







前言
学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强
- 学习文档:
-
接口文档:谷粒商城接口文档
- 本内容仅用于个人学习笔记,如有侵扰,联系删除
三、商城业务-首页
1、整合thymeleaf渲染首页
1.1、在gulimall-product项目中导入前端代码

项目微服务

项目在发布的时候,将静态资源放到nginx中,实现动静分离
引入"thymeleaf"依赖:
前端使用了thymeleaf开发,因此要导入该依赖,并且为了改动页面实时生效导入devtools
修改pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>将静态资源放入到static文件夹下,而将index.html放入到templates文件夹下:

在“application.yml”文件中设置thymeleaf,关闭thymeleaf缓存,路径为:spring.thymeleaf.cache
spring:
thymeleaf:
cache: false同时将“controller”修改为app,以后它都是被移动APP所访问的地方。
创建web文件夹:

启动“gulimall-product”服务,根据路径就可以直接访问静态资源

在静态资源目录static下的资源,可以直接访问,如:http://localhost:10000/index/css/GL.css

SpringBoot在访问项目的时候,会默认找到index文件夹下的文件。
这些规则是配置在“ResourceProperties”文件中指定的:
private static final String[] CLASSPATH_RESOURCE_LOCATIONS = { "classpath:/META-INF/resources/",
"classpath:/resources/", "classpath:/static/", "classpath:/public/" };
关于欢迎页,它是在静态文件夹中,寻找index.html页面的:
org.springframework.boot.autoconfigure.web.servlet.WebMvcAutoConfigurationprivate Optional<Resource> getWelcomePage() {
String[] locations = getResourceLocations(this.resourceProperties.getStaticLocations());
return Arrays.stream(locations).map(this::getIndexHtml).filter(this::isReadable).findFirst();
}
private Resource getIndexHtml(String location) {
return this.resourceLoader.getResource(location + "index.html");
}1.2、渲染一级分类数据&&整合dev-tools
现在想要实现的效果是访问http://localhost:10000/index.html能访问,另外当
在thymeleaf中,默认的访问的前缀和后缀
//前缀
public static final String DEFAULT_PREFIX = "classpath:/templates/";
//后缀
public static final String DEFAULT_SUFFIX = ".html";当controller中返回的是一个视图地址,它就会使视图解析器进行拼串。
查询出所有的一级分类:
1)、渲染一级分类菜单
由于访问首页时就要加载一级目录,所以我们需要在加载首页时获取该数据
修改“com.atguigu.gulimall.product.web.IndexController”类,修改如下:
@Controller
public class IndexController {
@Autowired
private CategoryService categoryService;
@GetMapping({"/", "index.html"})
public String getIndex(Model model) {
// 获取所有的一级分类
List<CategoryEntity> categories = categoryService.getLevel1Categories();
model.addAttribute("categories", categories);
return "index";
}
}
修改“com.atguigu.gulimall.product.service.CategoryService”类,修改如下:
List<CategoryEntity> getLevel1Categories(); 修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,修改如下:
@Override
public List<CategoryEntity> getLevel1Categories() {
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
return categoryEntities;
}2)、dev-tools实现不重启服务实时生效
1、添加devtools依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>2、编译页面
执行“ctrl+shift+F9”重新编译页面或“ctrl+F9”重新编译整个项目。
3、代码配置方面,还是建议重启服务
通过引入该devtools,能够实现在IDEA中修改了页面后,无效重启整个服务就可以实现刷新页面,但是在修改页面后,需要执行“ctrl+shift+F9”重新编译页面或“ctrl+F9”重新编译整个项目。
thymeleaf下载地址:https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.pdf
渲染页面index.html页面:
引入Thymeleaf
<html lang="en" xmlns:th="http://www.thymeleaf.org">页面遍历菜单数据
<div class="header_main_left">
<ul>
<li th:each="category : ${categories}">
<a href="#" class="header_main_left_a" ctg-data="3" th:attr="ctg-data=${category.catId}"><b th:text="${category.name}">家用电器111</b></a>
</li>
</ul>
</div>1.3、渲染二级三级分类数据
首页加载的数据默认来自于静态资源的“index/json/catalog.json”,现在需要让它从数据库实时读取
此处改为index/catalog.json

添加“com.atguigu.gulimall.product.web.IndexController”类,代码如下:
@ResponseBody
@GetMapping("/index/catalog.json")
public Map<String, List<Catelog2Vo>> getCatalogJson(){
Map<String, List<Catelog2Vo>> catalogJson = categoryService.getCatalogJson();
return catalogJson;
}添加“com.atguigu.gulimall.product.vo.Catelog2Vo”类,代码如下:
//二级分类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Catelog2Vo {
private String catelog1Id; //一级父分类id
private List<Catalog3Vo> catalog3List; //三级子分类
private String id;
private String name;
//三级分类
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Catalog3Vo{
private String catelog2Id; //父分类,2级分类id
private String id;
private String name;
}
}修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,代码如下:
/**
* 逻辑是
* (1)根据一级分类,找到对应的二级分类
* (2)将得到的二级分类,封装到Catelog2Vo中
* (3)根据二级分类,得到对应的三级分类
* (3)将三级分类封装到Catalog3List
*
* @return
*/
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getLevel1Categories();
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", l2.getCatId()));
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}测试:http://localhost:10000/index/catelog.json
2、搭建域名访问环境
2.1、nginx-搭建域名访问环境一(反向代理配置)
- 正向代理和反向代理

- Nginx+windows搭建域名访问环境

修改本地的C:\Windows\System32\drivers\etc\hosts文件,添加域名映射规则:
先把只读模式去掉,才可以编辑

192.168.119.127 gulimall.com
192.168.119.127 为Nginx所在的设备

测试Nginx的访问:http://gulimall.com/

- 关于Nginx的配置文件:


user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}注意这里的“include /etc/nginx/conf.d/*.conf;”,它是将“/etc/nginx/conf.d/*.conf”目录下的所有配置文件包含到nginx.conf文件中。下面是该文件的内容:

server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}在Nginx上配置代理,使得所有到gulimall.com的请求,都转到gulimall-product服务。
现在需要明确部署情况,我们的nginx部署在192.168.119.127(虚拟机ip)上,而且是以docker容器的方式部署的,部署时将本机的/mydata/nginx/conf/挂载到了nginx容器的“/etc/nginx ”目录,gulimall-product服务部署在192.168.0.101(主机ip)上。
在192.168.119.127上创建“gulimall.conf”文件:


修改配置文件完毕后,重启nginx。

整个的数据流是这样的:浏览器请求gulimall.com,在本机被解析为192.168.119.127(虚拟机ip),192.168.119.127的80端口接收到请求后,解析请求头求得host,在然后使用在“gulimall.conf”中配置的规则,将请求转到"http://192.168.0.101:10001/"(主机ip),然后该服务响应请求,返回响应结果。
但是这样做还是有些不够完美,“gulimall-product”可能部署在多台服务器上,通常请求都会被负载到不同的服务器上,这里我们直接指定一台设备的方式,显然不合适。
2.2、nginx-搭建域名访问环境二(负载均衡到网关)
1)、关于Nginx的负载均衡
使用Nginx作为Http负载均衡器
http://nginx.org/en/docs/http/load_balancing.html
默认的负载均衡配置:
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}In the example above, there are 3 instances of the same application running on srv1-srv3. When the load balancing method is not specifically configured, it defaults to round-robin. All requests are proxied to the server group myapp1, and nginx applies HTTP load balancing to distribute the requests.
在上面的例子中,同一个应用程序有3个实例在srv1-srv3上运行。如果没有特别配置负载平衡方法,则默认为 round-robin。所有请求都代理到服务器组myapp1, nginx应用HTTP负载平衡来分发请求。
Reverse proxy implementation in nginx includes load balancing for HTTP, HTTPS, FastCGI, uwsgi, SCGI, memcached, and gRPC.
nginx中的反向代理实现包括HTTP、HTTPS、FastCGI、uwsgi、SCGI、memcached和gRPC的负载均衡。
To configure load balancing for HTTPS instead of HTTP, just use “https” as the protocol.
要为HTTPS而不是HTTP配置负载平衡,只需使用“HTTPS”作为协议。
When setting up load balancing for FastCGI, uwsgi, SCGI, memcached, or gRPC, use fastcgi_pass, uwsgi_pass, scgi_pass, memcached_pass, and grpc_pass directives respectively.
在为FastCGI、uwsgi、SCGI、memcached或gRPC设置负载均衡时,分别使用fastcgi_pass、uwsgi_pass、scgi_pass、memcached_pass和grpc_pass指令。
2)、配置负载均衡
1、修改“/mydata/nginx/conf/nginx.conf”,添加如下内容


注意:这里的88端口为“gulimall-gateway”服务的监听端口,也即访问“gulimall-product”服务通过该网关进行路由。
2、修改“/mydata/nginx/conf/conf.d/gulimall.conf”文件


3、在“gulimall-gateway”添加路由规则
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com注意:这个路由规则,一定要放置到最后,否则会优先进行Host匹配,导致其他路由规则失效。
4、配置完成后,重启Nginx,再次访问
docker restart nginx
再次访问的时候,返回404状态码

但是通过niginx请求“gulimall-product”服务的其他controller却能够顺利访问。
http://gulimall.com/api/product/category/list/tree

原因分析:Nginx代理给网关的时候,会丢失请求头的很多信息,如HOST信息,Cookie等。
解决方法:需要修改Nginx的路径映射规则,加上“ proxy_set_header Host $host;”
However, if this field is not present in a client request header then nothing will be passed. In such a case it is better to use the $host variable - its value equals the server name in the “Host” request header field or the primary server name if this field is not present:
proxy_set_header Host $host;
修改“gulimall.conf”文件


重启Nginx容器,再次访问Success:
docker restart nginx
- 域名映射效果
- 请求接口 gulimall.com
- 请求页面 gulimall.com
- nginx直接代理给网关,网关判断
- 如果/api/****,转交给对应的服务器
- 如果是 满足域名,转交给对应的服务
3、性能压测与优化
3.1、压力测试
3.1.1、性能指标
- 响应时间(Response Time: RT) :响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。
- HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
- TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
- QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
- 对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一 般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。
- 无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
- 金融行业:1000TPS~50000TPS,不包括互联网化的活动
- 保险行业:100TPS~100000TPS,不包括互联网化的活动
- 制造行业:10TPS~5000TPS
- 互联网电子商务:10000TPS~1000000TPS
- 互联网中型网站:1000TPS~50000TPS
- 互联网小型网站:500TPS~10000TPS
- 最大响应时间(Max Response Time) 指用户发出请求或者指令到系统做出反应(响应)的最大时间。
- 最少响应时间(Mininum ResponseTime) 指用户发出请求或者指令到系统做出反应(响应)的最少时间。
- 90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第 90%的响应时间。
- 从外部看,性能测试主要关注如下三个指标:
- 吞吐量:每秒钟系统能够处理的请求数、任务数。
- 响应时间:服务处理一个请求或一个任务的耗时。
- 错误率:一批请求中结果出错的请求所占比例。
3.1.2、JMeter
jmeter压力测试工具
1)、JMeter 安装
https://jmeter.apache.org/download_jmeter.cgi
2)、JMeter 压测示例

 线程组参数详解:
线程组参数详解:
- 线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
- Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为 10,准备时长为 2,那么需要 2 秒钟启动 10 个线程,也就是每秒钟启动 5 个线程。
- 循环次数:每个线程发送请求的次数。如果线程数为 10,循环次数为 100,那么每个线程发送 100 次请求。总请求数为 10*100=1000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
- Delay Thread creation until needed:直到需要时延迟线程的创建。
- 调度器:设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
- 持续时间(秒):测试持续时间,会覆盖结束时间
- 启动延迟(秒):测试延迟启动时间,会覆盖启动时间
- 启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
- 结束时间:测试结束时间,持续时间会覆盖它。
2、添加 HTTP 请求

 3、添加监听器
3、添加监听器

4、启动压测&查看分析结果

汇总图

结果分析
- Throughput 吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;若在压测的机器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的往下减,找到最佳的并发数;
- 压测结束,登陆相应的 web 服务器查看 CPU 等性能指标,进行数据的分析;
- 最大的 tps,不断的增加并发数,加到 tps 达到一定值开始出现下降,那么那个值就是最大的 tps。
- 最大的并发数:最大的并发数和最大的 tps 是不同的概率,一般不断增加并发数,达到一个值后,服务器出现请求超时,则可认为该值为最大的并发数。
- 压测过程出现性能瓶颈,若压力机任务管理器查看到的 cpu、网络和 cpu 都正常,未达到 90%以上,则可以说明服务器有问题,压力机没有问题。
- 数据库、应用程序、中间件(tomact、Nginx)、网络和操作系统等方面
- 首先考虑自己的应用属于 CPU 密集型还是 IO 密集型
3)、JMeter Address Already in use 错误解决
- cmd 中,用 regedit 命令打开注册表
- 在 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters 下
- 右击 parameters,添加一个新的 DWORD,名字为 MaxUserPort
- 然后双击 MaxUserPort,输入数值数据为 65534,基数选择十进制(如果是分布式运 行的话,控制机器和负载机器都需要这样操作哦)
- 修改配置完毕之后记得重启机器才会生效
3.2、性能监控
3.2.1、jvm 内存模型

