







什么是dict?
在 Redis 中,dict 是指哈希表(hash table)的一种实现,用于存储键值对数据。dict 是 Redis 中非常常用的数据结构之一,用于实现 Redis 的键空间。
在 Redis 源码中,dict 是一个通用的、高性能的哈希表实现,它采用开放寻址法(open addressing)作为冲突解决方案,并且具有良好的性能特征。
在 Redis 的源码中,dict 被用于实现 Redis 中的数据库、哈希键(hash key)等数据结构。通过 dict 这一数据结构,Redis 能够高效地实现键值对的存储和检索,保证了 Redis 的高性能和快速响应。
dict 在 Redis 中扮演着非常重要的角色,是支撑 Redis 数据存储和操作的基础之一。
核心特性
- 开放寻址法:Redis 中的字典采用了开放寻址法作为冲突解决方案。在发生哈希冲突时,它会通过线性探测(linear probing)的方式来寻找下一个可用的位置。
- 渐进式 rehashing:Redis 的字典实现中采用了渐进rehashing 策略,这意味着在进行扩容或缩小操作时,不会一次性地重新分配所有元素,而是逐步迁移键值对,以降低对服务的影响。
- 哈希表的大小:Redis 中的字典会根据当前包含的元素数量动态调整哈希表的大小,以保证较低的负载因子,从而保持较好的性能。
- 链表:在哈希表的每个槽位上,可以形成一个链表,用于处理哈希冲突时的多个元素。当链表长度过长时,Redis 会将链表转换为更高效的哈希表。
总的来说,Redis 中的字典通过哈希表实现,结合了开放寻址法、渐进式 rehashing 等策略,以及动态调整大小等特性,为 Redis 提供了高效的键值对存储和检索能力。这些特性使得 Redis 的字典在处理大量数据时依然能够保持良好的性能。
聚焦问题
1、dict的数据结构长什么样子,对比Java的HashMap
2、dict如何插入数据,并且如何解决hash冲突的
3、dict的rehash策略
dict的数据结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
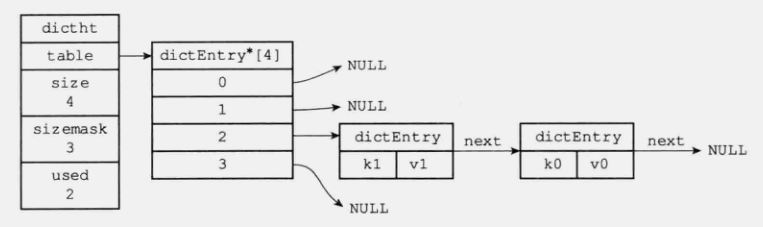
dict的本质是使用一个数组来存储key-value键值对,数组中的每个元素都是一个指向dictEntry结构的指针,而每一个dictEntry则保存了key-value键值对,是否听起来似曾相识,与Java中HashMap的结构非常相似
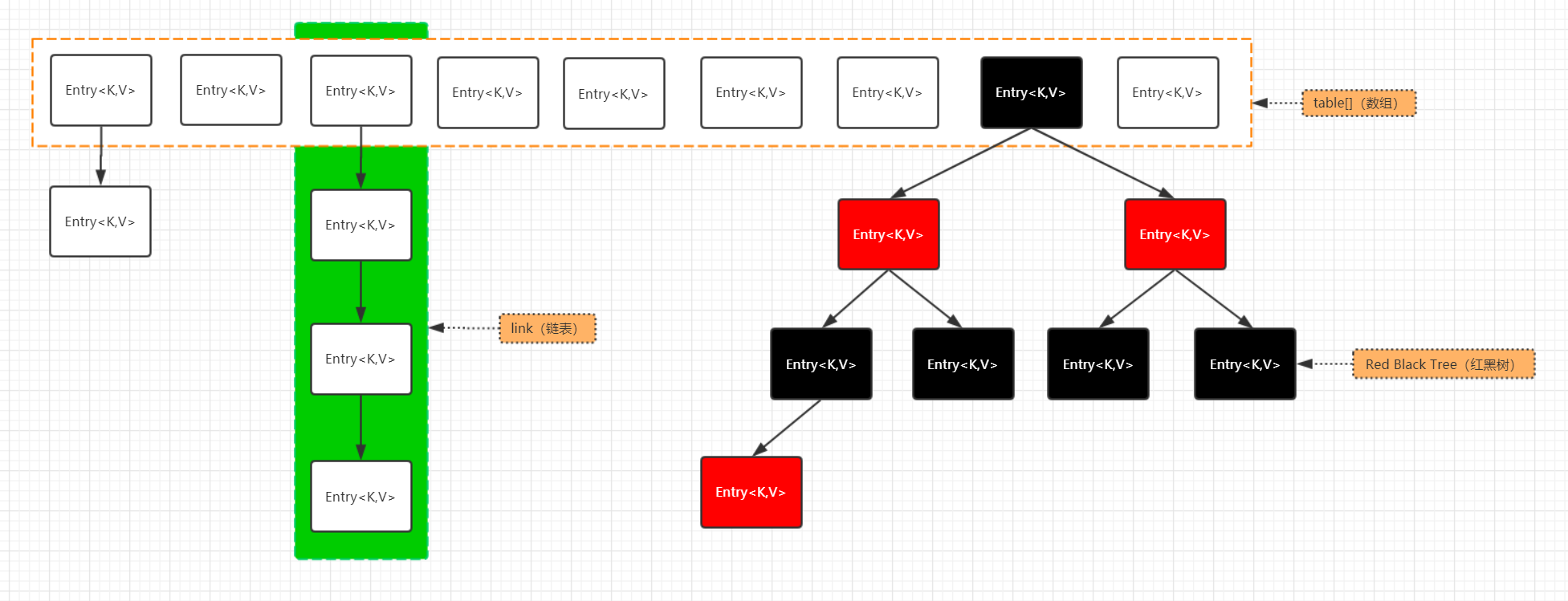
之所以说非常相似,而不是一模一样,是因为关于hash寻址冲突后,对同一个数组位置上元素的存储结构,并不完全一致,HashMap对于同一个数组位置的元素初始会使用链表的形式组装,而链表的长度达到一定阈值后,则转为红黑树的形式组装。
而dict并没有这种处理方式,仅会使用链表组织元素,这样的好处显而易见,链表的实现难度一定是比红黑树简单,也更易于调试,但是对与hash寻址算法的要求也更高,需要尽可能的保证少量的hash冲突,即寻址计算尽可能分散,否则链表长度过长,会影响取值的效率。
渐进式rehash
Redis 使用渐进式 rehash 来实现哈希表的扩容和缩容。渐进式 rehash 是一种在 Redis 服务不中断的情况下进行哈希表 rehash 的方法,它将 rehash 操作分解成多个小步骤,每次执行一小部分 rehash 操作,以避免阻塞服务。
渐进式 rehash 的主要步骤如下:
- 创建新哈希表: 当需要进行哈希表扩容或缩容时,Redis 首先会创建一个新的哈希表,其大小为原哈希表的两倍或更小。
- 迁移数据: 然后,Redis 会将原哈希表中的数据逐步迁移到新哈希表中。每次迁移一小部分数据,而不是一次性全部迁移。这样做的好处是,在迁移的过程中,Redis 仍然可以接受读取请求,并且只有在写入数据时才会阻塞。
- 逐步完成: 当所有的数据都迁移完成后,Redis 将原哈希表替换为新哈希表。这个过程是逐步进行的,不会中断服务。
