










一文速通半监督学习:桥接有标签与无标签数据

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
前言
论文看到哪学到哪 ^ - ^
在机器学习的世界里,我们通常遇到这样一个现实问题:标注数据(有标签的数据)往往昂贵且难以获得,而未标注数据(无标签的数据)却大量存在,易于收集。
假设你正在尝试教会计算机区分猫和狗的照片,但只有少数照片是打上了“猫”或“狗”的标签,大部分照片都没有标签。这时候,半监督学习就闪亮登场了,它是一种使用大量未标注数据和少量标注数据进行学习的方法,旨在提高学习效率和准确性。
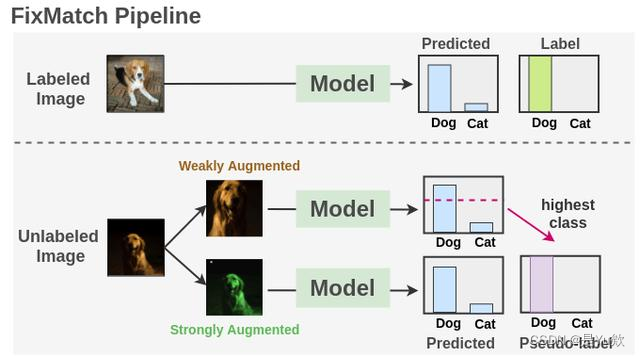
参考:https://blog.csdn.net/qq_44015059/article/details/106448533
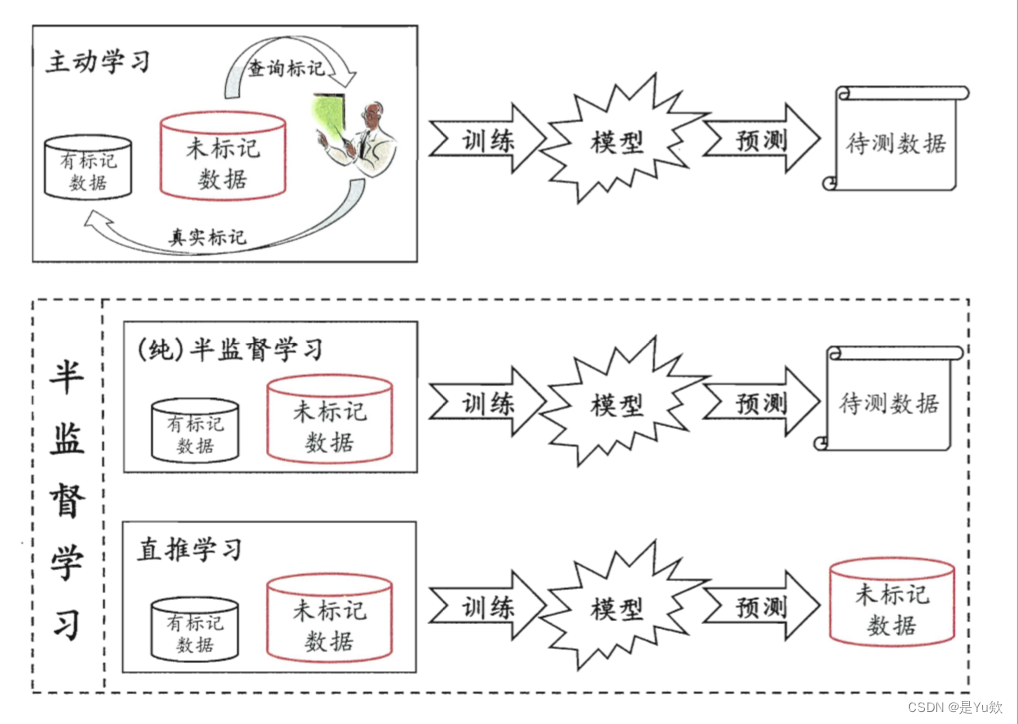
背景补充:监督学习、半监督学习、无监督学习
监督学习、半监督学习、无监督学习示意图:
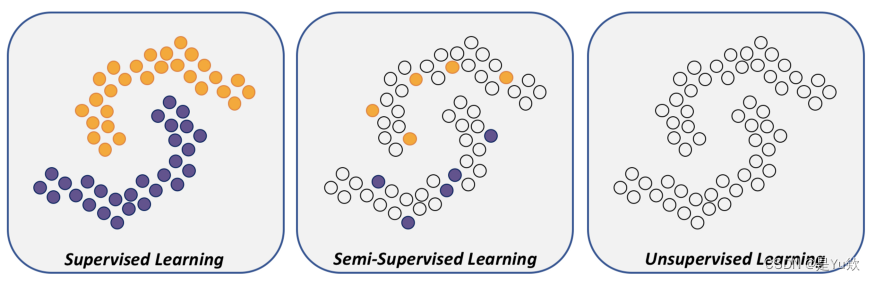
监督学习
半监督学习(Semi-supervised Learning)的魔法
想象一下,你在一个巨大的水果园中,有各式各样的水果。你的任务是区分哪些是苹果,哪些是橙子。
如果每个水果都有标签告诉你这是什么,那将是一件非常简单的事情,但现实是,只有极少数水果有标签。这时,你怎么办?