- 程序计数器 Program Counter Register:
- 记录的是正在执行的虚拟机字节码指令的地址
- 此内存区域是唯一一个在JAVA虚拟机规范中没有规定任何OutOfMemoryError的区域
- 虚拟机:VM Stack
- 描述的是 JAVA 方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法接口等信息
- 局部变量表存储了编译期可知的各种基本数据类型、对象引用
- 线程请求的栈深度不够会报 StackOverflowError 异常
- 栈动态扩展的容量不够会报 OutOfMemoryError 异常
- 虚拟机栈是线程隔离的,即每个线程都有自己独立的虚拟机栈
- 本地方法:Native Stack
- 本地方法栈类似于虚拟机栈,只不过本地方法栈使用的是本地方法
- 堆:Heap
- 几乎所有的对象实例都在堆上分配内存

3.2.2、堆
- 新生代
- Eden 空间
- From Survivor 空间
- To Survivor 空间
- 老年代
- 永久代/元空间
- Java8 以前永久代,受 jvm 管理,java8 以后元空间,直接使用物理内存。因此,默认情况下,元空间的大小仅受本地内存限制。



3.2.3、jconsole 与 jvisualvm
1)、jvisualvm 能干什么

- cmd 启动 jvisualvm
- 工具->插件


- 如果 503 错误解决:
- 打开网址 https://visualvm.github.io/pluginscenters.html
- cmd 查看自己的 jdk 版本,找到对应的


- 复制下面查询出来的链接。并重新设置上即可

实例:如下面我们想要可视化GC的过程,可以安装这个插件

安装完成后,重启jvisualvm
然后连接我们的gulimall-product服务进程

在GC选项卡能够看到GC发生过程:

3.2.4、监控指标
1)、中间件指标

- 当前正在运行的线程数不能超过设定的最大值。一般情况下系统性能较好的情况下,线程数最小值设置 50 和最大值设置 200 比较合适。
- 当前运行的 JDBC 连接数不能超过设定的最大值。一般情况下系统性能较好的情况下,JDBC 最小值设置 50 和最大值设置 200 比较合适。
- GC频率不能频繁,特别是 FULL GC 更不能频繁,一般情况下系统性能较好的情况下,JVM 最小堆大小和最大堆大小分别设置 1024M 比较合适。
2)、数据库指标

- SQL 耗时越小越好,一般情况下微秒级别。
- 命中率越高越好,一般情况下不能低于 95%。
- 锁等待次数越低越好,等待时间越短越好。
3.2.5、JVM 分析&调优
1)、几个常用工具
|
jstack
|
查看
jvm
线程运行状态,是否有死锁现象等等信息
|
|
jinfo
|
可以输出并修改运行时的
java
进程的
opts
。
|
|
jps
|
与
unix
上的
ps
类似,用来显示本地的
java
进程,可以查看本地运行着几个
java程序,并显示他们的进程号。
|
|
jstat
|
一个极强的监视
VM
内存工具。可以用来监视
VM
内存内的各种堆和非堆的大小及其内存使用量。
|
|
jmap
|
打印出某个
java
进程(使用
pid
)内存内的所有
'
对象
'
的情况(如:产生那些对象,及其数量)
|
2)、命令示例
|
jinfo
是
JDK
自带的命令,可以用来查看正在运行的
java
应用程序的扩展参数,包括
Java System 属性和
JVM
命令行参数;也可以动态的修改正在运行的
JVM
一些参数。当系统崩溃时,jinfo
可以从
core
文件里面知道崩溃的
Java
应用程序的配置信息
| |
|---|---|
|
jinfo pid
|
输出当前
jvm
进程的全部参数和系统属性
|
|
jinfo -flag name pid
|
可以查看指定的
jvm
参数的值;打印结果:
-
无此参数,
+
有
|
|
jinfo -flag [+|-]name pid
|
开启或者关闭对应名称的参数(无需重启虚拟机)
|
|
jinfo -flag name=value pid
|
修改指定参数的值
|
|
jinfo -flags pid
|
输出全部的参数
|
|
jinfo -sysprops pid
|
输出当前
jvm
进行的全部的系统属性
|
|
jmap
可以生成
heap dump
文件,也可以查看堆内对象分析内存信息等,如果不使用这个命令,还可以使用-XX:+HeapDumpOnOutOfMemoryError
参数来让虚拟机出现
OOM
的时候自动生成 dump
文件。
| |
|---|---|
|
jmap -dump:live,format=b,file=dump.hprof pid
dump
堆到文件,
format
指定输出格式,
live
指明是活着的对象,
file
指定文件名。
eclipse
可以打开这个文件
| |
|
jmap -finalizerinfo pid
打印等待回收的对象信息
| |
|
jmap -histo:live pid
打印堆的对象统计,包括对象数、内存大小等。
jmap -histo:live
这个命令执行,JVM
会先触发
gc
,然后再统计信息
| |
|
jmap -clstats pid
打印
Java
类加载器的智能统计信息,对于每个类加载器而言,对于每个类加载器而言,它 的名称,活跃度,地址,父类加载器,它所加载的类的数量和大小都会被打印。此外,包含的字符串数量和大小也会被打印。
| |
|
-F
强制模式。如果指定的
pid
没有响应,请使用
jmap -dump
或
jmap -histo
选项。此模式下,不支持 live
子选项。
jmap -F -histo pid
|
|
jstack
是
jdk
自带的线程堆栈分析工具,使用该命令可以查看或导出
Java
应用程序中线程堆栈信息。
| |
|---|---|
|
jstack pid
|
输出当前
jvm
进程的全部参数和系统属性
|
3)、调优项

https://visualvm.github.io/uc/8u131/updates.xml.gz
3.3、性能优化
3.3.1、中间件对性能的影响
1、启动Jmeter
2、创建线程组
3、添加一个HTTP请求
这里我们测试Nginx的性能,先看Nginx是否能正常访问:

添加HTTP请求:

4、添加“查看结果树”,“汇总报告”和“聚合报告”
 5、在nginx所在的机器172.20.10.3上,执行docker stats
5、在nginx所在的机器172.20.10.3上,执行docker stats
通过docker stats命令,能够看到nginx容器的内存,cpu的占用情况

6、启动jmeter
大概50秒左右,停止jmeter
7、停止jmeter,查看报告
查看结果数,部分请求因socket关闭发送失败
 查看汇总报告
查看汇总报告

查看聚合报告

3.3.2、简单优化吞吐量测试
|
压测内容
|
压测线程数
|
吞吐量
/s
|
90%
响应时间
|
99%
响应时间
|
|---|---|---|---|---|
|
Nginx
| 50 | 2335 | 11 | 944 |
|
Gateway
| 50 | 10367 | 8 | 31 |
|
简单服务
| 50 | 11341 | 8 | 17 |
|
首页一级菜单渲染
| 50 | 270(db,thymeleaf) | 267 | 365 |
|
首页渲染(开缓存)
| 50 |
290
| 251 | 365 |
|
首页渲染(开缓存、
优化数据库、关日
志)
| 50 |
700
|
105
|
183
|
|
三级分类数据获取
| 50 |
2(db)/8(
加索引
)
|
...
|
...
|
|
首页全量数据获取
| 50 |
7(
静态资源
)
| ||
|
Nginx+Gateway
| 50 | |||
|
Gateway+
简单服务
| 50 |
3126
|
30
|
125
|
|
全链路
| 50 |
800
|
88
|
310
|
- 中间件越多,性能损失越大,大多都损失在网络交互了
- 业务:
- Db(MySQL 优化)
- 模板的渲染速度(缓存)
- 静态资源
3.3.3、Nginx动静分离
Nginx动静分离,也就是将访问静态资源和动态资源区分开,将静态资源放置到Nginx上

通过前面的吞吐量测试,我们能够看到访问静态资源对于“gulimall-product”服务造成的访问压力,在生产中我们可以考虑将这部分静态资源部署到Nginx上来优化。
在“gulimall-product”微服务中,原来的所有静态资源都放置到了resources/static,在做动静分离的时候,我们可以考虑将这些资源迁移到Nginx上。
迁移方法:
(1)找到Nginx存放静态资源的位置。这里我们使用的是Nginx容器,将本地“/mydata/nginx/html”映射到远程的“/usr/share/nginx/html”,所以应该将静态资源放置到该目录下。
(2)在/mydata/nginx/html目录下创建static文件夹: mkdir static
(3)使用SecureFX传送工具(换了一个连接虚拟机的客户端工具),将
“gulimall-product/src/main/resources/static ”下的“index”静态资源放置到Nginx路径中。

(4)ctrl+R 修改index.html“”页面,将所有的对于静态资源的访问加上static路径


(5)修改Nginx的“gulimall.conf”文件,这里指定所有static的访问,都是到“/usr/share/nginx/html”路径下寻找


(6)、重启Nginx
docker restart nginx(7)测试效果

Nginx转发效果

3.3.4、模拟线上应用内存崩溃宕机情况
再次进行压测:


执行压测
查看测试报告

同时通过jvisualvm查看GC过程

能够看到在老年代中存在耗时的GC过程,并且随着并发量增加,已经开始出现OutOfMemoryError异常了

并且服务也会down掉:

现在我们可以通过增加服务占用的内存大小,来控制减少Full GC发生的频率

3.3.5、优化三级分类数据获取
来看我们之前编写的获取三级分类的业务逻辑:
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getLevel1Categories();
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", l2.getCatId()));
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}(1)先从数据库中查询所有的一级分类
(2)根据一级分类的ID到数据库中找到对应的二级分类
(3)根据二级分类的ID,到数据库中寻找到对应的三级分类
在这个逻辑实现中,每一个一级分类的ID,至少要经过3次数据库查询才能得到对应的三级分类,所以在大数据量的情况下,频繁的操作数据库,性能比较低。
我们可以考虑将这些分类数据一次性的load到内存中,在内存中来操作这些数据,而不是频繁的进行数据库交互操作,下面是优化后的查询
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
/**
* 1、将数据库多次查询变为1次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
/**
* 在selectList中找到parentId等于传入的parentCid的所有分类数据
*
* @param selectList
* @param parent_cid
* @return
*/
private List<CategoryEntity> getParent_cid(List<CategoryEntity> selectList, Long parent_cid) {
List<CategoryEntity> collect = selectList
.stream()
.filter(item -> item.getParentCid() == parent_cid)
.collect(Collectors.toList());
//return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
return collect;
}整体的逻辑就是每次根据分类ID,找到所有子分类数据的时候,不再从数据库中查找,而是在内存中查询。
我们可以通过Jmeter来测试一下优化后的查询效率
请求参数设置如下:

下面是测试的比对:

四、缓存
1、缓存使用
对于复杂的业务,已经不能够通过代码层面的优化和数据库层面的优化,来达到增加吞吐量的目的。这就想要使用到缓存。
哪些数据适合放入缓存?
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)

data = cache.load(id);//从缓存加载数据
If(data == null){
data = db.load(id);//从数据库加载数据
cache.put(id,data);//保存到 cache 中
}
return data;注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
1.1、缓存的演化
本地缓存

分布式本地缓存
分布式缓存-本地模式在分布式下的问题

这种情况下,每个服务维持一个缓存,所带来的问题:
(1)缓存不共享
在这种情况下,每个服务都有一个缓存,但是这个缓存并不共享,水平上当调度到另外一个台设备上的时候,可能它的服务中并不存在这个缓存,因此需要重新查询。
(2)缓存一致性问题
在一台设备上的缓存更新后,其他设备上的缓存可能还未更新,这样当从其他设备上获取数据的时候,得到的可能就是未给更新的数据。
1.2、分布式缓存

在这种下,一个服务的不同副本共享同一个缓存空间,缓存放置到缓存中间件中,这个缓存中间件可以是redis等,而且缓存中间件也是可以水平或纵向扩展的,如Redis可以使用redis集群。它打破了缓存容量的限制,能够做到高可用,高性能。
2、整合redis测试
在“gulimall-product”项目中引入redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>Reids是通过“RedisAutoConfiguration”来完成的,它将所有的配置信息,都放置到了“RedisProperties”中。
配置redis主机地址
spring:
redis:
host: 192.168.119.127
port: 6379这里我们的Redis服务器为192.168.119.127,部署的是Redis容器。
在“org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration”类中,提供了两种操作Redis的方式:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
//将保存进入Redis的键值都是Object
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
//保存进Redis的数据,键值是(String,String)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}关于“StringRedisTemplate”
public class StringRedisTemplate extends RedisTemplate<String, String> {
/**
* Constructs a new <code>StringRedisTemplate</code> instance. {@link #setConnectionFactory(RedisConnectionFactory)}
* and {@link #afterPropertiesSet()} still need to be called.
*/
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());//键序列化为String
setValueSerializer(RedisSerializer.string());//key序列化为String
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
}综上:SpringBoot整合Redis的方式
- 引入“spring-boot-starter-data-redis”
- 简单配置Redis的host等信息
- 使用SpringBoot自动配置好的"StringRedisTemplate"来操作redis。
测试:
引入StringRedisTemplate
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate() {
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
//保存
ops.set("hello", "world_" + UUID.randomUUID());
//查询
String hello = ops.get("hello");
System.out.println("之前保存的数据是:" + hello);
}结果
之前保存的数据是:world_89b4beb8-8310-4c1b-ad50-0a58e189165a在Redis上查看结果

