







我们将在iris数据集上使用hclust()进行系谱聚类。
我们首先从iris数据集中抽取含有40条记录的一个样本呢,避免绘制聚类图像时太过拥挤,我们先从数据集中中剔除Species属性,然后在该样本上进行层次聚类。代码如下:
> idx <- sample(1:dim(iris)[1],40)
> irisSample <- iris[idx,]
> irisSample$Species <- NULL
> hc <- hclust(dist(irisSample),method="complete")
> plot(hc, hang=-1, labels=iris$Species[idx])
> rect.hclust(hc,k=3)
>groups <- cutree(hc, k=3)
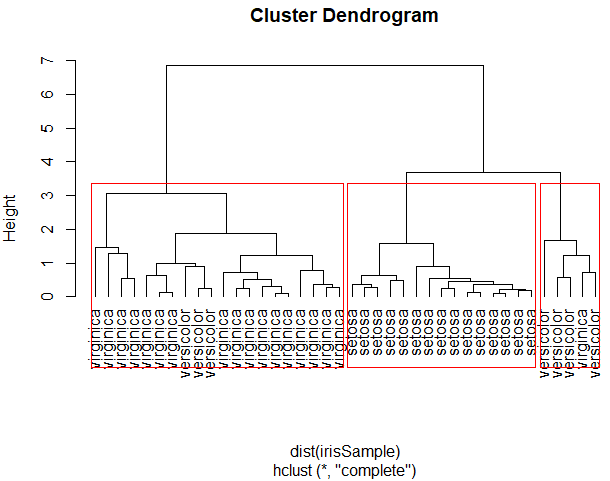
在hclust()函数中,method参数用于选择聚类的具体算法,可供选择的有ward、single及complete等7种,默认选择complete方法。从绘制的树状图中可以看出,"setaosa"与其他两个簇的划分比较明确,而"versicolor"和"virginica"存在小范围的重叠。















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









