







总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs、mapreduce等主从关系。
1、这里我搭建一个由三台虚拟机组成的集群,版本为CentOs7
192.168.124.130 hadoop/123456 master
192.168.124.131 hadoop/123456 slave01
192.168.124.132 hadoop/123456 slave02
1.1 上面各列分别为IP、user/passwd、hostname
1.2 Hostname、hosts分别在/etc/hostname、/etc/hosts中修改,
对于三台机器都需要修改:
下面是master的修改:通过命令
vi /etc/hostname修改master的hostname如下:
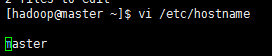
另两台服务器修改为相应名字即可
vi /etc/hosts修改master的hosts如下
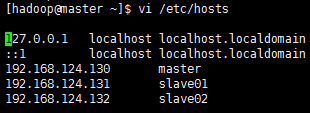
复制该hosts到另两台服务器
2、配置master到slave节点的SSH无密码登陆
2.1使用命令:ssh-keygen -t dsa 然后三个回车,如图
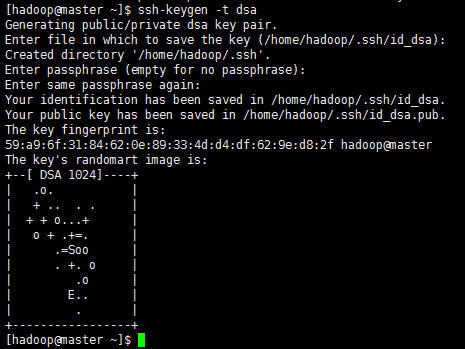
完成后在/home/hadoop/.ssh/目录下面会有两个文件
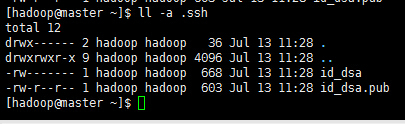
2.2把公钥文件写入授权文件中cat id_dsa.pub >> authorized_keys
赋权限
chmod -R 700 /home/hadoop/.ssh
chmod 600 authorized_keys至此ssh配置成功(slave01和slave02使用同样的方法),
使用ssh localhost 验证,输入yes
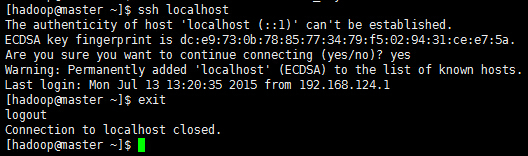
上面的原理,就是我把工钥放到里面,然后本台机器就可以ssh无密码登录了。如果想彼此无密码登录,那么就需要把彼此的工钥(*.pub)放到authorized_keys里面
2.3接下来把Master的公钥文件通过scp拷贝到已经创建好的Slave节点的hadoop用户上
scp .ssh/authorized_keys slave01:~/.ssh
scp .ssh/authorized_keys slave02:~/.ssh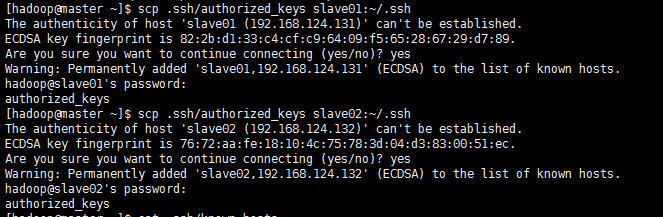
这样master就可以免密码登录到slave01和slave02了