3、改造三级分类业务
先从缓存中获取分类三级分类数据,如果没有再从数据库中查询,并且将查询结果以JSON字符串的形式存放到Reids中的。
修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl” 类,代码如下:
@Autowired
StringRedisTemplate stringRedisTemplate;
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 缓存中放json字符串,拿出的json字符串,还能逆转为能用的对象类型;【序列化与反序列化】
// 1、加入缓存逻辑
// JSON好处是跨语言,跨平台兼容。
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 2、缓存中没有查询数据库
Map<String, List<Catelog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();
String json = JSON.toJSONString(catalogJsonFromDB);
// 3、查询的数据再放入缓存
stringRedisTemplate.opsForValue().set("catalogJSON", json);
return catalogJsonFromDB;
}
// 转为我们指定的对象
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
} /**
* 从数据库查询并封装数据
* 逻辑是:
* (1)根据一级分类,找到对应的二级分类
* (2)将得到的二级分类,封装到Catelog2Vo中
* (3)根据二级分类,得到对应的三级分类
* (3)将三级分类封装到Catalog3List
*
* @return
*/
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDB() {
/**
* 1、将数据库多次查询变为1次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
/**
* 在selectList中找到parentId等于传入的parentCid的所有分类数据
*
* @param selectList
* @param parent_cid
* @return
*/
private List<CategoryEntity> getParent_cid(List<CategoryEntity> selectList, Long parent_cid) {
List<CategoryEntity> collect = selectList
.stream()
.filter(item -> item.getParentCid() == parent_cid)
.collect(Collectors.toList());
//return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
return collect;
}4、压力测试出内存泄露及解决
启动“gulimall-product”和“gulimall-gateway”
执行压测:


测试报告:

再次访问页面出现了异常:

堆外内存溢出的原因:
产生堆外内存溢出:OutOfDirectMemoryError
1)、springboot2.0以后默认使用lettuce作为操作redis的客户端。使用netty进行网络通信
2)、lettuce的bug导致netty堆外内存溢出,Xmx300m:netty;netty如果没有指定堆外内存,默认使用-Xmx300m
可以通过-Dio.netty.maxDirectMemory进行设置
解决方案:不能使用-Dio.netty.maxDirectyMemory只去调大堆外内存
1)、升级lettuce客户端。
2)、切换使用jedis
redisTemplate
lettuce、jedis操作redis的底层客户端,spring再次封装redisTemplate
解决方法:
修改“gulimall-product”的“pom.xml”文件,更换为Jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>再次执行压测,没有出现Error:

使用Redis作为缓存后,吞吐量得到了很大的提升,响应时间也缩短了很多:

5、高并发下缓存失效问题
前面我们将查询三级分类数据的查询进行了优化,将查询结果放入到Redis中,当再次获取到相同数据的时候,直接从缓存中读取,没有则到数据库中查询,并将查询结果放入到Redis缓存中

但是在分布式系统中,这样还是会存在问题。
5.1、缓存穿透

5.2、缓存雪崩

5.3、缓存击穿

简单来说:缓存穿透是指查询一个永不存在的数据;缓存雪崩是值大面积key同时失效问题;缓存击穿是指高频key失效问题;
5.4、加锁解决缓存击穿问题
将查询db的方法加锁,这样在同一时间只有一个方法能查询数据库,就能解决缓存击穿的问题了
现在针对于单体应用上的加锁,我们来测试一下它是否能够正常工作。
(1)删除“redis”中的“catelogJson”

(2)修改三级分类的代码
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 缓存中放json字符串,拿出的json字符串,还能逆转为能用的对象类型;【序列化与反序列化】
/**
* 1、空结果缓存,解决缓存穿透
* 2、设置过期时间(随机加值);解决缓存雪崩
* 3、加锁,解决缓存击穿
*/
// 1、加入缓存逻辑
// JSON好处是跨语言,跨平台兼容。
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 2、缓存中没有查询数据库
System.out.println("缓存不命中.....将要查询数据库...");
Map<String, List<Catelog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();
String json = JSON.toJSONString(catalogJsonFromDB);
// 3、查询的数据再放入缓存
stringRedisTemplate.opsForValue().set("catalogJSON", json, 1, TimeUnit.DAYS);
return catalogJsonFromDB;
}
System.out.println("缓存命中...直接返回...");
// 转为我们指定的对象
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
//从数据库查询并封装分类数据
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDB() {
// 只要同一把锁就能锁住需要这个锁的所有线程
// 1、synchronized(this):SpringBoot所有的组件在容器中都是单例的
// TODO 本地锁:synchronized,JUC(lock)。在分布式情况下想要锁住所有,必须使用分布式锁
// 使用DCL(双端检锁机制)来完成对于数据库的访问
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (!StringUtils.isEmpty(catalogJSON)) {
//如果缓存不为null直接缓存
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库。。。。。");
/**
* 1、将数据库多次查询变为1次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
}在上述方法中,我们将业务逻辑中的确认缓存没有和查数据库放到了锁里,但是最终控制台却打印了两次查询了数据库。这是因为在将结果放入缓存的这段时间里,有其他线程确认缓存没有,又再次查询了数据库,因此我们要将结果放入缓存也进行加锁。
5.5、锁时序问题

1、删除“redis”中的“catelogJson”
2、优化代码逻辑后
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
// 缓存中放json字符串,拿出的json字符串,还能逆转为能用的对象类型;【序列化与反序列化】
/**
* 1、空结果缓存,解决缓存穿透
* 2、设置过期时间(随机加值);解决缓存雪崩
* 3、加锁,解决缓存击穿
*/
// 1、加入缓存逻辑
// JSON好处是跨语言,跨平台兼容。
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (StringUtils.isEmpty(catalogJSON)) {
// 2、缓存中没有查询数据库
System.out.println("缓存不命中.....将要查询数据库...");
Map<String, List<Catelog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();
return catalogJsonFromDB;
}
System.out.println("缓存命中...直接返回...");
// 转为我们指定的对象
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
/**
* 从数据库查询并封装数据
* 逻辑是:
* (1)根据一级分类,找到对应的二级分类
* (2)将得到的二级分类,封装到Catelog2Vo中
* (3)根据二级分类,得到对应的三级分类
* (3)将三级分类封装到Catalog3List
*
* @return
*/
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDB() {
// 只要同一把锁就能锁住需要这个锁的所有线程
// 1、synchronized(this):SpringBoot所有的组件在容器中都是单例的
// TODO 本地锁:synchronized,JUC(lock)。在分布式情况下想要锁住所有,必须使用分布式锁
// 使用DCL(双端检锁机制)来完成对于数据库的访问
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJSON = stringRedisTemplate.opsForValue().get("catalogJSON");
if (!StringUtils.isEmpty(catalogJSON)) {
//如果缓存不为null直接缓存
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库。。。。。");
/**
* 1、将数据库多次查询变为1次
*/
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
String json = JSON.toJSONString(parent_cid);
// 3、查询的数据再放入缓存
stringRedisTemplate.opsForValue().set("catalogJSON", json, 1, TimeUnit.DAYS);
return parent_cid;
}
}
这里我们使用了双端检锁机制来控制线程的并发访问数据库。一个线程进入到临界区之前,进行缓存中是否有数据,进入到临界区后,再次判断缓存中是否有数据,这样做的目的是避免阻塞在临界区的多个线程,在其他线程释放锁后,重复进行数据库的查询和放缓存操作。
注:关于双端检锁机制的简单了解,可以参照:https://www.cnblogs.com/cosmos-wong/p/11914878.html
3、后执行压测,使用100个线程来回发送请求:

优化后多线程访问时仅查询一次数据库

4、结论
通过观察日志,能够发现只有一个线程查询了数据库,其他线程都是直接从缓存中获取到数据的。所以在单体应用上实现了多线程的并发访问。
由于这里我们的“gulimall-product”就部署了一台,所以看上去一切祥和,但是在如果部署了多台,问题就出现了,主要问题就集中在我们所使用的锁上。我们锁使用的是“synchronized ”,这是一种本地锁,它只是在一台设备上有效,无法实现分布式情况下,锁住其他设备的相同操作。
我们现在的操作模型,表现为如下的形式:

6、本地锁在分布式下的问题
1)、删除“redis”中的“catelogJson”
2)、复制服务
为了演示在分布式情况下本地锁的工作状况,我们将“gulimall-product”按照如下的方式复制了2份


这样形成了2个复制的和一个原生的:

3)、启动服务
同时启动四个服务,此时在Nacos中我们可以看到“gulimall-product”服务具有四个实例:
4)、执行压测
在修改Jmeter的HTTP请求参数:

注意:之前我们在配置Nginx的时候,配置了upstream,所以它会将请求转给网关,通过网关负载均衡到“gulimall”服务的多个实例上:
在Jmeter中修改本次测试所使用的线程数和循环次数:

启动Jmeter进行压测
5)、查看结果
查看各个微服务的输出:
10002

10003:

10004:

总结:
能够发现,四个服务,分别存在着四个缓存未命中的情况,也就意味着会有四次查询数据库的操作,显然我们的synchronize锁未能实现限制其他服务实例进入临界区,也就印证了在分布式情况下,本地锁只能针对于当前的服务生效。
7、分布式锁原理与使用
7.1、本地缓存面临问题
当有多个服务存在时,每个服务的缓存仅能够为本服务使用,这样每个服务都要查询一次数据库,并且当数据更新时只会更新单个服务的缓存数据,就会造成数据不一致的问题
所有的服务都到同一个redis进行获取数据,就可以避免这个问题
7.2、分布式锁
当分布式项目在高并发下也需要加锁,但本地锁只能锁住当前服务,这个时候就需要分布式锁。

本地锁,只能锁住当前进程,所以我们需要分布式锁
7.3、分布式锁的演进
- 基本原理

我们可以同时去一个地方 “ 占坑 ” ,如果占到,就执行逻辑。否则就必须等待,直到释放锁。“ 占坑 ” 可以去 redis ,可以去数据库,可以去任何大家都能访问的地方。等待可以 自旋 的方式。
下面使用redis来实现分布式锁,使用的是SET key value [EX seconds] [PX milliseconds] [NX|XX],http://www.redis.cn/commands/set.html
1、打开SecureCRT,创建四个Redis的redis-cli连接
2、同时执行“set loc 1 NX”观察四个窗口的输出
将命令批量发送到四个窗口的的方式:
- 阶段一

private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}
问题:1、setnx占好了位,业务代码异常或者程序在页面过程中宕机。没有执行删除锁逻辑,这就造成了死锁
解决:设置锁的自动过期,即使没有删除,会自动删除
- 阶段二

private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间
stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}- 阶段三

private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111", 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
} else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}
- 阶段四

private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
String lockValue = stringRedisTemplate.opsForValue().get("lock");
if (uuid.equals(lockValue)) {
//删除我自己的锁
stringRedisTemplate.delete("lock");//删除锁
}
return dataFromDB;
} else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}- 阶段五-最终形态

private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
System.out.println("获取分布式锁成功。。。");
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
// 获取值对比+对比成功删除=原子操作 Lua脚本解锁
// String lockValue = redisTemplate.opsForValue().get("lock");
// if (uuid.equals(lockValue)) {
// // 删除我自己的锁
// stringRedisTemplate.delete("lock");//删除锁
// }
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 删除锁
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
System.out.println("删除锁返回值:" + lock1);
return dataFromDB;
} else {
System.out.println("获取分布式锁失败,等待重试。。。");
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";保证加锁【占位+过期时间】和删除锁【判断+删除】的原子性。
更难的事情,锁的自动续期。


8、Redisson
1、导入依赖:以后使用Redisson作为分布式锁,分布式对象等功能框架
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.5</version>
</dependency>另外Redison也提供了一个集成到SpringBoot上的starter

由于我们使用的单节点,所以配置了单节点的Redisson,2. 配置方法 · redisson/redisson Wiki · GitHub
新建“com.atguigu.gulimall.product.config.MyRedisConfig”配置类,代码如下
package com.atguigu.gulimall.product.config;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MyRedisConfig {
@Bean(destroyMethod = "shutdown")
public RedissonClient redisson() {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.119.127:6379");
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}
3、测试是否注入了RedissonClient
@Autowired
RedissonClient redissonClient;
@Test
public void testRedison(){
System.out.println(redissonClient);
}结果

8.1、lock锁测试
Redison分布式锁:8. 分布式锁和同步器 · redisson/redisson Wiki · GitHub
在Redison中分布式锁的使用,和java.util.concurrent包中的所提供的锁的使用方法基本相同。
测试Redisson的Lock锁的使用:
修改“com.atguigu.gulimall.product.web.IndexController”类,代码如下:
@GetMapping("/hello")
@ResponseBody
public String hello(){
// 1.获取一把锁,只要名字一样,就是同一把锁
RLock lock = redisson.getLock("my-lock");
// 2.加锁和解锁
try {
lock.lock();
System.out.println("加锁成功,执行业务方法..."+Thread.currentThread().getId());
Thread.sleep(30000);
} catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
System.out.println("释放锁..."+Thread.currentThread().getId());
}
return "hello";
}同时发送两个请求到:http://localhost:10000/hello

