", sizeof(char), sizeof(" sam") - 1, pFile);
char s[50] = { 0 }; // 定义一个字符数组 s,并初始化为全 0
// 将文件指针重新定位到文件的开始位置
fseek(pFile, 0, SEEK_SET);
// 读取文件内容到字符数组 s 中
// 注意:fread 不会为字符串添加结尾的 '\0',我们需要手动处理
// 由于文件内容可能小于 50 个字符,我们不能简单地读取整个数组大小
// 这里我们使用 fread 读取直到遇到 EOF 或者达到数组大小 - 1(为 '\0' 预留空间)
size_t bytesRead = fread(s, sizeof(char), sizeof(s) - 1, pFile);
s[bytesRead] = '\0'; // 手动添加字符串结尾的 '\0'
// 输出读取到的字符串
printf("%s\n", s); // 通常我们在输出字符串后加上 '\n' 以方便阅读
// 关闭文件
fclose(pFile);
// 程序正常结束,返回 0
return 0;
}
我们来画图解释一下这段程序:

运行结果:
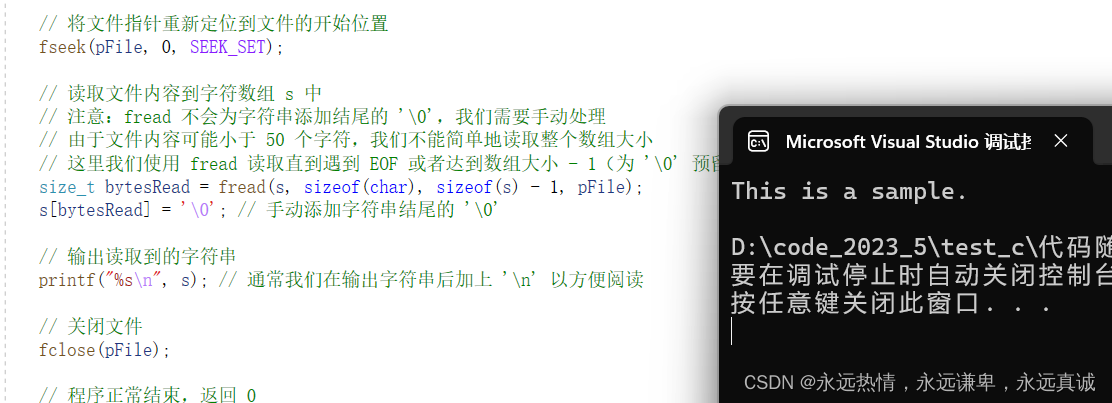
- 注意,同时读写时,在读之后或者写之后,必须刷新一下文件指针的位置,否则就会出现一些未知的错误,这是官方文档的规定。

- 当你使用二进制模式时,你会发现使用一些文本函数(非二进制读写函数)在某些环境下也可以成功,但是官方文档不保证在所以环境下都没问题,所以为了增加代码的可移植性,建议按照规范进行。
🍵 ftell函数
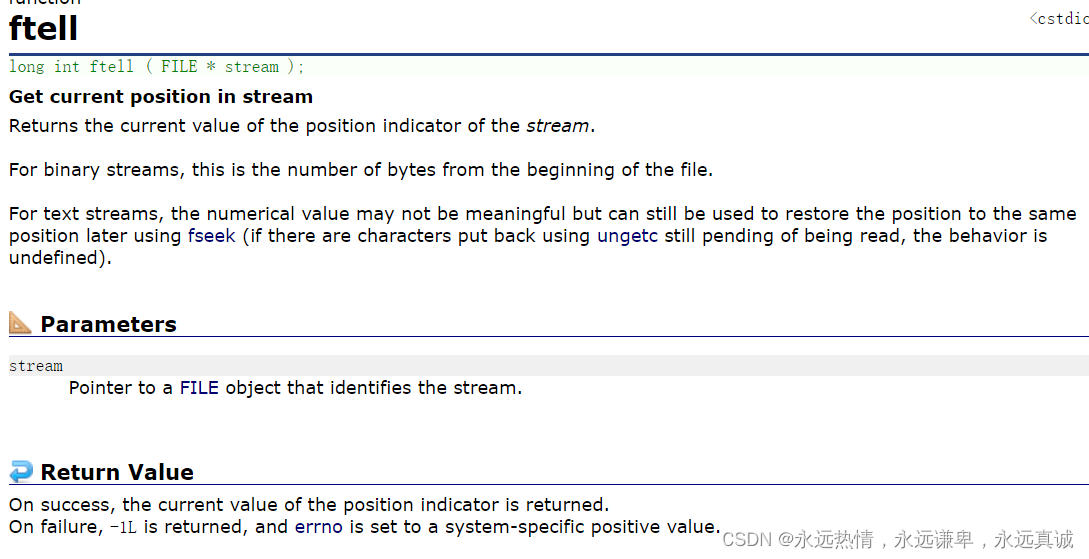
ftell函数会返回当前文件指针在流中的位置,它只有一个FILE类型的参数。
// 主函数入口
int main()
{