如果你注意到即使在没有标签的水果中,某些水果的形状、颜色与那些有标签的水果相似,你可能会推测它们属于相同的类别。
这就是半监督学习的基本思想:利用未标注数据之间的相似性,来帮助我们更好地理解和利用有限的标注数据。
一、半监督学习的三个常见的基本假设
在半监督学习领域,模型的学习过程大多建立在一些基本假设上,这些假设帮助模型利用未标注数据提高学习效果。以下是半监督学习中三个常见的基本假设:
1. 连续性假设(Smoothness Assumption)
连续性假设是最直观的一种,它认为如果两个样本在特征空间中彼此非常接近,那么它们很可能属于同一个类别。
想象一下,如果你在一个公园里看到两个相似的花朵生长在一起,你可能会自然而然地认为它们属于同一种花。在半监督学习中,这个假设指导模型将相似的数据点分类到相同的类别,即使其中一些数据点没有标签。
2. 聚类假设(Cluster Assumption)
聚类假设进一步扩展了连续性假设,它认为数据会自然地聚集成簇,并且同一个簇中的数据点更有可能属于同一个类别。
可以把这个假设比作是在一次聚会中,人们往往会和兴趣相近的人群聚在一起,即使你不知道每个人具体的兴趣,也可以通过他们聚集的群体来推测。在半监督学习中,这个假设帮助模型利用数据的内在结构,即使很多数据点没有明确的标签。
3. 流形假设(Manifold Assumption)
流形假设基于这样一个观点:高维数据实际上可能分布在一个低维流形上。这个假设背后的直觉是,即使数据的维度很高,其真实的、有意义的结构可能嵌入在一个低维空间中,这个空间能够更好地捕捉数据的本质特性。
举个例子,你可以想象地球是一个三维的球体,但在大部分时候,我们可以在二维的地图上找到我们需要的所有信息。在半监督学习中,利用流形假设可以帮助模型在低维空间中学习数据的内在结构,从而更有效地进行分类或回归任务。
这三个假设是半监督学习研究和应用中的基石,它们各自从不同的角度出发,共同指导着如何更好地利用未标注数据来提升学习模型的性能。
二、常见的半监督 机器学习方法
1. 自训练(Self-training)
自训练就像是一个学生通过阅读大量相关、但不是专门为考试准备的材料来学习,然后用这些知识去解答一些练习题。
在机器学习中,这意味着首先使用少量的有标签数据训练模型,然后使用这个模型去预测未标注数据的标签。
接着,模型把一些预测结果最自信的未标注数据(及其预测的标签)加入训练集中,再次训练模型。
这个过程反复进行,直到模型性能不再提升或达到预定的迭代次数。
2. 半监督支持向量机(S3VM)
想象你正在玩一场将球分到正确篮子中的游戏,但篮子的标签只有一小部分是可见的。
你的目标是根据这些已知标签的球,以及球之间的相似性,推断出其余篮子的标签。
在半监督支持向量机中,我们不仅利用有标签的数据找到最佳的分界线(或决策边界),还试图确保未标注的数据尽可能远离这条分界线,增强模型的泛化能力。
