







 本文介绍了如何通过js代码识别使用Selenium+Webdriver的模拟浏览器,并讨论了网站如何阻止这种模拟。同时,提供了两种解决方案:编写Chrome插件或设置Chromedriver启动参数,以防止被识别为Selenium模拟浏览器。通过实验,这种方法成功地在不触发验证码的情况下登录了知乎。
本文介绍了如何通过js代码识别使用Selenium+Webdriver的模拟浏览器,并讨论了网站如何阻止这种模拟。同时,提供了两种解决方案:编写Chrome插件或设置Chromedriver启动参数,以防止被识别为Selenium模拟浏览器。通过实验,这种方法成功地在不触发验证码的情况下登录了知乎。
今天学到的新知识,开发爬虫的过程中使用Selenium + Chromedriver 也能很轻松的被js识别。
例:
使用下面这一段代码启动Chrome窗口:
from selenium import webdriver
import time
driver = webdriver.Chrome()
time.sleep(300)
driver.quit()
在这个窗口中打开开发者工具,并定位到Console选项卡,现在,在这个窗口输入如下的js代码:
window.navigator.webdriver
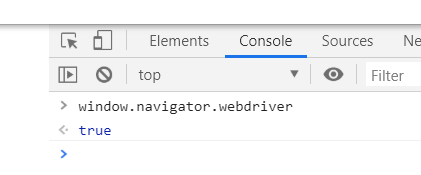
开发者工具返回了 true
但是,如果打开一个普通的Chrome窗口,执行相同的命令,可以发现返回值为undefined,如下图所示。
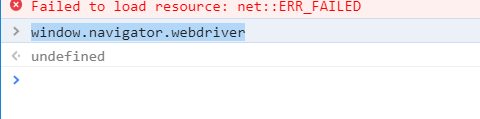
所以,如果网站通过js代码获取这个参数,返回值为undefined说明是正常的浏览器,返回 true 说明用的是Selenium模拟浏览器。
这里给出一个检测Selenium的js代码例子:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你以为使用Selenium模拟浏览器就没事了?')
} else {
console.log('正常浏览器')
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