// 尝试以只读方式打开名为"data.txt"的文件,并将返回的文件指针保存在pf中
FILE* pf = fopen("data.txt", "r");
// 如果文件打开失败,pf将为NULL
if (NULL == pf)
{
// 打印文件打开失败的错误信息
perror("fopen");
// 返回错误码1并退出程序
return 1;
}
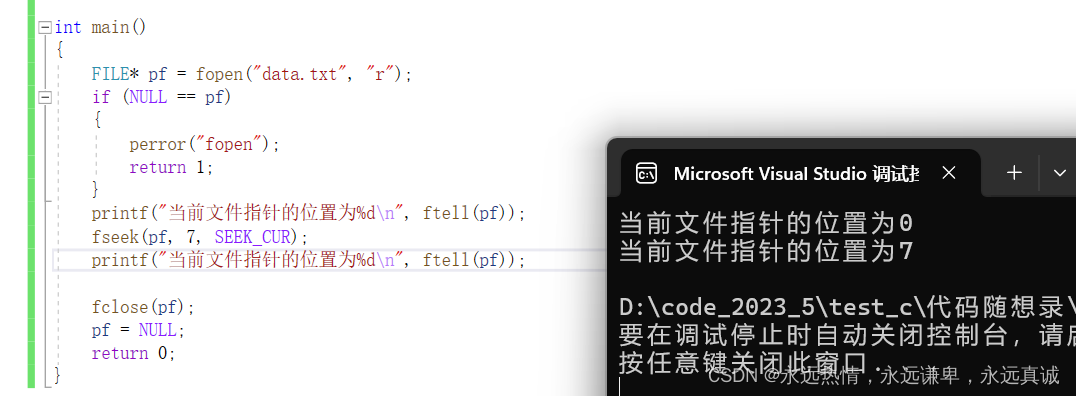
// 输出当前文件指针在文件中的位置(对于新打开的文件,通常是0,除非文件以特定模式打开)
printf("当前文件指针的位置为%ld\n", ftell(pf));
// 将文件指针从当前位置向前移动7个字节(注意:如果当前位置在文件开头7字节内,将发生错误)
fseek(pf, 7, SEEK_CUR);
// 输出移动后文件指针在文件中的位置
printf("当前文件指针的位置为%ld\n", ftell(pf));
// 关闭文件
fclose(pf);
// 将文件指针置为NULL,防止野指针
pf = NULL;
// 程序正常结束,返回0
return 0;
}
运行结果:
🍵 ungetc函数
ungetc这个函数一般是用于读模式,它会撤销上一次因为读导致文件指针后移一位的操作,同时把上一个文件指针指向的字符修改为我们指定的字符,注意这个函数只是改变了流中的数据,并没有改变文件本身的数据,因为文件和流是相互连通的,文件在磁盘中,和电脑进行交互需要先把数据放到流中或者在流中去拿。我们所说的文件指针其实也不是FILE*类型,而是它里面有一个成员指针,是指向那片空间的。
下面我们用代码来演示一下这个函数:
#include <stdio.h>
int main() {
FILE* pFile; // 文件指针
int c; // 用于存储getc读取的单个字符
char buffer[256]; // 字符数组用于存储fgets读取的行
