






1 准备工作
1.1 安装docker
见我之前的文章。
1.2 利用docker安装mysql
这里我准备了两个mysql服务
在这里我主要想说下下面这几个问题:
1.2.1 mysql容器的运行
docker run -itd --name hostS3308 -p 3308:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
docker run -itd --name hostS3309 -p 3309:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
在这里我想详细说下里面的参数和更详细的参数(这次暂时不用,但是后续如果真正生产要用docker安装的时候需要)
docker run -p 3306:3306 --name mymysql -v $PWD/conf:/etc/mysql/conf.d -v $PWD/logs:/logs -v $PWD/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql
-p 3306:3306:将容器的 3306 端口映射到主机的 3306 端口。
-v -v $PWD/conf:/etc/mysql/conf.d:将主机当前目录下的 conf/my.cnf 挂载到容器的 /etc/mysql/my.cnf。
-v $PWD/logs:/logs:将主机当前目录下的 logs 目录挂载到容器的 /logs。
-v $PWD/data:/var/lib/mysql :将主机当前目录下的data目录挂载到容器的 /var/lib/mysql 。
-e MYSQL_ROOT_PASSWORD=123456:初始化 root 用户的密码。
1.2.2 mysql密码加密规则的修改
如果不修改,用客户端工具打开会报错:

进入容器:
docker exec -it 62349aa31687 /bin/bash
进入mysql:
mysql -uroot -p
授权:
mysql> GRANT ALL ON *.* TO 'root'@'%';
刷新权限:
mysql> flush privileges;
更新加密规则:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER;
更新root用户密码:
mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
刷新权限:
mysql> flush privileges;
1.2.3 docker 内部的vim命令安装
如果不安装,就没有办法编辑mysql的配置文件
apt-get update
apt-get install vim
2 Mycat的server.xml配置
首先备份,再做修改
2.1 配置sequnceHandlerType属性
<property name="sequnceHandlerType">1</property>
指定使用Mycat全局序列的类型:0为本地文件方式,1为数据库方式,2为时间戳序列方式,对于读写分离而言,是不需要考虑主键生成方式的,也就是不需要配置全局序列号的。
2.2 设置连接mycat时的用户名和密码, 逻辑库
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">mycatdb</property>
</user>
详细见上一篇参数解释
2.3 完整配置信息
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<!-- 1为开启实时统计、0为关闭 -->
<property name="useSqlStat">0</property>
<!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(
如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--off heap for merge/order/group/limit 1开启 0关闭-->
<property name="useOffHeapForMerge">1</property>
<!--单位为m-->
<property name="memoryPageSize">1m</property>
<!--单位为k-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--单位为m-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<user name="mycat">
<property name="password">123456</property>
<property name="schemas">mycatdb</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">mycatdb</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
3. Mycat的schema.xml配置
3.1 说明
schema用于配置逻辑库。
只做读写分离,不做分库分表,Mycat只是帮我们转发一下请求,读转发到从库,写转发到主库,则schema标签里面不用配置table给schema标签加上属性dataNode,配置dataNode的名字(name)。
3.2 完整配置
一主一从配置:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--只做读写分离,不做分库分表,Mycat只是帮我们转发一下请求,读转发到从库,写转发到主库,则schema标签里面不用配置table-->
<schema name="mycatdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<!--配置真实存在的物理数据库-->