能够看到在加锁期间另外一个请求一直都是出于挂起状态,需要等待上一个请求处理完毕后,它才能接着执行。

查看Redis:

8.2、Redisson分布式锁实现原理
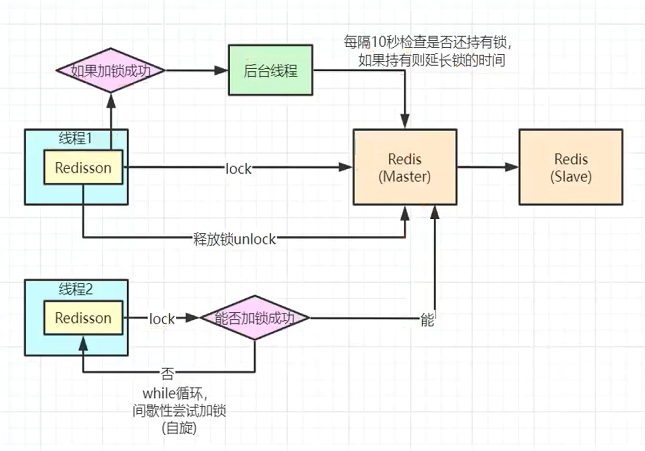
8.3、lock看门狗原理-redisson如何解决死锁
设想一种情况,一个请求线程在执行业务方法的时候,突然发生了中断,此时没有来得及执行释放锁操作,那么同时等待的另外一个线程是否会发生死锁。为了模拟这种情形,我们同时启动10000和10001,同时发送请求。

同时发送请求:
在10000端口上的服务在获取锁后,突然中断它的运行

观察Redis,能够看到这个锁仍然仍然存在:

此时在10001上运行的服务先是等待一会,然后成功获取到了锁:

观察Redis能够看大这个锁变为了针对于10001端口的了:

通过上面的实践能够看到,在加锁后,即便我们没有释放锁,也会自动的释放锁,这是因为在Redisson中会为每个锁加上“leaseTime”,默认是30秒
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
在Redis中,我们能够看到这一点:

小结:redisson的lock具有如下特点
1、lock.lock():阻塞式等待。默认加的都是30s
- 锁的自动续期,如果业务过长,运行期间自动给锁续上30s,不用担心业务时间长,锁自动过期被删掉。
- 加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除。
lock方法还有一个重载的方法,lock(long leaseTime, TimeUnit unit)
@Override
public void lock(long leaseTime, TimeUnit unit) {
try {
lock(leaseTime, unit, false);
} catch (InterruptedException e) {
throw new IllegalStateException();
}
}2、lock.lock(10, TimeUnit.SECONDS):10秒自动解锁,自动解锁时间一定大于业务的执行时间
问题:lock.lock(10, TimeUnit.SECONDS);在锁到期后,是否会自动续期?
答:在指定了超时时间后,不会进行自动续期,此时如果有多个线程,即便业务仍然在执行,超时时间到了后,锁也会失效,其他线程就会争抢到锁。
- 如果我们传递了锁的超时时间,就发给redis执行脚本,进行占锁,默认超时就是我们指定的时间。
- 如果我们未指定锁的超时时间,就是用30*1000【lockWatchdogTimeout看门狗的默认时间】。
- 关于续期周期,只要锁占领成功,就会自动启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自动再次续期,续成30s。这个10s中是根据( internalLockLeasTime)/3得到的。
3、最佳实战
- 尽管相对于lock(),lock(long leaseTime, TimeUnit unit)存在到期后自动删除的问题,但是我们对于它的使用还是比较多的,通常都会评估一下业务的最大执行用时,在这个时间内,如果仍然未能执行完成,则认为出现了问题,则释放锁执行其他逻辑。
4、lock.tryLock(100, 10, TimeUnit.SECONDS)
- 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
8.4、读写锁测试
读写锁作用:
保证一定能够读取到最新的数据,修改期间,写锁是一个排他锁(互斥锁),读锁是一个共享锁,写锁没释放读就必须等待。
1、在Redis增加一个新的key“writeValue”,值为11111

2、增加write和read的controller方法
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock = redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", uuid);
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock = redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
uuid = redisTemplate.opsForValue().get("writeValue");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return uuid;
}3、启动gulimall-product
4、分别访问“http://localhost:10000/read”和“http://localhost:10000/write”,观察现象。
- 执行写操作时,读操作必须要等待;
- 可以同时执行多个读操作,读操作之间互不影响;
- 在写操作时查看Redis中“rw-loc”的状态

读写锁补充
1、修改“read”和“write”的controller方法
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock = redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
log.info("写锁加锁成功");
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", uuid);
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("写锁释放");
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock = redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
log.info("读锁加锁成功");
uuid = redisTemplate.opsForValue().get("writeValue");
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("读锁释放");
}
return uuid;
}
}2、先发送一个写请求,然后同时发送四个读请求
3、观察现象
- 在写操作期间,四个读操作被阻塞,此时查看Redis中“rw-loc”状态,是写状态

- 写操作完毕后,查看Redis中的“rw-loc”状态,状态为读状态

同时会出现三个读锁的
- 查看控制台输出

能够看到三个读操作是同时获取到锁的。
另外在先执行读操作时,写操作被阻塞。
4、小结:
- 读+读:相当于无锁,并发读,只会在redis中记录,所有当前的读锁,都会同时加锁成功
- 写+读:等待写锁释放;
- 写+写:阻塞方式
- 读+写:写锁等待读锁释放,才能加锁
所以只要存在写操作,不论前面是或后面执行的是读或写操作,都会阻塞。
5、闭锁测试
/**
* 放假,锁门
* 5个班全部走完,我们可以锁大门
*/
@GetMapping("/lockDoor")
@ResponseBody
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.trySetCount(5);
door.await();//等待闭锁都完成
return "放假了...";
}
@GetMapping("/gogogo/{id}")
@ResponseBody
public String gogogo(@PathVariable("id") Long id) {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.countDown();//计数减一
return id + "班级的人都走了";
}8.5、信号量测试
先在redis中设置park的值为3

/**
* 车库停车
* 3车位
* 信号量也可以用作限流
*/
@GetMapping("park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
park.acquire();//获取一个信号;获取一个值;占一个车位
boolean b = park.tryAcquire();
if (b) {
//执行业务
} else {
return "error";
}
return "ok=>" + b;
}
/**
* 车开走
* 释放信号量
*/
@GetMapping("go")
@ResponseBody
public String go() throws InterruptedException {
RSemaphore park = redissonClient.getSemaphore("park");
park.release();//释放一个车位
return "ok";
}小结:
- 信号量可以作为分布式限流
8.6、缓存一致性解决
缓存一致性是为了解决数据库和缓存的数据不同步问题的。
1)、缓存数据一致性-双写模式

- 由于卡顿等原因,导致写缓存2在最前,写缓存1在后面就出现了不一致脏数据问题
- 这是暂时性的脏数据问题,但是在数据稳定,缓存过期以后,又能得到最新的正确数据读到的最新数据有延迟:最终一致性
2)、缓存数据一致性-失效模式

我们系统的一致性解决方案:
- 缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
- 读写数据的时候,加上分布式的读写锁。 经常写,经常读
3)、缓存一致性——解决方案
- 无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 1、如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 2、如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 3、缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 4、通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
- 总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
4)、缓存数据一致性-解决-Canal

使用Redisson的锁机制优化三级分类数据的查询。
/**
* 使用Redisson分布式锁来实现多个服务共享同一缓存中的数据
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedissonLock() {
RLock lock = redissonClient.getLock("CatelogJson-lock");
//该方法会阻塞其他线程向下执行,只有释放锁之后才会接着向下执行
lock.lock();
Map<String, List<Catelog2Vo>> catalogJsonFromDb;
try {
//从数据库中查询分类数据
catalogJsonFromDb = getCatalogJsonFromDb();
} finally {
lock.unlock();
}
return catalogJsonFromDb;
}我们系统的一致性解决方案:
1、缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
2、读写数据的时候,加上分布式的读写锁。
在更新分类数据的时候,删除缓存中的旧数据。
9、SpringCache-简介
9.1、简介
- Spring 从 3.1 开始定义了 org.springframework.cache.Cache和 org.springframework.cache.CacheManager 接口来统一不同的缓存技术;并支持使用 JCache(JSR-107)注解简化我们开发;
- Cache 接口为缓存的组件规范定义,包含缓存的各种操作集合;Cache 接 口 下 Spring 提 供 了 各 种 xxxCache 的 实 现 ; 如 RedisCache , EhCacheCache , ConcurrentMapCache 等;
- 每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
- 使用 Spring 缓存抽象时我们需要关注以下两点;
- 1、确定方法需要被缓存以及他们的缓存策略
- 2、从缓存中读取之前缓存存储的数据
SpringCache的文档:https://docs.spring.io/spring-framework/docs/5.3.34/reference/html/integration.html#cache
9.2、基础概念

9.3、SpringCache-整合&体验@Cacheable
整合SpringCache,简化缓存的开发
1、引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>引入spring-boot-starter-data-redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>2、编写配置
1)、缓存的自动配置了哪些?
- CacheAutoConfiguration,会导入RedisCacheConfiguration
- 自动配置了缓存管理器RedisCacheManager
2)、配置使用Redis作为缓存
修改“application.properties”文件,指定使用redis作为缓存,spring.cache.type=redis
spring.cache.type=redis3)、和缓存有关的注解
| Cache | 缓存接口,定义缓存操作。实现有:Rediscache、Ehcachecache、ConcurrentMapCache等 |
| CacheManager | 缓存管理器,管理各种缓存(cache)组件 |
| @Cacheable | 触发将数据保存到缓存的操作 |
| @CacheEvict | 触发将数据从缓存中删除的操作 |
| @CachePut | 在不影响方法执行的情况下更新缓存。 |
| @EnableCaching | 开启基于注解的缓存 |
| keyGenerator | 缓存数据时key生成策略 |
| serialize | 缓存数据时value序列化策略 |
| @Caching | 组合以上多个操作 |
| @CacheConfig | 在类级别上共享一些公共的与缓存相关的设置。 |
 4)、表达式语法
4)、表达式语法

5)、测试使用缓存
(1)、开启缓存功能,在主启动类上,标注@EnableCaching
@EnableCaching
@EnableFeignClients(basePackages = "com.atguigu.gulimall.product.feign")
@EnableDiscoveryClient
@SpringBootApplication
public class GulimallProductApplication {
public static void main(String[] args) {
SpringApplication.run(GulimallProductApplication.class, args);
}
}(2)、只需要使用注解,就可以完成缓存操作
(3)、在业务方法的头部标上@Cacheable,加上该注解后,表示当前方法需要将进行缓存,如果缓存中有,方法无效调用,如果缓存中没有,则会调用方法,最后将方法的结果放入到缓存中。
(4)、指定缓存分区。每一个需要缓存的数据,我们都需要来指定要放到哪个名字的缓存中。通常按照业务类型进行划分。
如:我们将一级分类数据放入到缓存中,指定缓存名字为“category”
@Cacheable({"category"})//代表当前方法的结果需要缓存,如果缓存中有,方法不用调用。如果缓存中没有,最后将方法放入缓存。
@Override
public List<CategoryEntity> getLevel1Categories() {
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
return categoryEntities;
}6)、访问:http://localhost:10000/
7)、查看Redis

能够看到一级分类信息,已经被放入到缓存中了,而且再次访问的时候,没有查询数据库,而是直接从缓存中获取。
9.4、@Cacheable细节设置
上面我们将一级分类数据的信息缓存到Redis中了,缓存到Redis中数据具有如下的特点:
- 如果缓存中有,方法不会被调用;
- key默认自动生成;形式为"缓存的名字::SimpleKey [](自动生成的key值)";
- 缓存的value值,默认使用jdk序列化机制,将序列化后的数据缓存到redis;
- 默认ttl时间为-1,表示永不
然而这些并不能够满足我们的需要,我们希望:
- 能够指定生成缓存所使用的key;
- 指定缓存的数据的存活时间;
- 将缓存的数据保存为json形式;
针对于第一点,我们使用@Cacheable注解的时候,设置key属性,接受一个SpEL
@Cacheable(value = {"category"},key = "'level1Categorys'")针对于第二点,在配置文件中指定ttl:
spring.cache.redis.time-to-live=3600000 #这里指定存活时间为1小时清空redis,再次进行访问:http://localhost:10000/
查看Redis

更多关于key的设置,在文档中给予了详细的说明:https://docs.spring.io/spring/docs/5.3.0-SNAPSHOT/spring-framework-reference/integration.html#cache-annotations-cacheable