// 以文本模式打开data.txt文件
pFile = fopen("data.txt", "rt");
if (pFile == NULL) {
// 如果文件打开失败,打印错误信息并返回1
perror("fopen");
return 1;
} else {
// 循环读取文件直到文件末尾
while (!feof(pFile)) {
// 读取单个字符
c = getc(pFile);
// 如果读取到文件结束符EOF,则跳出循环
if (c == EOF) break;
// 如果读取到'#',则试图将'@'放回到文件(这里逻辑可能存在问题)
if (c == '#') ungetc('@', pFile);
else // 否则,将读取的字符c放回到文件
ungetc(c, pFile);
// 尝试读取一行数据到buffer中
if (fgets(buffer, 255, pFile) != NULL) {
// 如果读取成功,则打印该行
fputs(buffer, stdout);
} else {
// 如果读取失败(通常是因为已经到达文件末尾),则跳出循环
break;
}
}
}
// 关闭文件
fclose(pFile);
// 程序正常结束
return 0;
}
上述代码每行先读一个字符,如果已经结束就跳出程序,如果读到的是字符’#‘,就使用ungetc函数撤销这一次读操作文件指针
−
−
--
−−,并在对应流的位置更改字符’#‘为’@‘,这样每一行的首字符如果是’#‘就会全部被替换为’@‘,如果不是就把原来的字符放回去。我们在文件中提前放好了下面的字符:
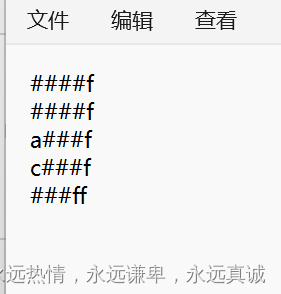
我们来看运行结果:

和我们预期的一致。
我们通过读文档,了解到了这个函数需要注意的几个地方:
-
如果在使用