3. 图基方法(Graph-based Methods)
图基方法可以被比喻为在一个大型社交网络中寻找朋友圈的过程。
每个节点代表一个数据点,节点之间的连线表示数据点之间的相似性。
即使只有一小部分用户(数据点)明确标注了他们的兴趣爱好(标签),通过观察他们与哪些人互动最频繁,我们也可以推断出未标注用户的兴趣。
在图基方法中,通过构建一个数据点的图表示,利用图的结构性质来推断未标注数据点的标签。
三、常见的半监督 深度学习方法
如果要给半监督深度学习下个定义,大概就是,在有标签数据+无标签数据混合成的训练数据中使用的深度学习算法。
半监督深度学习算法可以总结为三类:
1.无标签数据预训练网络,利用有标签数据微调(fine-tune);
2.有标签数据训练网络,利用从网络中得到的深度特征来做半监督算法;
3.让网络 work in semi-supervised fashion。即,把网络对无标签数据的预测,作为无标签数据的标签(即 Pseudo label),用来对网络进行训练,其思想就是一种简单自训练。
就像是在制作一顿美味大餐时,你手头有一些精心调制的酱料(有标签的数据)和大量的基本食材(未标注的数据)。虽然只用精心调制的酱料就能做出不错的菜,但如果能巧妙利用那些基本食材,你的大餐会更加丰富多彩。
下面,我们用一些通俗易懂的比喻,介绍几种半监督深度学习的“烹饪技巧”。
半监督深度学习方法结合了深度学习的强大表示能力和半监督学习利用未标注数据的优势,以提高模型在少量标注数据情况下的性能。这些方法特别适用于图像识别、语音识别和文本处理等领域,其中未标注数据的获取相对容易,但标注过程却费时费力。以下是一些主流的半监督深度学习方法:
1. 自编码器:烹饪前的味道测试
自编码器是一种利用未标注数据学习数据编码的深度学习模型。它们通过无监督学习的方式学习输入数据的有效表示(编码),然后使用这些表示来重建输入(解码)。在半监督学习中,自编码器可以用来学习数据的内在结构和特征,然后这些特征可以用于监督学习任务,如分类或回归。
想象一下,你在烹饪前尝试食材,了解其原始味道,然后再根据这些味道调整你的菜肴。自编码器就是这样一种工具,它先“尝试”(学习)数据的基本特征,然后尝试重建(再现)它。这个过程帮助模型理解数据的内在结构,即使是那些没有“味道标签”的食材。
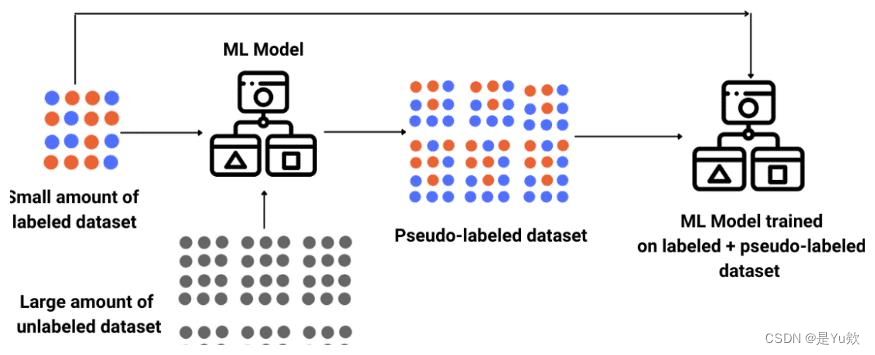
2. 生成对抗网络(GANs):厨房里的较量
生成对抗网络(GANs)由一个生成器和一个判别器组成。①生成器 生成尽可能接近真实数据的数据,而②判别器 则试图区分真实数据和生成的数据。在半监督学习设置中,判别器的任务不仅是区分真假数据,还要对真实数据进行分类。这种方法可以利用大量未标注数据来改善判别器的性能,从而提高分类准确率。