9.5、自定义缓存配置
上面我们解决了第一个命名问题和第二个设置存活时间问题,但是如何将数据以JSON的形式缓存到Redis呢?
这涉及到修改缓存管理器的设置,CacheAutoConfiguration导入了RedisCacheConfiguration,而RedisCacheConfiguration中自动配置了缓存管理器RedisCacheManager,而RedisCacheManager要初始化所有的缓存,每个缓存决定使用什么样的配置,如果RedisCacheConfiguration有就用已有的,没有就用默认配置。
想要修改缓存的配置,只需要给容器中放一个“redisCacheConfiguration”即可,这样就会应用到当前RedisCacheManager管理的所有缓存分区中。
private org.springframework.data.redis.cache.RedisCacheConfiguration createConfiguration(
CacheProperties cacheProperties, ClassLoader classLoader) {
Redis redisProperties = cacheProperties.getRedis();
org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration
.defaultCacheConfig();
config = config.serializeValuesWith(
SerializationPair.fromSerializer(new JdkSerializationRedisSerializer(classLoader)));
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}Redis中的序列化器:org.springframework.data.redis.serializer.RedisSerializer

在Redis中放入自动配置类,设置JSON序列化机制
package com.atguigu.gulimall.product.config;
import org.springframework.boot.autoconfigure.cache.CacheProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching
public class MyCacheConfig {
/**
* 配置文件中的东西没有用到
*
* 1、原来和配置文件绑定的配置类是这样的
* @ConfigurationProperties(prefix="spring.cache")
* public class CacheProperties
* 2、让他生效
* @EnableConfigurationProperties(CacheProperties.class)
* @return
*/
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//将配置文件中的所有配置都生效
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//设置配置文件中的各项配置,如过期时间
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
查看Redis能够看到以JSON的形式,将数据缓存下来了:

在配置文件中,还可以指定一些缓存的自定义配置
spring.cache.type=redis
#设置超时时间,默认是毫秒
spring.cache.redis.time-to-live=3600000
#设置Key的前缀,如果指定了前缀,则使用我们定义的前缀,否则使用缓存的名字作为前缀
spring.cache.redis.key-prefix=CACHE_
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true基于这个配置,在如果出现了null值,也会被保存到redis中:

如果配置“spring.cache.redis.use-key-prefix=false”,则生成的key没有前缀:

9.6、@CacheEvict
在上面实例中,在读模式中,我们将一级分类信息缓存到redis中,当请求再次获取数据时,直接从缓存中进行获取,但是如果执行的是写模式呢?
在写模式下,有两种方式来解决缓存一致性问题,双写模式和失效模式,在SpringCache中可以通过@CachePut来实现双写模式,使用@CacheEvict来实现失效模式。
实例:使用缓存失效机制实现更新数据库中值的是,使得缓存中的数据失效
(1)、修改updateCascade方法,添加@CacheEvict注解,指明要删除哪个分类下的数据,并且确定key
修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,代码如下:
@CacheEvict(value = {"category"}, key = "getLevel1Categories")
@Transactional
@Override
public void updateCascade(CategoryEntity category) {
this.updateById(category);
categoryBrandRelationService.updateCategory(category.getCatId(), category.getName());
// 同时修改缓存中的数据
// redis.del("catalogJSON");等待下一次主动查询进行更新
}(2)、启动gulimall-product,启动renren-fast,启动gulimall-gateway,启动项目的前端页面
(3)、检查redis中是否有“category”命名空间下的数据,没有则访问http://localhost:10000/,生成数据

(4)修改数据:

(5)检查Redis中对应数据是否还存在

检查后发现数据没了,说明缓存失效策略是有效的。
另外在修改了一级缓存时,对应的二级缓存也需要更新,需要修改原来二级分类的执行逻辑。
将“getCatalogJson”恢复成为原来的逻辑,但是设置@Cacheable,非侵入的方式将查询结果缓存到redis中:
修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,代码如下:
@Cacheable(value = {"category"}, key = "#root.methodName")
@Override
public Map<String, List<Catelog2Vo>> getCatalogJson() {
System.out.println("查询了数据库。。。。。");
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
再次访问,发现控制台数据未更新,还是第一次访问时的输出:

查看Redis中缓存的数据:

上面我们将一级和三级分类信息都缓存到了redis中,现在我们想要实现一种场景是,更新分类数据的时候,将缓存到redis中的一级和三级分类数据都清空。
借助于“@Caching”来完成
修改“com.atguigu.gulimall.product.service.impl.CategoryServiceImpl”类,代码如下:
@Caching(evict={
@CacheEvict(value = {"category"},key = "'level1Categorys'"),
@CacheEvict(value = {"category"},key = "'getCatalogJson'")
})
@Override
@Transactional
public void updateCascade(CategoryEntity category) {
this.updateById(category);
relationService.updateCategory(category.getCatId(),category.getName());
}查询redis,一级和三级分类数据已经被删除。
除了可以使用@Cache外,还可以使用@CacheEvict来完成:
@CacheEvict(value = {"category"},allEntries = true)
@Override
@Transactional
public void updateCascade(CategoryEntity category) {
this.updateById(category);
relationService.updateCategory(category.getCatId(),category.getName());
}它表示要删除“category”分区下的所有数据。
可以看到存储同一类型的数据,都可以指定未同一个分区,可以批量删除这个分区下的数据。以后建议不使用分区前缀,而是使用默认的分区前缀。
小结:
CacheEvict:失效模式
- 同时进行多种缓存操作 @Caching
- 指定删除某个分区下的所有数据
- 存储同一类型的数据,都可以指定成同一个分区。分区名默认就是缓存的前缀
9.7、SpringCache-原理与不足
1)、读模式
- 缓存穿透:查询一个null值。解决,缓存空数据;cache-null-value=true;
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方法,是进行加锁,默认是没有加锁的,查询时设置Cacheable的sync=true即可解决缓存击穿。
- 缓存雪崩:大量的key同时过期。解决方法:加上随机时间;加上过期时间。“spring.cache.redis.time-to-live=3600000”
2)、写模式(缓存与数据一致)
- 读写加锁;
- 引入canal,感知到mysql的更新去更新数据库;
- 读多写少,直接去数据库查询就行;
3)、总结
- 常规数据(读多写少,即时性,一致性要求不高的数据):完全可以使用spring-cache;写模式,只要缓存的数据有过期时间就足够了;
- 特殊数据:特殊设计;
五、商城业务-商品检索
1、搭建页面环境
1、gulimall-search的pom.xml添加thymeleaf依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>2、将静态资源放入到static文件夹下,而将index.html放入到templates文件夹下:

3、在虚拟机mydata/nginx/html/路径下创建search文件夹然后把搜索页的静态资源上传到该文件里

4、修改index.html页面访问静态资源的地址,例如:href,src


5、host添加
192.168.119.127 gulimall.com
192.168.119.127 search.gulimall.com6、配置nginx


7、重启nginx
![]()
8、修改网关断言配置
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=gulimall.com
- id: gulimall_search_route
uri: lb://gulimall-search
predicates:
- Host=search.gulimall.com
gulimall-search的pom.xml添加devtools
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>gulimall-search的配置文件关闭thymeleaf缓存
spring.thymeleaf.cache=falseNginx转发效果

9、测试,访问search.gulimall.com
2、调整页面跳转
2.1、跳转到首页
当点击检索页的 "谷粒商城" 可以跳转到首页

修改gulimall-search的index.html代码:


2.2、商品检索三个入口
- 选择分类进入商品检索

- 输入检索关键字展示检索页

- 选择筛选条件进入

- 最终跳转的页面效果

代码实现:
1、修改gulimall-search的index.html名字为list.html
2、新增“com.atguigu.gulimall.search.controller.SearchController”类,代码如下:
@Controller
public class SearchController {
@GetMapping("/list.html")
public String listPage() {
return "list";
}
}3、我们看到该html已经有search()函数,作为搜索点击的方法
<script type="text/javascript">
function search() {
var keyword=$("#searchText").val()
window.location.href="http://search.gulimall.com/list.html?keyword="+keyword;
}
</script>我们点击搜索无效,发现引用js方法不对,接下来修改gulimall-product的index.html类,代码如下:
 我们看到分类的js:catalogLoader.js已经设置好超链接地址,不需要我们调整什么,直接使用就好
我们看到分类的js:catalogLoader.js已经设置好超链接地址,不需要我们调整什么,直接使用就好

3. 检索条件&排序条件分析
-
全文检索:skuTitle -> keyword
-
排序:saleCount(销量)、hotScore(热度分)、skuPrice(价格)
-
过滤:hasStock、skuPrice区间、brandId、catalog3Id、attrs
-
聚合:attrs
-
完整查询参数
-
keyword=小米&sort=saleCount_desc/asc&hasStock=0/1&skuPrice=400_1900&brandId=1&catalog3Id=1&attrs=1_3G:4G:5G&attrs=2_骁龙845&attrs=4_高清屏
4、DSL分析
检索时需要进行:模糊匹配、过滤(按照属性,分类,品牌,价格区间,库存)、排序、分页、高亮、聚合分析 。
原先的映射(mapping)不符合我们现在的检索需求,我们需要先调整映射,在进行分析。
1、修改映射
PUT gulimall_product
{
"mappings": {
"properties": {
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
},
"autoGeneratedTimestamp": {
"type": "long"
},
"brandId": {
"type": "long"
},
"brandImg": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"catalogId": {
"type": "long"
},
"catalogName": {
"type": "keyword"
},
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"parentTask": {
"properties": {
"id": {
"type": "long"
},
"nodeId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"set": {
"type": "boolean"
}
}
},
"refreshPolicy": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"retry": {
"type": "boolean"
},
"saleCount": {
"type": "long"
},
"shouldStoreResult": {
"type": "boolean"
},
"skuId": {
"type": "long"
},
"skuImg": {
"type": "keyword"
},
"skuPrice": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"spuId": {
"type": "keyword"
}
}
}
}

迁移数据
POST _reindex
{
"source": {
"index": "product"
},
"dest": {
"index": "gulimall_product"
}
}