渐进式 rehash 的优点包括:
- 减少阻塞时间: 由于将 rehash 操作分解成多个步骤执行,因此可以大大减少阻塞时间,提高系统的稳定性和可用性。
- 逐步进行: rehash 操作是逐步进行的,可以平滑地将数据从旧哈希表迁移到新哈希表,不会对系统造成过大的负担。
- 保证读写服务: 在 rehash 过程中,Redis 仍然可以提供读取服务,只有在写入数据时才会阻塞。
需要注意的是,虽然渐进式 rehash 可以减少阻塞时间,但在 rehash 过程中,仍然会占用一定的系统资源,可能会对性能产生一定的影响。因此,在进行 rehash 操作时,需要谨慎安排时间,并在低负载时执行。
下面我们来一起看一下,具体实现逻辑:
/* This function handles 'background' operations we are required to do
* incrementally in Redis databases, such as active key expiring, resizing,
* rehashing. */
void databasesCron(void) {
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1) {
static unsigned int resize_db = 0;
static unsigned int rehash_db = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
int j;
/* Don't test more DBs than we have. */
if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
/* Resize */
for (j = 0; j < dbs_per_call; j++) {
tryResizeHashTables(resize_db % server.dbnum);
resize_db++;
}
/* Rehash */
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
// rehash执行
int work_done = incrementallyRehash(rehash_db % server.dbnum);
rehash_db++;
if (work_done) {
/* If the function did some work, stop here, we'll do
* more at the next cron loop. */
break;
}
}
}
}
}
int incrementallyRehash(int dbid) {
/* Keys dictionary */
if (dictIsRehashing(server.db[dbid].dict)) {
dictRehashMilliseconds(server.db[dbid].dict,1);
return 1; /* already used our millisecond for this loop... */
}
/* Expires */
if (dictIsRehashing(server.db[dbid].expires)) {
dictRehashMilliseconds(server.db[dbid].expires,1);
return 1; /* already used our millisecond for this loop... */
}
return 0;
}
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
// 每次执行100次,这就是渐进
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 注意此处的边界条件,每次传入100,也就是只会执行100次循环
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