<dataNode name="dn1" dataHost="localhost1" database="my_test" />
<dataHost name="localhost1"
maxCon="1000"
minCon="10"
balance="1"
writeType="0"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3308" url="116.85.15.xxx:3308" user="root" password="123456">
<readHost host="hostS3309" url="116.85.15.xxx:3309" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
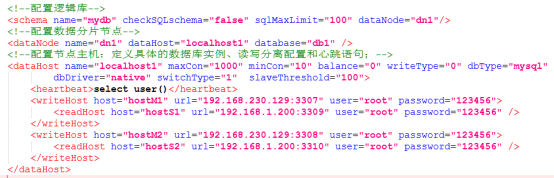
双主双从配置(或者下一篇双主双从配置):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--只做读写分离,不做分库分表,Mycat只是帮我们转发一下请求,读转发到从库,写转发到主库,则schema标签里面不用配置table-->
<schema name="mycatdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<!--配置真实存在的物理数据库-->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataHost name="localhost1"
maxCon="1000"
minCon="10"
balance="1"
writeType="0"
dbType="mysql"
dbDriver="native"
switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM3307" url="localhost:3307" user="root" password="123456">
<readHost host="hostS3308" url="localhost:3308" user="root" password="123456" />
<readHost host="hostS3309" url="localhost:3309" user="root" password="123456" />
</writeHost>
<writeHost host="hostM3308" url="localhost:3308" user="root" password="123456">
<readHost host="hostS3307" url="localhost:3307" user="root" password="123456" />
<readHost host="hostS3310" url="localhost:3310" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
3.3 详细解释
3.3.1 配置dataNode
(1)作用
dataNode定义了Mycat中的数据节点,也就是我们通常说所的数据分片,一个dataNode标签就是一个独立的数据分片,通俗理解,一个分片就是一个物理数据库。
(2)配置说明
- name
定义数据节点的名字,这个名字需要是唯一的,这个名字在schema里面会使用到; - dataHost
用于定义该分片属于哪个数据库实例的,属性值是引用dataHost标签上定义的name属性 - database
用于对应真实的数据库名,必须是真实存在的;
3.3.2 配置dataHost
(1)作用
定义具体的数据库实例、读写分离配置和心跳语句;
(2)配置说明
- balance属性
负载均衡类型,目前的取值有4种:
balance=“0”, 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
balance=“1”,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
balance=“2”,所有读操作都随机的在writeHost、readhost上分发。
balance=“3”,所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力。
推荐balance设置为1。
-
writeType
已过时,1.6版本就不用了 -
switchType属性
用于指定主服务器发生故障后的切换类型。
-1 表示不自动切换
1 默认值,自动切换(推荐)
2 基于MySQL主从同步的状态决定是否切换
3 基于MySQL galary cluster的切换机制(适合集群)(1.4.1)
通常情况下,我们MySQL采用双主双从的模式下,switchType为1即可。因为双主从模式下,主从同步关系很复杂,不能根据MySQL的状态来切换。只需要在一个主出问题后,切换到另外的主。
-
heartbeat标签
用于和后端数据库进行心跳检查的语句,检测MySQL数据库是否正常运行。
当switchType为1时,mysql心跳检查语句是select user()。
当switchType为2时,mysql心跳检查语句是show slave status。
当switchType为3时,mysql心跳检查语句是show status like 'wsrep%'。 -
writeHost与readHost标签
这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池。唯一不同的是,writeHost指定写实例、readHost指定读实例,组合这些读写实例来满足系统的要求。在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自动的检测到,并切换到备用的writeHost上去。
3.4 推荐配置
switchType设置为1,表示自动切换主从。
heartbeat语句为 select user()。
balance一般设置为1即可。
- 一主两从配置示例:

- 双主双从配置示例:
配置完毕重启Mycat。
4 测试读写分离
就此读写分离配置完毕,开始测试读写分离。
分别在读写库创建相同的表,插入不同的数据,然后执行查询语句。
5 配置MySQL主从复制
MySql可以通过 主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Proxy)来提升数据库的并发负载能力 这样的方案来进行部署与实施的。

首先我打算将3308这个数据库作为主库,3309当做从库,主库为写库,从库为读库。
首先进入到docker内部,配置/etc/mysql/my.cnf。
5.1 主从复制原理
- master将操作记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary logevents);
- Slave通过I/O Thread异步将master的binary logevents拷贝到它的中继日志(relay log);
- Slave执行relay日志中的事件,匹配自己的配置将需要执行的数据,在slave服务上执行一遍从而达到复制数据的目的。

5.2 3308主库配置

指定服务ID,开启binlog日志记录,在my.cnf中加入:
server-id=137 // 唯一
log-bin=dbstore_binlog //日志
binlog-do-db=db_store //需要同步的db 可以不写,同步所有
skip-name-resolve //禁止dns 反解析,也可以不配置,需要配置/etc/hosts 文件,域名和IP的对应关系。
master 其他相关配置:
1. log-bin=mysql-bin
控制master的是否开启binlog记录功能;二进制文件最好放在单独的目录下,这不但方便优化、更方便维护。如下例子:要重新调整logbin的路径为“/home/mysql/binlog”。
log_bin=/home/mysql/binlog/binlog.log需要注意:指定目录时候一定要以*.log结尾,即不能仅仅指定到文件夹的级别,否则在重启mysql时会报错。
2. server-id=1
每个server服务的标识,在master/slave环境中,此变量一定要不一样。
3. expire_logs_days=15
通过此来实现master自动删除binlog。
4. innodb_flush_log_at_trx_commit=1
此参数表示在事务提交时,处理重做日志的方式;此变量有三个可选值0,1,2:
0:当事务提交时,并不将事务的重做日志写入日志文件,而是等待每秒刷新一次
1:当事务提交时,将重做日志缓存的内容同步写到磁盘日志文件,为了保证数据一致性,在replication环境中使用此值。
2:当事务提交时,将重做日志缓存的内容异步写到磁盘日志文件(写到文件系统缓存中)
建议必须设置innodb_flush_log_at_trx_commit=1
5.sync_binlog=1
1、此参数表示每写缓冲多少次就同步到磁盘;
2、sync_binlog=1表示同步写缓冲和磁盘二进制日志文件,不使用文件系统缓存
在使用innodb事务引擎时,在复制环境中,为了保证最大的可用性,都设置为“1”,但会对影响io的性能。
3、即使设置为“1”,也会有问题发生:
假如当二进制日志写入磁盘,但事务还没有commit,这个时候宕机,当服务再次起来的恢复的时候,无法回滚以及记录到二进制日志的未提交的内容;这个时候就会造成master和slave数据不一致
解决方案:
需要参数innodb_support_xa=1来保证。建议必须设置
6 .innodb_support_xa=1
此参数与XA事务有关,它保证了二进制日志和innodb数据文件的同步,保证复制环境中数据一致性。建议必须设置
7.binlog-do-db=skate_db
只记录指定数据库的更新到二进制日志中
8. binlog-do-table=skate_tab
只记录指定表的更新到二进制日志中(意思是只同步指定库)
9. binlog-ignore-db=skate_db
忽略指定数据库的更新到二进制日志中(意思是只同步非指定库)
10.log_slave_updates=1
此参数控制slave数据库是否把从master接受到的log并在本slave执行的内容记录到slave的二进制日志中
在级联复制环境中(包括双master环境),这个参数是必须的
11.binlog_format=statement|row|mixed
控制以什么格式记录二进制日志的内容,默认是mixed
12. max_binlog_size
master的每个二进制日志文件的大小,默认1G
13.binlog_cache_size
1、所有未提交的事务都会被记录到一个缓存或临时文件中,待提交时,统一同步到二进制日志中,
2、此变量是基于session的,每个会话开启一个binlog_cache_size大小的缓存。
3、通过变量“Binlog_cache_disk_use”和“Binlog_cache_use”来设置binlog_cache_size的大小。
说明:
Binlog_cache_disk_use: 使用临时文件写二进制日志的次数
Binlog_cache_use: 使用缓冲记写二进制的次数
14.auto_increment_increment=2 //增长的步长
auto_increment_offset=1 //起始位置
在双master环境下可以防止键值冲突
5.3 3309从库配置