修改gulimall-search的常量
修改“com.atguigu.gulimall.search.constant.EsConstant”类,代码如下
public class EsConstant {
public static final String PRODUCT_INDEX = "gulimall_product"; //sku数据在es中的索引
}2、使用DSL检索
GET gulimall_product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"skuTitle": "华为"
}
}
],
"filter": [
{
"term": {
"catalogId": "225"
}
},
{
"terms": {
"brandId": [
"4"
]
}
},
{
"term": {
"hasStock": "false"
}
},
{
"range": {
"skuPrice": {
"gte": 1000,
"lte": 7000
}
}
},
{
"nested": {
"path": "attrs",
"query": {
"bool": {
"must": [
{
"term": {
"attrs.attrId": {
"value": "1"
}
}
}
]
}
}
}
}
]
}
},
"sort": [
{
"skuPrice": {
"order": "desc"
}
}
],
"from": 0,
"size": 5,
"highlight": {
"fields": {"skuTitle": {}},
"pre_tags": "<b style='color:red'>",
"post_tags": "</b>"
},
"aggs": {
"brandAgg": {
"terms": {
"field": "brandId",
"size": 10
},
"aggs": {
"brandNameAgg": {
"terms": {
"field": "brandName",
"size": 10
}
},
"brandImgAgg": {
"terms": {
"field": "brandImg",
"size": 10
}
}
}
},
"catalogAgg":{
"terms": {
"field": "catalogId",
"size": 10
},
"aggs": {
"catalogNameAgg": {
"terms": {
"field": "catalogName",
"size": 10
}
}
}
},
"attrs":{
"nested": {
"path": "attrs"
},
"aggs": {
"attrIdAgg": {
"terms": {
"field": "attrs.attrId",
"size": 10
},
"aggs": {
"attrNameAgg": {
"terms": {
"field": "attrs.attrName",
"size": 10
}
}
}
}
}
}
}
}
结果
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "gulimall_product",
"_type" : "_doc",
"_id" : "12",
"_score" : null,
"_source" : {
"attrs" : [
{
"attrId" : 1,
"attrName" : "入网型号",
"attrValue" : "111"
},
{
"attrId" : 2,
"attrName" : "上市年份",
"attrValue" : "2019"
},
{
"attrId" : 4,
"attrName" : "机身颜色",
"attrValue" : "星空灰"
}
],
"brandId" : 4,
"brandImg" : "https://wts-gulimall.oss-cn-shanghai.aliyuncs.com/2024-04-24/c10918fe-7241-47e9-8e74-c3310e768876_huawei.png",
"brandName" : "华为",
"catalogId" : 225,
"catalogName" : "手机",
"hasStock" : false,
"hotScore" : 0,
"saleCount" : 0,
"skuId" : 12,
"skuImg" : "https://wts-gulimall.oss-cn-shanghai.aliyuncs.com/2024-04-26//9e1f33b9-7eb6-489b-8c0f-2149077a3526_d511faab82abb34b.jpg",
"skuPrice" : 6799.0,
"skuTitle" : "华为(HUAWEI)华为Mate30 Pro 全网通 4G 白色 8G +128G",
"spuId" : 10
},
"highlight" : {
"skuTitle" : [
"<b style='color:red'>华为</b>(HUAWEI)<b style='color:red'>华为</b>Mate30 Pro 全网通 4G 白色 8G +128G"
]
},
"sort" : [
"6799.0"
]
}
]
},
"aggregations" : {
"brandAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 4,
"doc_count" : 1,
"brandImgAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "https://wts-gulimall.oss-cn-shanghai.aliyuncs.com/2024-04-24/c10918fe-7241-47e9-8e74-c3310e768876_huawei.png",
"doc_count" : 1
}
]
},
"brandNameAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "华为",
"doc_count" : 1
}
]
}
}
]
},
"catalogAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 225,
"doc_count" : 1,
"catalogNameAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "手机",
"doc_count" : 1
}
]
}
}
]
},
"attrs" : {
"doc_count" : 3,
"attrIdAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 1,
"doc_count" : 1,
"attrNameAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "入网型号",
"doc_count" : 1
}
]
}
},
{
"key" : 2,
"doc_count" : 1,
"attrNameAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "上市年份",
"doc_count" : 1
}
]
}
},
{
"key" : 4,
"doc_count" : 1,
"attrNameAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "机身颜色",
"doc_count" : 1
}
]
}
}
]
}
}
}
}
5、检索代码编写
1、请求参数和返回结果
1)、请求参数的封
新增“com.atguigu.gulimall.search.vo.SearchParam”类,代码如下:
package com.atguigu.gulimall.search.vo;
import lombok.Data;
import java.util.List;
/**
* 封装页面所有可能传递过来的查询条件
* catalog3Id=225&keyword=小米&sort=saleCount_asc
*/
@Data
public class SearchParam {
private String keyword;//页面传递过来的全文匹配关键字
private Long catalog3Id;//三级分类id
/**
* sort=saleCount_asc/desc
* sort=skuPrice_asc/desc
* sort=hotScore_asc/desc
*/
private String sort;//排序条件
/**
* 好多的过滤条件
* hasStock(是否有货)、skuPrice区间、brandId、catalog3Id、attrs
* hasStock=0/1
* skuPrice=1_500
*/
private Integer hasStock;//是否只显示有货
private String skuPrice;//价格区间查询
private List<Long> brandId;//按照品牌进行查询,可以多选
private List<String> attrs;//按照属性进行筛选
private Integer pageNum = 1;//页码
}
2)、返回结果
package com.atguigu.gulimall.search.vo;
import com.atguigu.common.to.es.SkuEsModel;
import lombok.Data;
import java.util.List;
@Data
public class SearchResult {
/**
* 查询到的商品信息
*/
private List<SkuEsModel> products;
private Integer pageNum;//当前页码
private Long total;//总记录数
private Integer totalPages;//总页码
private List<BrandVo> brands;//当前查询到的结果,所有涉及到的品牌
private List<CatalogVo> catalogs;//当前查询到的结果,所有涉及到的分类
private List<AttrVo> attrs;//当前查询到的结果,所有涉及到的属性
//=====================以上是返给页面的信息==========================
@Data
public static class BrandVo{
private Long brandId;
private String brandName;
private String brandImg;
}
@Data
public static class CatalogVo{
private Long catalogId;
private String catalogName;
private String brandImg;
}
@Data
public static class AttrVo{
private Long attrId;
private String attrName;
private List<String> attrValue;
}
}
2、主体逻辑
修改“com.atguigu.gulimall.search.controller.SearchController”类,代码如下:
/**
* 自动将页面提交过来的所有请求查询参数封装成指定的对象
*
* @return
*/
@GetMapping("/list.html")
public String listPage(SearchParam searchParam, Model model) {
SearchResult result = mallSearchService.search(searchParam);
System.out.println("====================" + result);
model.addAttribute("result", result);
return "list";
}新增“com.atguigu.gulimall.search.service.MallSearchService”类,代码如下:
/**
*
* @param param 检索的所有参数
* @return 返回检索的结果,里面包含页面需要的所有信息
*/
SearchResult search(SearchParam param);主要逻辑在service层进行,service层将封装好的SearchParam组建查询条件,再将返回后的结果封装成SearchResult
新增“com.atguigu.gulimall.search.service.impl.MallSearchServiceImpl”类,代码如下:
package com.atguigu.gulimall.search.service.impl;
import com.alibaba.cloud.commons.lang.StringUtils;
import com.alibaba.fastjson.JSON;
import com.atguigu.common.to.es.SkuEsModel;
import com.atguigu.gulimall.search.config.GulimallElasticSearchConfig;
import com.atguigu.gulimall.search.constant.EsConstant;
import com.atguigu.gulimall.search.service.MallSearchService;
import com.atguigu.gulimall.search.vo.SearchParam;
import com.atguigu.gulimall.search.vo.SearchResult;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.NestedQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.nested.NestedAggregationBuilder;
import org.elasticsearch.search.aggregations.bucket.nested.ParsedNested;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedLongTerms;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedStringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@Service
public class MallSearchServiceImpl implements MallSearchService {
@Autowired
RestHighLevelClient restHighLevelClient;
//去es进行检索
@Override
public SearchResult search(SearchParam param) {
// 动态构建出查询需要的DSL语句
SearchResult result = null;
// 1、准备检索请求
SearchRequest searchRequest = buildSearchRequest(param);
try {
// 2、执行检索请求
SearchResponse response = restHighLevelClient.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 分析响应数据封装我们需要的格式
result = buildSearchResult(response, param);
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* 准备检索请求
* 模糊匹配、过滤(按照属性、分类、品牌、价格区间、库存),排序,分页,高亮,聚合分析
*
* @return
*/
private SearchRequest buildSearchRequest(SearchParam param) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//构建DSL语句的
/**
* 1、过滤(按照属性、分类、品牌、价格区间、库存)
*/
// 1、构建bool-query
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
sourceBuilder.query(boolQuery);
// 1.1、must-模糊匹配、
if (!StringUtils.isEmpty(param.getKeyword())) {
boolQuery.must(QueryBuilders.matchQuery("skuTitle", param.getKeyword()));
}
// 1.2.1、filter-按照三级分类id查询
if (null != param.getCatalog3Id()) {
boolQuery.filter(QueryBuilders.termQuery("catalogId", param.getCatalog3Id()));
}
// 1.2.2、filter-按照品牌id查询
if (null != param.getBrandId() && param.getBrandId().size() > 0) {
boolQuery.filter(QueryBuilders.termsQuery("brandId", param.getBrandId()));
}
// 1.2.3、filter-按照是否有库存进行查询
if (null != param.getHasStock()) {
boolQuery.filter(QueryBuilders.termQuery("hasStock", param.getHasStock() == 1));
}
// 1.2.4、filter-按照区间进行查询 1_500/_500/500_
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("skuPrice");
if (!StringUtils.isEmpty(param.getSkuPrice())) {
String[] prices = param.getSkuPrice().split("_");
if (prices.length == 1) {
if (param.getSkuPrice().startsWith("_")) {
rangeQueryBuilder.lte(Integer.parseInt(prices[0]));
} else {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
} else if (prices.length == 2) {
// _6000会截取成["","6000"]
if (!prices[0].isEmpty()) {
rangeQueryBuilder.gte(Integer.parseInt(prices[0]));
}
rangeQueryBuilder.lte(Integer.parseInt(prices[1]));
}
boolQuery.filter(rangeQueryBuilder);
}
// 1.2.5、filter-按照属性进行查询
List<String> attrs = param.getAttrs();
if (null != attrs && attrs.size() > 0) {
// attrs=1_5寸:8寸&2_16G:8G
attrs.forEach(attr -> {
BoolQueryBuilder queryBuilder = new BoolQueryBuilder();
String[] attrSplit = attr.split("_");
queryBuilder.must(QueryBuilders.termQuery("attrs.attrId", attrSplit[0]));//检索的属性的id
String[] attrValues = attrSplit[1].split(":");
queryBuilder.must(QueryBuilders.termsQuery("attrs.attrValue", attrValues));//检索的属性的值
// 每一个必须都得生成一个nested查询
NestedQueryBuilder nestedQueryBuilder = QueryBuilders.nestedQuery("attrs", queryBuilder, ScoreMode.None);
boolQuery.filter(nestedQueryBuilder);
});
}
// 把以前所有的条件都拿来进行封装
sourceBuilder.query(boolQuery);
/**
* 2、排序,分页,高亮,
*/
// 2.1、排序 eg:sort=saleCount_desc/asc
if (!StringUtils.isEmpty(param.getSort())) {
String[] sortSplit = param.getSort().split("_");
sourceBuilder.sort(sortSplit[0], sortSplit[1].equalsIgnoreCase("asc") ? SortOrder.ASC : SortOrder.DESC);
}
// 2.2、分页
sourceBuilder.from((param.getPageNum() - 1) * EsConstant.PRODUCT_PAGESIZE);
sourceBuilder.size(EsConstant.PRODUCT_PAGESIZE);
// 2.3、高亮highlight
if (!StringUtils.isEmpty(param.getKeyword())) {
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("skuTitle");
highlightBuilder.preTags("<b style='color:red'>");
highlightBuilder.postTags("</b>");
sourceBuilder.highlighter(highlightBuilder);
}
/**
* 3、聚合分析
*/
// 3、聚合
// 3.1、按照品牌聚合
TermsAggregationBuilder brand_agg = AggregationBuilders.terms("brand_agg").field("brandId").size(50);
// 3.1.1、品牌聚合的子聚合
TermsAggregationBuilder brand_name_agg = AggregationBuilders.terms("brand_name_agg").field("brandName").size(1);
brand_agg.subAggregation(brand_name_agg);
TermsAggregationBuilder brand_img_agg = AggregationBuilders.terms("brand_img_agg").field("brandImg");
brand_agg.subAggregation(brand_img_agg);
sourceBuilder.aggregation(brand_agg);
// 3.2、按照catalog聚合
TermsAggregationBuilder catalog_agg = AggregationBuilders.terms("catalog_agg").field("catalogId").size(20);
TermsAggregationBuilder catalog_name_agg = AggregationBuilders.terms("catalog_name_agg").field("catalogName").size(1);
catalog_agg.subAggregation(catalog_name_agg);
sourceBuilder.aggregation(catalog_agg);
// 3.3、按照attrs聚合
NestedAggregationBuilder nestedAggregationBuilder = new NestedAggregationBuilder("attr_agg", "attrs");
// 3.3.1、按照attrId聚合
TermsAggregationBuilder attr_id_agg = AggregationBuilders.terms("attr_id_agg").field("attrs.attrId");
// 3.3.2、按照attrId聚合之后再按照attrName和attrValue聚合
TermsAggregationBuilder attr_name_agg = AggregationBuilders.terms("attr_name_agg").field("attrs.attrName").size(1);
attr_id_agg.subAggregation(attr_name_agg);
TermsAggregationBuilder attr_value_agg = AggregationBuilders.terms("attr_value_agg").field("attrs.attrValue").size(50);
attr_id_agg.subAggregation(attr_value_agg);
nestedAggregationBuilder.subAggregation(attr_id_agg);
sourceBuilder.aggregation(nestedAggregationBuilder);
String s = sourceBuilder.toString();
System.out.println("构建的DSL" + s);
SearchRequest request = new SearchRequest(new String[]{EsConstant.PRODUCT_INDEX}, sourceBuilder);
return request;
}
/**
* 构建结果数据
*
* @param response
* @return
*/
private SearchResult buildSearchResult(SearchResponse response, SearchParam param) {
SearchResult result = new SearchResult();
// 1、返回的所有查询到的商品
SearchHits hits = response.getHits();
List<SkuEsModel> esModels = new ArrayList<>();
if (null != hits.getHits() && hits.getHits().length > 0) {
for (SearchHit hit : hits.getHits()) {
String sourceAsString = hit.getSourceAsString();
SkuEsModel esModel = JSON.parseObject(sourceAsString, SkuEsModel.class);
if (!StringUtils.isEmpty(param.getKeyword())) {
HighlightField skuTitle = hit.getHighlightFields().get("skuTitle");
esModel.setSkuTitle(skuTitle.fragments()[0].string());
}
esModels.add(esModel);
}
}
result.setProducts(esModels);
// 2、当前所有商品涉及到的所有属性
List<SearchResult.AttrVo> attrVos = new ArrayList<>();
ParsedNested attr_agg = response.getAggregations().get("attr_agg");
ParsedLongTerms attr_id_agg = attr_agg.getAggregations().get("attr_id_agg");
for (Terms.Bucket bucket : attr_id_agg.getBuckets()) {
SearchResult.AttrVo attrVo = new SearchResult.AttrVo();
// 1、得到属性的id;
long attrId = bucket.getKeyAsNumber().longValue();
// 2、得到属性的名字
String attrName = ((ParsedStringTerms) bucket.getAggregations().get("attr_name_agg")).getBuckets().get(0).getKeyAsString();
// 3、得到属性的所有值
List<String> attrValues = ((ParsedStringTerms) bucket.getAggregations().get("attr_value_agg")).getBuckets().stream().map(item -> {
String keyAsString = item.getKeyAsString();
return keyAsString;
}).collect(Collectors.toList());
attrVo.setAttrId(attrId);
attrVo.setAttrName(attrName);
attrVo.setAttrValue(attrValues);
attrVos.add(attrVo);
}
result.setAttrs(attrVos);
// 3、当前所有品牌涉及到的所有属性
List<SearchResult.BrandVo> brandVos = new ArrayList<>();
ParsedLongTerms brand_agg = response.getAggregations().get("brand_agg");
for (Terms.Bucket bucket : brand_agg.getBuckets()) {
SearchResult.BrandVo brandVo = new SearchResult.BrandVo();
// 1、得到品牌的id
long brandId = bucket.getKeyAsNumber().longValue();
// 2、得到品牌的名
String brandName = ((ParsedStringTerms) bucket.getAggregations().get("brand_name_agg")).getBuckets().get(0).getKeyAsString();
// 3、得到品牌的图片
String brandImg = ((ParsedStringTerms) bucket.getAggregations().get("brand_img_agg")).getBuckets().get(0).getKeyAsString();
brandVo.setBrandId(brandId);
brandVo.setBrandName(brandName);
brandVo.setBrandImg(brandImg);
brandVos.add(brandVo);
}
result.setBrands(brandVos);
// 4、当前商品所涉及的分类信息
ParsedLongTerms catalog_agg = response.getAggregations().get("catalog_agg");
List<SearchResult.CatalogVo> catalogVos = new ArrayList<>();
List<? extends Terms.Bucket> buckets = catalog_agg.getBuckets();
for (Terms.Bucket bucket : buckets) {
SearchResult.CatalogVo catalogVo = new SearchResult.CatalogVo();
// 得到分类id
String keyAsString = bucket.getKeyAsString();
catalogVo.setCatalogId(Long.parseLong(keyAsString));
// 得到分类名
ParsedStringTerms catalog_name_agg = bucket.getAggregations().get("catalog_name_agg");
String catalog_name = catalog_name_agg.getBuckets().get(0).getKeyAsString();
catalogVo.setCatalogName(catalog_name);
catalogVos.add(catalogVo);
}
result.setCatalogs(catalogVos);
//===========以上从聚合信息获取到=============
// 5、分页信息-页码
result.setPageNum(param.getPageNum());
// 6、分页信息-总记录数
long total = hits.getTotalHits().value;
result.setTotal(total);
// 7、分页信息-总页码-计算
int totalPages = total % EsConstant.PRODUCT_PAGESIZE == 0 ? (int) total / EsConstant.PRODUCT_PAGESIZE : ((int) total / EsConstant.PRODUCT_PAGESIZE + 1);
result.setTotalPages(totalPages);
return result;
}
}
6、页面效果
1、基本数据渲染
将商品的基本属性渲染出来
<div class="rig_tab">
<!-- 遍历各个商品-->
<div th:each="product : ${result.getProduct()}">
<div class="ico">
<i class="iconfont icon-weiguanzhu"></i>
<a href="/static/search/#">关注</a>
</div>
<p class="da">
<a th:href="|http://item.gulimall.com/${product.skuId}.html|" >
<!--图片 -->
<img class="dim" th:src="${product.skuImg}">
</a>
</p>
<ul class="tab_im">
<li><a href="/static/search/#" title="黑色">
<img th:src="${product.skuImg}"></a></li>
</ul>
<p class="tab_R">
<!-- 价格 -->
<span th:text="'¥' + ${product.skuPrice}">¥5199.00</span>
</p>
<p class="tab_JE">
<!-- 标题 -->
<!-- 使用utext标签,使检索时高亮不会被转义-->
<a href="/static/search/#" th:utext="${product.skuTitle}">
Apple iPhone 7 Plus (A1661) 32G 黑色 移动联通电信4G手机
</a>
</p>
<p class="tab_PI">已有<span>11万+</span>热门评价
<a href="/static/search/#">二手有售</a>
</p>
<p class="tab_CP"><a href="/static/search/#" title="谷粒商城Apple产品专营店">谷粒商城Apple产品...</a>
<a href='#' title="联系供应商进行咨询">
<img src="/static/search/img/xcxc.png">
</a>
</p>
<div class="tab_FO">
<div class="FO_one">
<p>自营
<span>谷粒商城自营,品质保证</span>
</p>
<p>满赠
<span>该商品参加满赠活动</span>
</p>
</div>
</div>
</div>
</div>2、筛选条件渲染
将结果的品牌、分类、商品属性进行遍历显示,并且点击某个属性值时可以通过拼接url进行跳转
<div class="JD_nav_logo">
<!--品牌-->
<div class="JD_nav_wrap">
<div class="sl_key">
<span>品牌:</span>
</div>
<div class="sl_value">
<div class="sl_value_logo">
<ul>
<li th:each="brand: ${result.getBrands()}">
<!--替换url-->
<a href="#" th:href="${'javascript:searchProducts("brandId",'+brand.brandId+')'}">
<img src="/static/search/img/598033b4nd6055897.jpg" alt="" th:src="${brand.brandImg}">
<div th:text="${brand.brandName}">
华为(HUAWEI)
</div>
</a>
</li>
</ul>
</div>
</div>
<div class="sl_ext">
<a href="#">
更多
<i style='background: url("image/search.ele.png")no-repeat 3px 7px'></i>
<b style='background: url("image/search.ele.png")no-repeat 3px -44px'></b>
</a>
<a href="#">
多选
<i>+</i>
<span>+</span>
</a>
</div>
</div>
<!--分类-->
<div class="JD_pre" th:each="catalog: ${result.getCatalogs()}">
<div class="sl_key">
<span>分类:</span>
</div>
<div class="sl_value">
<ul>
<li><a href="#" th:text="${catalog.getCatalogName()}" th:href="${'javascript:searchProducts("catalogId",'+catalog.catalogId+')'}">0-安卓(Android)</a></li>
</ul>
</div>
</div>
<!--价格-->
<div class="JD_pre">
<div class="sl_key">
<span>价格:</span>
</div>
<div class="sl_value">
<ul>
<li><a href="#">0-499</a></li>
<li><a href="#">500-999</a></li>
<li><a href="#">1000-1699</a></li>
<li><a href="#">1700-2799</a></li>
<li><a href="#">2800-4499</a></li>
<li><a href="#">4500-11999</a></li>
<li><a href="#">12000以上</a></li>
<li class="sl_value_li">
<input type="text">
<p>-</p>
<input type="text">
<a href="#">确定</a>
</li>
</ul>
</div>
</div>
<!--商品属性-->
<div class="JD_pre" th:each="attr: ${result.getAttrs()}" >
<div class="sl_key">
<span th:text="${attr.getAttrName()}">系统:</span>
</div>
<div class="sl_value">
<ul>
<li th:each="val: ${attr.getAttrValue()}">
<a href="#"
th:text="${val}"
th:href="${'javascript:searchProducts("attrs","'+attr.attrId+'_'+val+'")'}">0-安卓(Android)</a></li>
</ul>
</div>
</div>
</div>3、点击某个属性值时可以通过拼接url进行跳转
function searchProducts(name,value){
//原来的url
//var href = location.href + "";
//if (href.indexOf("?") != -1){
// location.href = location.href + "&" +name+ "=" + value;
//}else {
// location.href = location.href + "?" +name+ "=" + value;
//}
location.href = replaceAndAddParamVal(location.href, name, value, true);
}
/**
* @param url 目前的url
* @param paramName 需要替换的参数属性名
* @param replaceVal 需要替换的参数的新属性值
* @param forceAdd 该参数是否可以重复查询(attrs=1_3G:4G:5G&attrs=2_骁龙845&attrs=4_高清屏)
* @returns {string} 替换或添加后的url
*/
function replaceAndAddParamVal(url, paramName, replaceVal, forceAdd) {
var oUrl = url.toString();
var nUrl;
//如果没有就添加,有就替换
if (oUrl.indexOf(paramName) != -1) {
if (forceAdd/* && oUrl.indexOf(paramName + "=" + replaceVal) == -1*/) {
if (oUrl.indexOf("?") != -1) {
nUrl = oUrl + "&" + paramName + "=" + replaceVal;
} else {
nUrl = oUrl + "?" + paramName + "=" + replaceVal;
}
} else {
var re = eval('/(' + paramName + '=)([^&]*)/gi');
nUrl = oUrl.replace(re, paramName + '=' + replaceVal);
}
} else {
if (oUrl.indexOf("?") != -1) {
nUrl = oUrl + "&" + paramName + "=" + replaceVal;
} else {
nUrl = oUrl + "?" + paramName + "=" + replaceVal;
}
}
return nUrl;
};3、关键字检索查询
function searchByKeyword() {
searchProducts("keyword", $("#keyword_input").val());
}
4、分页数据渲染
将页码绑定至属性pn,当点击某页码时,通过获取pn值进行url拼接跳转页面
<div class="filter_page">
<div class="page_wrap">
<span class="page_span1">
<!-- 不是第一页时显示上一页 -->
<a class="page_a" href="#" th:if="${result.pageNum>1}" th:attr="pn=${result.getPageNum()-1}">
< 上一页
</a>
<!-- 将各个页码遍历显示,并将当前页码绑定至属性pn -->
<a href="#" class="page_a"
th:each="page: ${result.pageNavs}"
th:text="${page}"
th:style="${page==result.pageNum?'border: 0;color:#ee2222;background: #fff':''}"
th:attr="pn=${page}"
>1</a>
<!-- 不是最后一页时显示下一页 -->
<a href="#" class="page_a" th:if="${result.pageNum<result.totalPages}" th:attr="pn=${result.getPageNum()+1}">
下一页 >
</a>
</span>
<span class="page_span2">
<em>共<b th:text="${result.totalPages}">169</b>页 到第</em>
<input type="number" value="1" class="page_input">
<em>页</em>
<a href="#">确定</a>
</span>
</div>
</div>$(".page_a").click(function () {
var pn=$(this).attr("pn");
location.href=replaceAndAddParamVal(location.href,"pageNum",pn,false);
console.log(replaceAndAddParamVal(location.href,"pageNum",pn,false))
})5、页面排序和价格区间
页面排序功能需要保证,点击某个按钮时,样式会变红,并且其他的样式保持最初的样子;
点击某个排序时首先按升序显示,再次点击再变为降序,并且还会显示上升或下降箭头
页面排序跳转的思路是通过点击某个按钮时会向其class属性添加/去除desc,并根据属性值进行url拼接
<div class="filter_top">
<div class="filter_top_left" th:with="p = ${param.sort}, priceRange = ${param.skuPrice}">
<!-- 通过判断当前class是否有desc来进行样式的渲染和箭头的显示-->
<a sort="hotScore"
th:class="${(!#strings.isEmpty(p) && #strings.startsWith(p,'hotScore') && #strings.endsWith(p,'desc')) ? 'sort_a desc' : 'sort_a'}"
th:attr="style=${(#strings.isEmpty(p) || #strings.startsWith(p,'hotScore')) ?
'color: #fff; border-color: #e4393c; background: #e4393c;':'color: #333; border-color: #ccc; background: #fff;' }">
综合排序[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'hotScore') &&
#strings.endsWith(p,'desc')) ?'↓':'↑' }]]</a>
<a sort="saleCount"
th:class="${(!#strings.isEmpty(p) && #strings.startsWith(p,'saleCount') && #strings.endsWith(p,'desc')) ? 'sort_a desc' : 'sort_a'}"
th:attr="style=${(!#strings.isEmpty(p) && #strings.startsWith(p,'saleCount')) ?
'color: #fff; border-color: #e4393c; background: #e4393c;':'color: #333; border-color: #ccc; background: #fff;' }">
销量[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'saleCount') &&
#strings.endsWith(p,'desc'))?'↓':'↑' }]]</a>
<a sort="skuPrice"
th:class="${(!#strings.isEmpty(p) && #strings.startsWith(p,'skuPrice') && #strings.endsWith(p,'desc')) ? 'sort_a desc' : 'sort_a'}"
th:attr="style=${(!#strings.isEmpty(p) && #strings.startsWith(p,'skuPrice')) ?
'color: #fff; border-color: #e4393c; background: #e4393c;':'color: #333; border-color: #ccc; background: #fff;' }">
价格[[${(!#strings.isEmpty(p) && #strings.startsWith(p,'skuPrice') &&
#strings.endsWith(p,'desc'))?'↓':'↑' }]]</a>
<a sort="hotScore" class="sort_a">评论分</a>
<a sort="hotScore" class="sort_a">上架时间</a>
<!--价格区间搜索-->
<input id="skuPriceFrom" type="number"
th:value="${#strings.isEmpty(priceRange)?'':#strings.substringBefore(priceRange,'_')}"
style="width: 100px; margin-left: 30px">
-
<input id="skuPriceTo" type="number"
th:value="${#strings.isEmpty(priceRange)?'':#strings.substringAfter(priceRange,'_')}"
style="width: 100px">
<button id="skuPriceSearchBtn">确定</button>
</div>
<div class="filter_top_right">
<span class="fp-text">
<b>1</b><em>/</em><i>169</i>
</span>
<a href="#" class="prev"><</a>
<a href="#" class="next"> > </a>
</div>
</div>5.1)、综合排序
$(".sort_a").click(function () {
//添加、剔除desc
$(this).toggleClass("desc");
//获取sort属性值并进行url跳转
let sort = $(this).attr("sort");
sort = $(this).hasClass("desc") ? sort + "_desc" : sort + "_asc";
location.href = replaceAndAddParamVal(location.href, "sort", sort,false);
return false;
});5.2)、价格区间搜索函数
$("#skuPriceSearchBtn").click(function () {
var skuPriceFrom = $("#skuPriceFrom").val();
var skuPriceTo = $("#skuPriceTo").val();
location.href = replaceAndAddParamVal(location.href, "skuPrice", skuPriceFrom + "_" + skuPriceTo, false);
})6、是否有库存
<li>
<a href="#" th:with="check = ${param.hasStock}">
<input id="showHasStock" type="checkbox" th:checked="${#strings.equals(check,'1')}">
仅显示有货
</a>
</li> $("#showHasStock").change(function () {
if ($(this).prop('checked')) {
location.href = replaceAndAddParamVal(location.href, "hasStock", 1, false);
} else {
//没选中
var re = eval('/(hasStock=)([^&]*)/gi');
location.href = (location.href + "").replace(re, '');
}
return false;
})7、面包屑导航
1、修改gulimall-search的pom
定义springcloud的版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
</properties>添加依赖管理
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2、主启动类添加 开启远程调用