将生成对抗网络想象成一场厨艺比赛,其中一个厨师(生成器)尝试制作出看起来像真正美食的菜肴,而另一个厨师(判别器)的任务是分辨这道菜是不是真的。这场较量促进了两位厨师的技良互补,结果是生成器学会制作越来越逼真的“菜肴”,即使它们是基于未标注的“食材”。
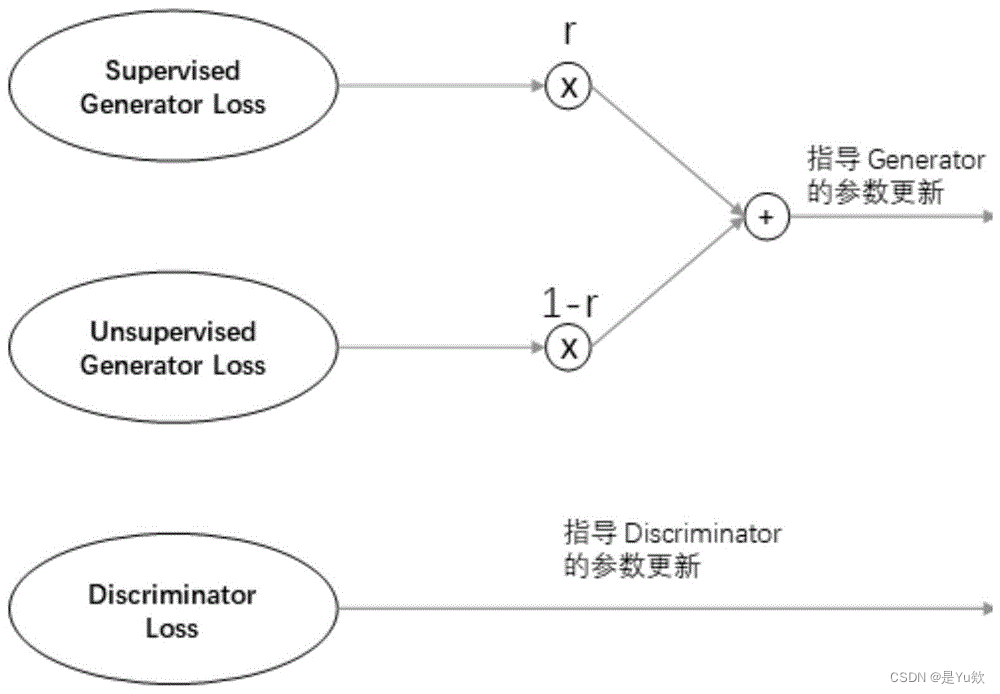
3. 对比学习(Contrastive Learning):寻找食材的家族相似性
对比学习是一种无监督学习方法,近年来被广泛应用于半监督学习。它通过最大化相似样本之间的一致性,并最小化不同样本之间的一致性来学习表示。在半监督学习场景中,对比学习可以用来利用未标注数据学习鲁棒的特征表示,然后这些特征可以用于下游的分类或其他监督学习任务。
对比学习就像是将一堆食材按照它们的味道和特性进行分组。即使没有人告诉你每个食材具体是什么,通过比较它们之间的相似性,你可以将它们归入不同的类别(比如,辣的、甜的、酸的等)。在半监督学习中,对比学习帮助模型通过观察数据之间的相似性和差异性来学习有用的表示,即使大部分数据没有直接的“味道标签”。
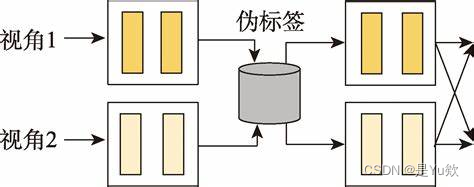
4. 伪标签(Pseudo Labeling):假装你是大厨
伪标签是一种简单而有效的半监督学习技术。首先,使用有标签的数据训练一个深度学习模型。然后,这个模型被用来预测未标注数据的标签,创建伪标签。最后,这些伪标签的数据与真实标签的数据一起用于进一步训练模型。这种方法可以迭代地进行,随着模型性能的提高,伪标签的质量也会提高。
使用伪标签的方法就像是让一个实习厨师(初始模型)尝试根据自己的直觉给食材贴上标签,然后让一个经验丰富的大厨(训练过程)来检查这些标签,并指导实习厨师如何改进。通过这个过程,实习厨师逐渐学会如何正确地识别和分类食材,即使一开始他们对很多食材不太熟悉。
5. 半监督序列学习(Semi-supervised Sequence Learning)
在自然语言处理(NLP)领域,半监督序列学习方法,如BERT和其它变体,通过预训练模型在大量未标注文本上学习语言表示,然后在少量标注数据上进行微调,用于特定的下游任务,如情感分析或问答系统。
在处理文本或语音数据时,半监督序列学习方法就像是掌握了一本包含秘密调味配方的食谱。模型首先在大量的文本或语音“原料”上进行“预烹饪”(预训练),学习语言的基本结构和模式。然后,使用少量精心调制的“调味品”(有标签的数据)进行“精细调味”(微调),使最终的菜肴(模型性能)更加出色。
通过这些创新的“烹饪技巧”,半监督深度学习方法能够有效地利用大量未标注的数据,即使在标注数据相对稀缺的情况下也能实现出色的性能。这就像是在有限的资源下做出一桌丰盛的大餐,不仅满足了味蕾,也极大地拓展了我们的烹饪(学习)能力。
这些方法展示了深度学习如何通过结合未标注数据的力量,即使在标注数据有限的情况下,也能实现显著的性能提升。随着深度学习技术的不断进步和创新,半监督深度学习无疑将继续在各种应用领域中扮演重要角色。