ungetc函数后使用了fseek等可以刷新流的函数,ungetc函数的替换操作将会撤销,但是文件指针不会改变(如果我们的刷新函数没有改变文件指针的位置的话还是原位置)。 -
一些库里面支持连续多次调用此函数,注意这是没有可移植性的,因为除了第一次的调用,其余的调用都可能失败,因为如果你试图放入超出流限制的字符时,会发生未定义行为,连续调用可读性也不强。
-
二进制模式下,该函数一般是正常行为;但是在文本模式下,使用该函数时文件指针的位置是不确定的,因为有特殊字符的存在。
🍵 rewind函数
rewind函数的作用是将文件指针的位置设置到起始位置,文档中也谈到:函数成功调用之后,文件指针之前如果处于文件结尾位置或者是错误的位置,将会被清除(回到起始位置),之前ungetc函数对流的全部影响也会消失,还可以用于读写模式之间的读和写的切换。
我们用代码来演示一下rewind函数的使用:
#include <stdio.h>
int main()
{
// 尝试以只读模式打开名为"data.txt"的文件,并将文件指针赋值给pf
FILE* pf = fopen("data.txt", "r");
// 如果文件打开失败,则打印错误信息并返回1
if (NULL == pf)
{
perror("fopen"); // 打印fopen的错误信息
return 1; // 返回错误码1
}
// 定义一个字符数组Buffer,用于存储从文件中读取的一行内容,并初始化为0(即空字符串)
char Buffer[160] = { 0 };
// 从pf指向的文件中读取一行内容到Buffer数组中,最多读取sizeof(Buffer)-1个字符
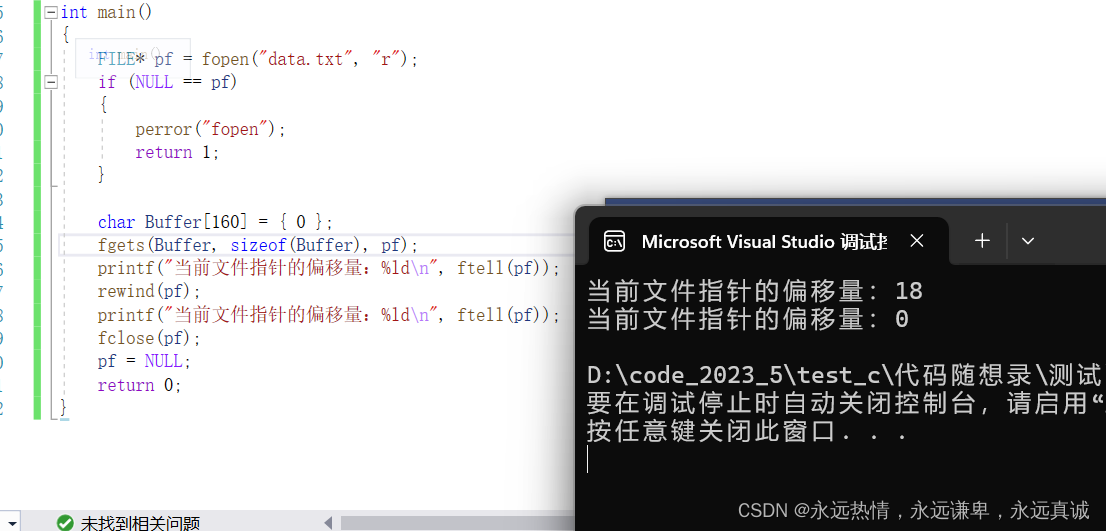
fgets(Buffer, sizeof(Buffer), pf);
// 打印当前文件指针在文件中的偏移量(即当前读取位置)
printf("当前文件指针的偏移量:%ld\n", ftell(pf));
