







事物
事务:表示的是一组动作,这组动作要么全部执行,要么全部不执行
redis关于事物操作的几组命令:开启事务:multi 执行事物:exec 放弃事物:discard
Redis事务的实现需要用到 MULTI 和 EXEC 两个命令,事务开始的时候先向Redis服务器发送 MULTI 命令,然后依次发送需要在本次事务中处理的命令,最后再发送 EXEC 命令表示事务命令结束。
举个例子,使用redis-cli连接redis,然后在命令行工具中输入如下命令:
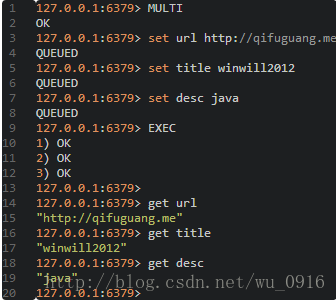
从输出中可以看到,当输入MULTI命令后,服务器返回OK表示事务开始成功,然后依次输入需要在本次事务中执行的所有命令,每次输入一个命令服务器并不会马上执行,而是返回”QUEUED”,这表示命令已经被服务器接受并且暂时保存起来,最后输入EXEC命令后,本次事务中的所有命令才会被依次执行,可以看到最后服务器一次性返回了三个OK,这里返回的结果与发送的命令是按顺序一一对应的,这说明这次事务中的命令全都执行成功了。
再举个例子,在命令行工具中输入如下命令:
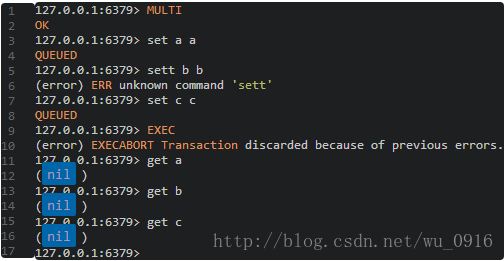
和前面的例子一样,先输入MULTI最后输入EXEC表示中间的命令属于一个事务,不同的是中间输入的命令有一个错误(set写成了sett),这样因为有一个错误的命令导致事务中的其他命令都不执行了(通过后续的get命令可以验证),可见事务中的所有命令式同呼吸共命运的。
如果客户端在发送EXEC命令之前断线了,则服务器会清空事务队列,事务中的所有命令都不会被执行。而一旦客户端发送了EXEC命令之后,事务中的所有命令都会被执行,即使此后客户端断线也没关系,因为服务器已经保存了事务中的所有命令。
除了保证事务中的所有命令要么全执行要么全不执行外,Redis的事务还能保证一个事务中的命令依次执行而不会被其他命令插入。试想一个客户端A需要执行几条命令,同时客户端B发送了几条命令,如果不使用事务,则客户端B的命令有可能会插入到客户端A的几条命令中,如果想避免这种情况发生,也可以使用事务。
Redis事务错误处理
如果一个事务中的某个命令执行出错,Redis会怎样处理呢?要回答这个问题,首先要搞清楚是什么原因导致命令执行出错:
语法错误 就像上面的例子一样,语法错误表示命令不存在或者参数错误
这种情况需要区分Redis的版本,Redis 2.6.5之前的版本会忽略错误的命令,执行其他正确的命令,2.6.5之后的版本会忽略这个事务中的所有命令,都不执行,就比如上面的例子(使用的Redis版本是2.8的)
运行错误 运行错误表示命令在执行过程中出现错误,比如用GET命令获取一个散列表类型的键值。
这种错误在命令执行之前Redis是无法发现的,所以在事务里这样的命令会被Redis接受并执行。如果食物里有一条命令执行错误,其他命令依旧会执行(包括出错之后的命令)。比如下例:
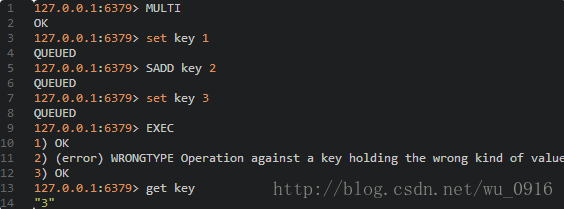
Redis中的事务并没有关系型数据库中的事务回滚(rollback)功能,因此使用者必须自己收拾剩下的烂摊子。不过由于Redis不支持事务回滚功能,这也使得Redis的事务简洁快速。
回顾上面两种类型的错误,语法错误完全可以在开发的时候发现并作出处理,另外如果能很好地规划Redis数据的键的使用,也是不会出现命令和键不匹配的问题的。
监控
监控:对某个key进行监控,常用指令:监控某个key:whatch key 取消监控:unwatch
悲观锁:顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。—–个人总结:每次操作都将所有的数据加锁(并发性差,一致性极好,备份时一般用悲观锁)。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。—-在表加个版本号字段,如果后面修改提交的版本和当前版本不一致就会报错(有点类似svn的机制,而且常用乐观锁)
redis事物举例:以以支付宝的花呗为例, 支付宝的花呗总额,可用余额balance,欠马云的钱debt(balance+debt=花呗总额);
假设花呗总额为1000
set balance 1000
set debt 0
watch balance 先监控
multi 开启事物
decryby balance 200
incryby debt 200
当开启监控后操作key,如果其他人也在操作key就会执行失败
声明
redis事物部分来源(当中的图片也是我截取它的,主要觉得复制的不好看):http://qifuguang.me/2015/09/30/Redis事务介绍/
乐观锁和悲观锁的介绍来 源:http://blog.csdn.net/hongchangfirst/article/details/26004335















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