server-id=1
log-bin=dbstore_binlog
slave 其他相关配置:
1.server-id=2
和master的含义一样,服务标识
2.log-bin=mysql-bin
和master的含义一样,开启二进制
3.relay-log=relay-bin
中继日志文件的路径名称
4. relay-log-index=relay-bin.index
中继日志索引文件的路径名称
5. log_slave_updates=1
和master的含义一样,如上
6.read_only=1
1、使数据库只读,此参数在slave的复制环境和具有super权限的用户不起作用,
2、对于复制环境设置read_only=1非常有用,它可以保证slave只接受master的更新,而不接受client的更新。
3、客户端设置:
mysq> set global read_only=1
7. skip_slave_start
使slave在mysql启动时不启动复制进程,mysql起来之后使用 start slave启动,建议必须
8.replicate-do-db
只复制指定db
9.replicate-do-table
只复制指定表
10. replicate-ingore-table
忽略指定表
11. replicate_wild_do_table=skatedb.%
模糊匹配复制指定db
12. auto_increment_increment=2
auto_increment_offset=1
和master含义一样,参考如上
13. log_slow_slave_statements
在slave上开启慢查询日志,在query的时间大于long_query_time时,记录在慢查询日志里
14. max_relay_log_size
slave上的relay log的大小,默认是1G
15.relay_log_info_file
中继日志状态信息文件的路径名称
16. relay_log_purge
当relay log不被需要时就删除,默认是on
SET GLOBAL relay_log_purge=1
17.replicate-rewrite-db=from_name->to_name
数据库的重定向,可以把分库汇总到主库便于统计分析
注意:如果要同步指定库或者忽略指定库(这种需求很常见),可以有如下方法:
-
在主库上指定主库二进制日志记录的库或忽略的库:
vim /etc/my.cnf ... binlog-do-db=xxxx 二进制日志记录的数据库 binlog-ignore-db=xxxx 二进制日志中忽略数据库 以上任意指定其中一行参数就行,如果需要忽略多个库,则添加多行 ...<br>重启mysql -
在从库上指定复制哪些库或者不负责哪些库
#编辑my.cnf,在mysqld字段添加如下内容: replicate-do-db 设定需要复制的数据库 replicate-ignore-db 设定需要忽略的复制数据库 replicate-do-table 设定需要复制的表 replicate-ignore-table 设定需要忽略的复制表 replicate-wild-do-table 同replication-do-table功能一样,但是可以通配符 replicate-wild-ignore-table 同replication-ignore-table功能一样,但是可以加通配符 #修改后重启mysql
5.4 配置同步
利用客户端开发工具打开从库,主库,命令按照我下面写的位置在主从库按照序号顺序执行。
master:
1 查看主库状态,记下如下参数
SHOW MASTER STATUS;

slave:
2 执行同步sql
CHANGE MASTER TO MASTER_HOST='116.85.15.***',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=156,MASTER_PORT=3308;
参数解释:
master_host:主数据库IP
master_user:主数据库所设置的远程连接用户名
master_password:主数据库所设置的远程连接密码
master_log_file=‘master-bin.000001’:所生成的二进制日志文件,在上一张图片中有显示)
master_log_pos=13608:二进制日志文件的端口号(上张图片有显示)
Master_Port=3308 这个是主数据库端口号,不指定的话默认3306
3 开启从库同步
START SLAVE;
4 检查同步状态
SHOW SLAVE STATUS;
 忘了说了 在上述操作之前,保证两个库的数据一致。
忘了说了 在上述操作之前,保证两个库的数据一致。
如果后续主从数据库出现不一致,一般情况下可以采用如下步骤进行同步(按照序号在主从库执行):
master:
1 锁库
FLUSH TABLES WITH READ LOCK;
2 备份数据库
3 首先查看写库操作 记录下来log和行数
SHOW MASTER STATUS;
9 解锁库
UNLOCK TABLES;
slave:
查看读库确实不同步
SHOW SLAVE STATUS;
4 停止读库
STOP SLAVE;
5 导入sql脚本
6 设置从库同步
CHANGE MASTER TO MASTER_HOST='116.85.15.***',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=156,MASTER_PORT=3308;
7 开启读库
START SLAVE;
8 重新查看状态
SHOW SLAVE STATUS;
就此读写分离和主从复制配置完毕
6 结论
- 数据的同步在mysql层面实现的,mycat不负责任何的数据库同步;
- 读写分离往往还伴随着高可用,同样mycat也支持mysql的高可用,能够自动的进行master的切换。
如果是schema.xml是上述配置,停掉主库就会出现读写都无法进行,如下:

查看日志报错如下:
 如果将3309读库也配置成写库,如下:
如果将3309读库也配置成写库,如下:
 这样就会出现如下情况:
这样就会出现如下情况:
如果停掉3309,就只能写入操作,停掉3308 读写不受影响。
如果将3308,3309配置成互为主从,配置如下:
 这样无论是停掉哪个库都不会影响读写。
这样无论是停掉哪个库都不会影响读写。
建议是:如果真的生产环境的话,最起码双主双从。
见我下一篇文章。
- 当配置完Mycat的读写分离以后,从mycat的连接客户端窗口就可以知道查询走从库,增删改走主库。


















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