// 使用rewind函数将文件指针重置到文件的开头
rewind(pf);
// 打印重置后的文件指针的偏移量(应该为0,表示文件开头)
printf("当前文件指针的偏移量:%ld\n", ftell(pf));
// 关闭文件
fclose(pf);
// 将文件指针置为NULL,防止野指针
pf = NULL;
// 程序正常结束,返回0
return 0;
}
运行结果:
📘 二进制文件和文本文件
🍵 文本文件
定义:文本文件是以人类可读的字符形式存储数据的文件。这些字符可以是字母、数字、标点符号等,通常遵循某种字符编码标准(如ASCII、UTF-8等)。
🍵 二进制文件
定义:二进制文件是以二进制格式(即0和1的组合)存储数据的文件。这些数据可以是任何类型,包括文本、图像、音频、视频等。
通常如果要将数据以文本的形式输出到磁盘中,就需要将二进制的数据先转换成ASCII码的形式,以ASCII字符的形式存储的文件就是文本文件。但是二进制文件不用转换,所以输出二进制文件到磁盘中比输出文本文件要快。

📘 文件如何判定已经读取结束
🍵 文本文件
fgetc函数
读取结束返回EOFfgets
读取结束返回NULL
🍵 二进制文件
fread函数
通过检查读取的个数与我们实际要读的个数是否相等来判断结束。
注意:文件结束有两种情况:1、文件到达文件末尾正常结束 2、文件读取发生错误结束。
这两种情况我们可以通过函数feof和函数ferror来区分。
🍵 feof函数
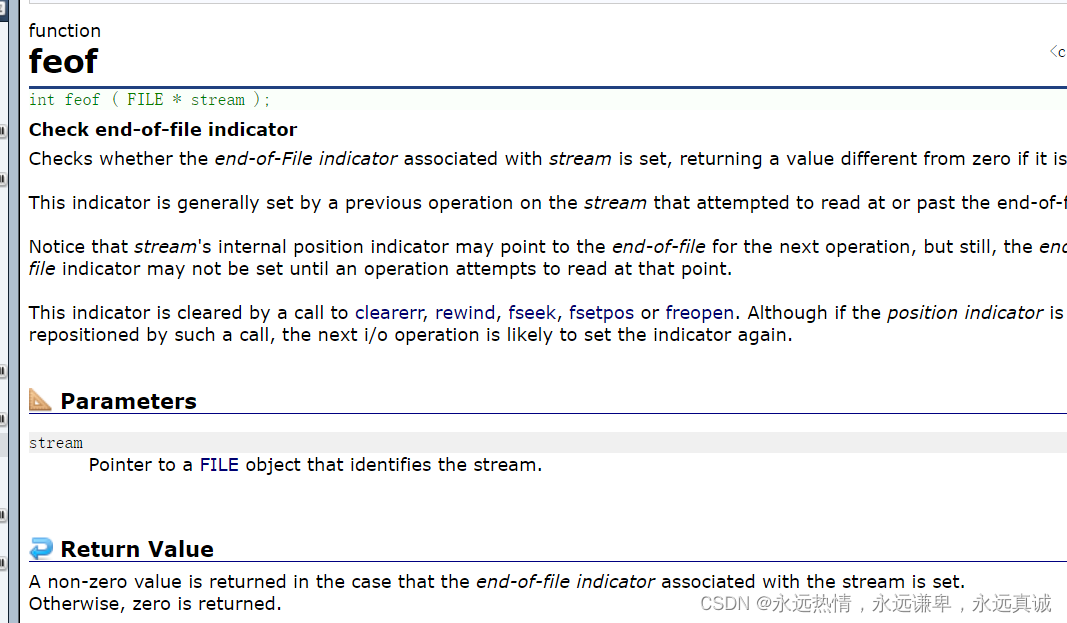
feof函数是用来检查文件是否到达文件末尾的,如果文件到达了文件末尾就会返回一个非0值,否则就会返回0。
所以不能通过feof函数的返回值来判断结束,因为文件在读取中可能发生错误没有到达文件末尾,但是文件实际已经读取结束了,我们的程序会陷入死循环。
🍵 ferror函数