3、安装JDK
(1)下载“jdk-7u79-linux-x64.gz”,放到/home/java目录下
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
(2)解压,输入命令,tar -zxvf jdk-7u79-linux-x64.gz
(3)编辑/etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin (4)使配置生效,输入命令,source /etc/profile
(5)输入命令,java -version,完成
4、hadoop集群中每个机器上面的配置基本相同,所以我们先在master上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。
【注意】:master和slaves安装的hadoop路径要完全一样,用户和组也要完全一致
(1)下载“hadoop-2.7.1.tar.gz”,放到/home/hadoop目录下
(2)解压,输入命令,tar -xzvf hadoop-2.7.1.tar.gz
(3)在/home/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
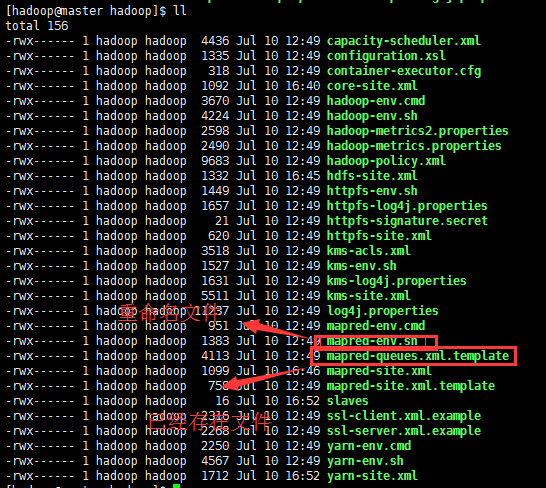
(4)这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上文件默认不存在的,可以复制相应的template文件获得。下面举例:
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_79)
配置文件2:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_79)
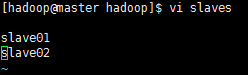
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
配置文件4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
配置文件5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件6:mapred-site.xml
<configuration>
<property> <name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
复制到其他节点
上面配置完毕,我们基本上完成了90%了剩下就是复制。我们可以把整个hadoop复制过去:使用如下命令:
scp -r /home/hadoop/hadoop-2.7.1 hadoop@slave01:~/
scp -r /home/hadoop/hadoop-2.7.1 hadoop@slave02:~/
5.配置环境变量
第一步:vi /etc/environment
第二步:添加如下内容:记得如果你的路径改变了,你也许需要做相应的改变。
6.启动验证
启动hadoop
格式化namenode:hdfs namenode –format
或则使用下面命令:hadoop namenode format
启动hdfs:start-dfs.sh
此时在master上面运行的进程有:
namenode
secondarynamenode
slave节点上面运行的进程有:datanode
启动yarn:start-yarn.sh
我们看到如下效果:
master有如下进程:
slave1有如下进程:
此时hadoop集群已全部配置完成!!!
【注意】:而且所有的配置文件和节点处不要有空格,否则会报错!
然后我们输入:(这里有的同学没有配置hosts,所以输出master访问不到,如果访问不到输入ip地址即可)
http://master:8088/看到下图:
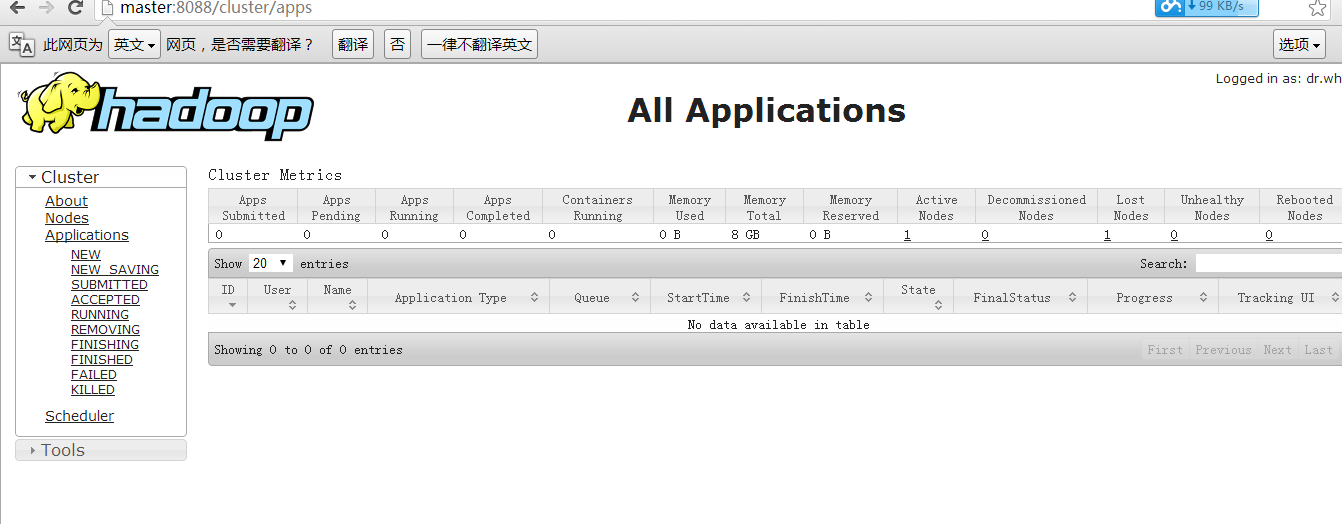
到此全部完毕。















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