四、半监督学习的训练目标
拿最简单的图片分类任务进行举例。
最初在有监督学习的背景下,所有人考虑的是如何改变网络结构可以使检测结果更加准确,因此产生了一些列的基础网络如:Lenet,Alexnet,vgg,resnet等等。
之后考虑到半监督学习的任务目标,需要改变除了网络结构模型之外,
操作:①数据处理架构(数据增强等任务),②构造新的损失函数,③网络模型外的整体架构等方面,
目的:在保持原有网络模型不变的基础上,充分利用label data和unlabel data,使最终的性能尽可能贴近有监督学习的性能指标
半监督学习的训练目标是利用有限的标注数据和大量的未标注数据来训练模型,以达到提高模型性能的目的。在半监督学习中,虽然未标注数据没有显式的标签,但它们包含的隐含信息对于学习过程是非常有价值的。因此,半监督学习的核心目标可以从以下几个方面进行阐述:
1. 提高模型的泛化能力
半监督学习的主要目标之一是提高模型在未见过的数据上的性能,即提高模型的泛化能力。通过同时利用有标签和无标签数据,模型能够更好地理解数据的整体分布,从而在处理新的、未见过的数据时表现得更加鲁棒。
2. 利用未标注数据挖掘深层信息
未标注数据量通常远大于有标签数据,含有丰富的潜在信息。半监督学习通过探索这些数据的结构和分布特性,帮助模型学习到更深层次的特征表示,这些特征对于任务的完成是非常有帮助的。
3. 减少人工标注的需求
标注大量数据是一项耗时且成本高昂的工作。半监督学习的另一个关键目标是减少对人工标注数据的依赖,使模型能够在只有少量标注数据的情况下也能进行有效的训练。这对于资源有限的场景尤为重要。
4. 提升数据利用效率
在许多应用场景中,收集数据相对容易,但标注数据却很困难。半监督学习使得未标注数据也能够被有效利用,极大地提升了数据的利用效率,允许模型从更多的数据中学习,而不仅仅是那些被标注过的部分。
5. 适应复杂或少样本的任务
对于一些复杂的任务或是标注样本极为稀缺的情况,半监督学习提供了一种有效的解决方案。通过合理利用大量的未标注数据,模型可以在这些挑战性任务中获得更好的学习效果。
总的来说,半监督学习的训练目标是通过有效整合有标签和无标签数据,提高模型的学习效率和性能,同时减少对大量标注数据的依赖。这种方法在许多实际应用中显示出了其强大的潜力和价值。
结语
半监督学习就像是在有限的线索下解决一场谜题,它充分利用了未标注数据的潜力,弥补了标注数据稀缺的问题。
半监督学习不仅能够让你在数据不足的情况下仍能进行有效的机器学习项目,也能够让你的模型更加鲁棒、准确。
随着技术的进步和创新,半监督学习无疑会在未来的机器学习和人工智能领域扮演更加重要的角色。
















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