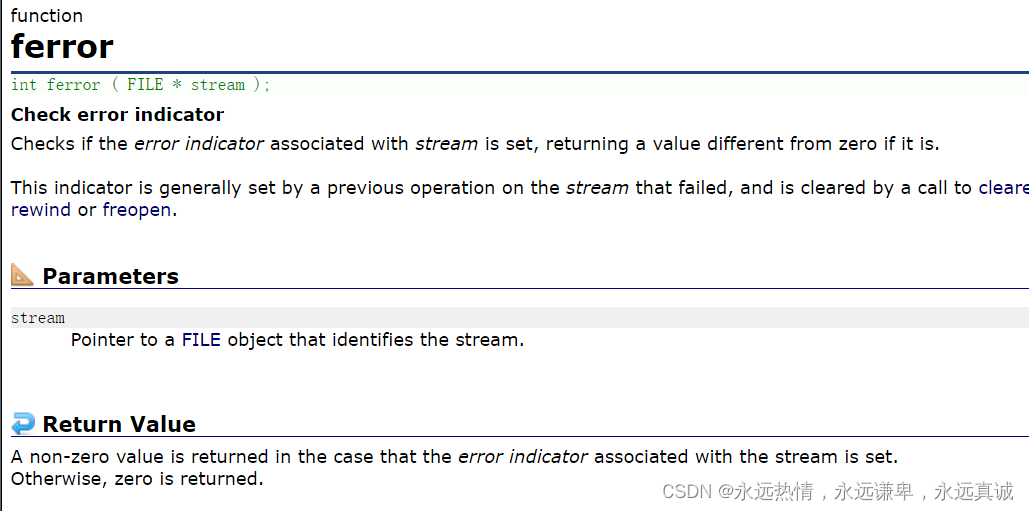
ferror函数是用来检查文件是否是因为读取或者写入失败而结束读取的,如果是因为读取失败而结束读取,这个函数会返回一个非零值,否则会返回0。
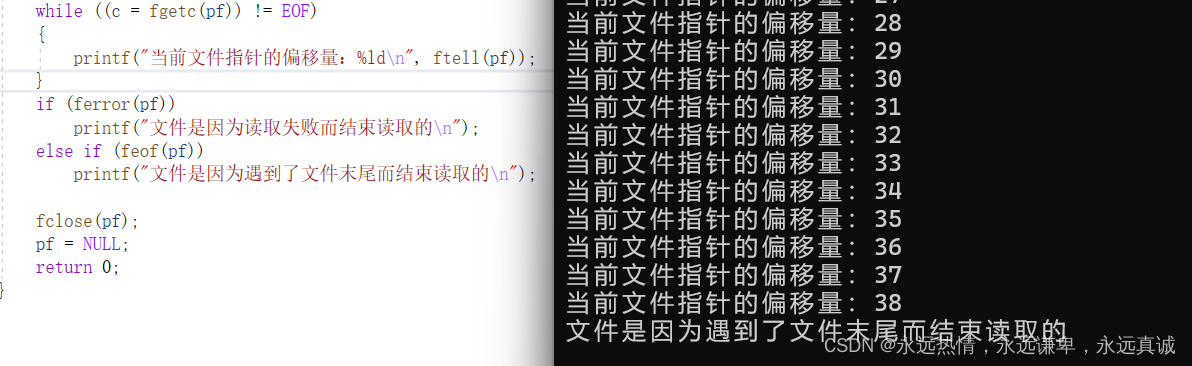
我们来写一段代码来演示一下这两个函数:
#include <stdio.h>
int main()
{
FILE* pf = fopen("data.txt", "r");
if (NULL == pf)
{
perror("fopen\n");
return 1;
}
char c = '\0';
while ((c = fgetc(pf)) != EOF)
{
printf("当前文件指针的偏移量:%ld\n", ftell(pf));
}
if (ferror(pf))
printf("文件是因为读取失败而结束读取的\n");
else if (feof(pf))
printf("文件是因为遇到了文件末尾而结束读取的\n");
fclose(pf);
pf = NULL;
return 0;
}
运行结果:
📘 文件缓冲区
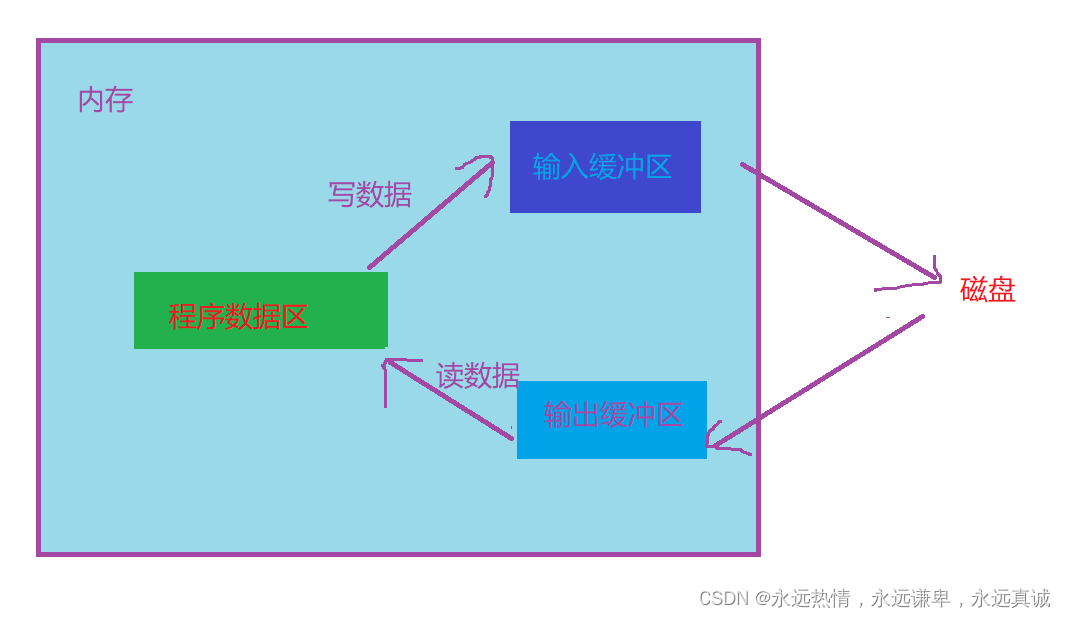
文件缓冲区是内存中预留的一定空间,用于暂时存放读写期间的文件数据。它的主要目的是减少读取硬盘的次数,从而提高数据处理的效率。由于CPU与I/O设备(如硬盘)之间的速度存在显著的差异,CPU的运算速率远高于I/O设备的速率。为了缓和这种速度不匹配的矛盾,引入了文件缓冲区的概念。当需要从硬盘中读取数据时,不是直接逐个字符地读取,而是先从磁盘中读取大量信息,并将这些信息存储在缓冲区中,然后程序再从缓冲区中逐个读取字节。这种方式可以显著提高读取数据的速度。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