3、封装面包屑导航数据
修改com.atguigu.gulimall.search.feign.ProducteFeignService类,代码如下
package com.atguigu.gulimall.search.feign;
import com.atguigu.common.utils.R;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient("gulimall-product")
public interface ProducteFeignService {
@GetMapping("/product/attr/info/{attrId}")
public R attrInfo(@PathVariable("attrId") Long attrId);
}
修改com.atguigu.common.utils.R类,代码如下
//利用fastJson进行逆转
public <T> T getData(String key,TypeReference<T> typeReference) {
Object data = get(key);
String s = JSON.toJSONString(data);
T t = JSON.parseObject(s, typeReference);
return t;
}新增“com.atguigu.gulimall.search.vo.AttrResponseVo” 类,代码如下:
package com.atguigu.gulimall.search.vo;
import lombok.Data;
@Data
public class AttrResponseVo {
/**
* 属性id
*/
private Long attrId;
/**
* 属性名
*/
private String attrName;
/**
* 是否需要检索[0-不需要,1-需要]
*/
private Integer searchType;
/**
* 属性图标
*/
private String icon;
/**
* 可选值列表[用逗号分隔]
*/
private String valueSelect;
/**
* 属性类型[0-销售属性,1-基本属性,2-既是销售属性又是基本属性]
*/
private Integer attrType;
/**
* 启用状态[0 - 禁用,1 - 启用]
*/
private Long enable;
/**
* 所属分类
*/
private Long catelogId;
/**
* 快速展示【是否展示在介绍上;0-否 1-是】,在sku中仍然可以调整
*/
private Integer showDesc;
private Long attrGroupId;
private String catelogName;
private String groupName;
private Long[] catelogPath;
}
修改“com.atguigu.gulimall.search.vo.SearchResult” 类,代码如下:
package com.atguigu.gulimall.search.vo;
import com.atguigu.common.to.es.SkuEsModel;
import lombok.Data;
import java.util.ArrayList;
import java.util.List;
@Data
public class SearchResult {
/**
* 查询到的商品信息
*/
private List<SkuEsModel> products;
private Integer pageNum;//当前页码
private Long total;//总记录数
private Integer totalPages;//总页码
private List<Integer> pageNavs;//导航页码
private List<BrandVo> brands;//当前查询到的结果,所有涉及到的品牌
private List<CatalogVo> catalogs;//当前查询到的结果,所有涉及到的分类
private List<AttrVo> attrs;//当前查询到的结果,所有涉及到的属性
//=====================以上是返给页面的信息==========================
//面包屑导航数据
private List<NavVo> navs = new ArrayList<>();
@Data
public static class NavVo{
private String navName;
private String navValue;
private String link;
}
@Data
public static class BrandVo{
private Long brandId;
private String brandName;
private String brandImg;
}
@Data
public static class CatalogVo{
private Long catalogId;
private String catalogName;
private String brandImg;
}
@Data
public static class AttrVo{
private Long attrId;
private String attrName;
private List<String> attrValue;
}
}
修改“com.atguigu.gulimall.search.vo.SearchParam” 类,代码如下:

修改“com.atguigu.gulimall.search.controller.SearchController” 类,代码如下:
@GetMapping("/list.html")
public String listPage(SearchParam searchParam, Model model, HttpServletRequest request) {
String queryString = request.getQueryString();
searchParam.set_queryString(queryString);
SearchResult result = mallSearchService.search(searchParam);
System.out.println("====================" + result);
model.addAttribute("result", result);
return "list";
}修改“com.atguigu.gulimall.search.service.impl.MallSearchServiceImpl” 类,代码如下:
在封装结果时,将查询的属性值进行封装
// 8、构建面包屑导航功能
List<String> attrs = param.getAttrs();
if (attrs != null && attrs.size() > 0) {
List<SearchResult.NavVo> navVos = attrs.stream().map(attr -> {
String[] split = attr.split("_");
SearchResult.NavVo navVo = new SearchResult.NavVo();
// 8.1 设置属性值
navVo.setNavValue(split[1]);
// 8.2 查询并设置属性名
try {
R r = producteFeignService.attrInfo(Long.parseLong(split[0]));
if (r.getCode() == 0) {
AttrResponseVo attrResponseVo = JSON.parseObject(JSON.toJSONString(r.get("attr")), new TypeReference<AttrResponseVo>() {
});
navVo.setNavName(attrResponseVo.getAttrName());
}else {
navVo.setNavName(split[0]);
}
} catch (Exception e) {
}
// 8.3 设置面包屑跳转链接(当点击该链接时剔除点击属性)
// 取消了这个面包屑以后,我们就要跳转到那个地方,将请求地址的url里面的当前置空
// 拿到所有的查询条件,去掉当前
String queryString = param.get_queryString();
String encode = null;
try {
encode = URLEncoder.encode(attr, "UTF-8");
encode = encode.replace("+","20%");//浏览器对空格编码和java不一样
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
String replace = queryString.replace("&attrs=" + encode, "");
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty()?"":"?"+replace));
return navVo;
}).collect(Collectors.toList());
result.setNavs(navVos);
}
return result;因为远程调用可以给他添加缓存
修改“com.atguigu.gulimall.product.service.impl.AttrServiceImpl”类,代码如下:

页面渲染
<div class="JD_ipone_one c">
<!-- 遍历面包屑功能 -->
<a th:href="${nav.link}" th:each="nav:${result.navs}"><span th:text="${nav.navName}"></span>:<span th:text="${nav.navValue}"></span> x</a>
</div>5、 条件筛选联动
就是将品牌和分类也封装进面包屑数据中,并且在页面进行th:if的判断,当url有该属性的查询条件时就不进行显示了
修改“com.atguigu.gulimall.search.service.impl.MallSearchServiceImpl”类,代码如下:
// 8、构建面包屑导航功能
// 8.1、属性
List<String> attrs = param.getAttrs();
if (attrs != null && attrs.size() > 0) {
List<SearchResult.NavVo> navVos = attrs.stream().map(attr -> {
String[] split = attr.split("_");
SearchResult.NavVo navVo = new SearchResult.NavVo();
// 8.1.1、设置属性值
navVo.setNavValue(split[1]);
// 8.1.2、查询并设置属性名
try {
R r = producteFeignService.attrInfo(Long.parseLong(split[0]));
result.getAttrIds().add(Long.valueOf(split[0]));
if (r.getCode() == 0) {
AttrResponseVo attrResponseVo = JSON.parseObject(JSON.toJSONString(r.get("attr")), new TypeReference<AttrResponseVo>() {
});
navVo.setNavName(attrResponseVo.getAttrName());
} else {
navVo.setNavName(split[0]);
}
} catch (Exception e) {
}
// 8.1.3、设置面包屑跳转链接(当点击该链接时剔除点击属性)
// 取消了这个面包屑以后,我们就要跳转到那个地方,将请求地址的url里面的当前置空
// 拿到所有的查询条件,去掉当前
String replace = replaceQueryString(param, attr, "attrs");
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty() ? "" : "?" + replace));
return navVo;
}).collect(Collectors.toList());
result.setNavs(navVos);
}
// 8.2、品牌
if (null != param.getBrandId() && param.getBrandId().size() > 0) {
List<SearchResult.NavVo> navs = result.getNavs();
SearchResult.NavVo navVo = new SearchResult.NavVo();
navVo.setNavName("品牌");
// 远程查询所有品牌
R r = producteFeignService.brandInfo(param.getBrandId());
if (0 == r.getCode()) {
List<BrandVo> brands = r.getData("brands", new TypeReference<List<BrandVo>>() {
});
StringBuffer buffer = new StringBuffer();
String replace = "";
for (BrandVo brand : brands) {
buffer.append(brand.getName() + ";");
replace = replaceQueryString(param, brand.getBrandId() + "", "brandId");
}
navVo.setNavValue(buffer.toString());
navVo.setLink("http://search.gulimall.com/list.html" + (replace.isEmpty() ? "" : "?" + replace));
}
navs.add(navVo);
}
// 8.3、分类,不需要导航取消
return result;
}
/**
* 替换原生的所有的查询条件
*
* @param param
* @param value
* @param key
* @return
*/
private String replaceQueryString(SearchParam param, String value, String key) {
String queryString = param.get_queryString();
String encode = null;
try {
encode = URLEncoder.encode(value, "UTF-8");
encode = encode.replace("+", "20%");//浏览器对空格编码和java不一样
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return queryString.replace("&" + key + "=" + encode, "");
}attrIds作为记录url已经有的属性id

远程调用获取品牌信息
修改“com.atguigu.gulimall.search.feign.ProducteFeignService”类,代码如下:
@RequestMapping("/product/brand/infos")
R brandInfo(@RequestParam("brandIds") List<Long> brandIds);修改“com.atguigu.gulimall.search.vo.BrandVo”类,代码如下:
package com.atguigu.gulimall.search.vo;
import lombok.Data;
@Data
public class BrandVo {
private Long brandId;
private String name;
}
修改“com.atguigu.gulimall.product.app.BrandController”类,代码如下:
/**
* 根据品牌id查询品牌信息
*/
@RequestMapping("/infos")
public R info(@RequestParam("brandIds") List<Long> brandIds){
List<BrandEntity> brands = brandService.getBrandsById(brandIds);
return R.ok().put("brands", brands);
}修改“com.atguigu.gulimall.product.service.BrandService”类,代码如下:
List<BrandEntity> getBrandsById(List<Long> brandIds);修改“com.atguigu.gulimall.product.service.impl.BrandServiceImpl”类,代码如下:
@Override
public List<BrandEntity> getBrandsById(List<Long> brandIds) {
List<BrandEntity> brandId = baseMapper.selectList(new QueryWrapper<BrandEntity>().in("brand_id", brandIds));
return brandId;
}修改gulimall-search的list.html
<!--品牌-->
<div th:if="${#strings.isEmpty(brandid)}" class="JD_nav_wrap">
<div class="sl_key">
<span><b>品牌:</b></span>
</div>
<div class="sl_value">
<div class="sl_value_logo">
<ul>
<li th:each="brand:${result.brands}">
<a href="/static/search/#"
th:href="${'javascript:searchProducts("brandId",'+brand.brandId+')'}">
<img th:src="${brand.brandImg}" alt="">
<div th:text="${brand.brandName}">
华为(HUAWEI)
</div>
</a>
</li>
</ul>
</div>
</div>
<div class="sl_ext">
<a href="/static/search/#">
更多
<i style='background: url("image/search.ele.png")no-repeat 3px 7px'></i>
<b style='background: url("image/search.ele.png")no-repeat 3px -44px'></b>
</a>
<a href="/static/search/#">
多选
<i>+</i>
<span>+</span>
</a>
</div>
</div>
<!--分类-->
<div class="JD_nav_wrap">
<div class="sl_key">
<span><b>分类:</b></span>
</div>
<div class="sl_value">
<ul>
<li th:each="catalog:${result.catalogs}">
<a href="/static/search/#"
th:href="${'javascript:searchProducts("catalog3",'+catalog.catalogId+')'}"
th:text="${catalog.catalogName}">5.56英寸及以上</a>
</li>
</ul>
</div>
<div class="sl_ext">
<a href="/static/search/#">
更多
<i style='background: url("image/search.ele.png")no-repeat 3px 7px'></i>
<b style='background: url("image/search.ele.png")no-repeat 3px -44px'></b>
</a>
<a href="/static/search/#">
多选
<i>+</i>
<span>+</span>
</a>
</div>
</div>
<!--其他所有需要展示的属性-->
<div class="JD_pre" th:each="attr:${result.attrs}" th:if="${!#lists.contains(result.attrIds,attr.attrId)}">
<div class="sl_key">
<span th:text="${attr.attrName}">屏幕尺寸:</span>
</div>
<div class="sl_value">
<ul>
<li th:each="val:${attr.attrValue}">
<a href="/static/search/#"
th:href="${'javascript:searchProducts("attrs","'+attr.attrId+'_'+val+'")'}"
th:text="${val}">5.56英寸及以上</a></li>
</ul>
</div>
</div>
















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