rehash开始
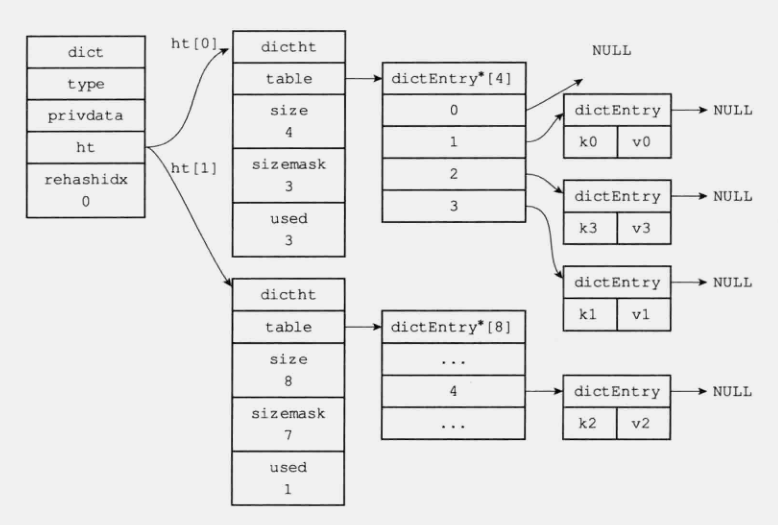
rehash结束

Redis的dict与Java中的HashMap,实现上有什么区别
Redis 的 dict 是在 C 语言中实现的字典结构,而 Java 中的 HashMap 是在 Java 编程语言中实现的哈希表结构。它们之间有以下几个主要区别:
- 语言差异:dict 是 Redis 自行实现的数据结构,使用 C 语言编写。而 HashMap 是 Java 标准库中提供的类,使用 Java 编写。
- 内存管理:Redis 的 dict 使用了手动内存管理,需要手动分配和释放内存空间。而 Java 的 HashMap 使用垃圾回收机制自动管理内存,无需手动处理。
- 线程安全性:Redis 的 dict 不是线程安全的,如果多个线程同时对同一个 dict 进行读写操作,可能会导致数据不一致或者程序崩溃。而 Java 的 HashMap 是非线程安全的,但可以通过使用 ConcurrentHashMap 等线程安全的 Map 实现来解决并发访问的问题。
- 扩容机制:Redis 的 dict 在进行扩容时使用了渐进式 rehash 算法,将扩容操作分摊到多个操作中,避免了大规模数据迁移带来的性能问题。而 Java 的 HashMap 在扩容时需要重新计算哈希值,并将元素重新分布到新的桶位中。
- 功能差异:Redis 的 dict 是为了满足 Redis 数据库的需要而设计的,支持一些特定的功能,如过期时间等。Java 的 HashMap 是通用的哈希表实现,提供了丰富的方法和功能,适用于多种应用场景。
总体而言,Redis 的 dict 和 Java 的 HashMap 在实现上有一些差异,主要是因为它们所运行的环境和使用的编程语言不同。它们在性能、线程安全性、扩容策略等方面都有各自的特点和优化。
Redis dict的rehash和Java HashMap的rehash,有什么不同
Redis 的 dict 和 Java 的 HashMap 在 rehash(重新哈希)操作上有一些区别:
- 触发条件:Redis 的 dict 在进行 rehash 操作时,是在字典的负载因子(load factor)超过阈值时触发的,即元素数量超过容量的一定比例。而 Java 的 HashMap 在进行 rehash 操作时,是在桶位(buckets)的使用情况超过阈值时触发的,即某个桶位中元素的数量超过链表长度的阈值(8)。
- 扩容方式:Redis 的 dict 采用了渐进式 rehash 算法,将扩容操作分摊到多个操作中,避免了大规模数据迁移带来的性能问题。具体而言,dict 在进行 rehash 时会逐步将 ht[0] 中的元素迁移到 ht[1] 中,直到完成整个 rehash 过程。而 Java 的 HashMap 使用的是一次性扩容的方式,在 rehash 时会创建一个更大的桶位数组,并将所有元素重新计算哈希值后放入新的桶位中。
- 并发处理:Redis 的 dict 在 rehash 过程中,仅支持单线程执行,不支持并发访问。这意味着在 rehash 过程中,不能同时进行读取和写入操作,否则可能导致数据不一致。而 Java 的 HashMap 在 rehash 过程中,不会影响并发访问的正常进行。通过使用读写锁或者分段锁等机制,可以在不阻塞其他线程的情况下进行并发读取和写入操作。
Redis 的 dict 和 Java 的 HashMap 在 rehash 操作上有一些差异。Redis 的 dict 使用了渐进式 rehash 算法,避免了大规模数据迁移带来的性能问题,但不支持并发访问。而 Java 的 HashMap 在 rehash 过程中可以进行并发访问,但需要一次性扩容,并重新计算哈希值。这些差异是由于它们所处的环境和应用场景的不同导致的。















 1720
1720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









