






1.平方损失函数VS交叉熵损失函数
1.1平方损失函数(Mean Squared Error,MSE)
1.1.1什么是平方损失函数
回归问题中常用的损失函数,在线性回归中,可以通过极大似然估计(MLE)推导。计算的是预测值与真实值之间距离的平方和。实际更常用的是均方误差(Mean Squared Error-MSE):
1.1.2为什么平方损失函数适用于回归
平方损失函数适用于回归问题,因为回归问题中需要预测连续的数值型变量,平方损失函数对于大偏差会有较大的惩罚,可以有效地反映出预测值与真实值之间的差距。
1.1.3为什么平方损失函数不适用于分类
平方损失函数不适用于分类问题,因为分类问题中目标变量是离散的,使用平方损失函数会导致训练过程不收敛或者结果不准确。
1.2交叉熵损失函数(Cross Entropy Loss)
1.2.1什么是交叉熵损失函数
交叉熵损失函数是用来衡量两个概率分布之间差异性的函数,它在分类问题中常被用作损失函数。交叉熵损失函数可以衡量预测概率分布与真实概率分布之间的差距。
1.2.2为什么交叉熵损失函数适用于分类
交叉熵损失函数适用于分类问题,特别是在多分类问题中表现良好。它能够有效地反映出分类预测的准确性,并且对于预测结果的自信度也有较好的度量。
1.2.3为什么交叉熵损失函数不适用于回归
交叉熵损失函数适用于分类问题,特别是在多分类问题中表现良好。它能够有效地反映出分类预测的准确性,并且对于预测结果的自信度也有较好的度量。
2.精准率、召回率、F1值、宏平均、微平均
2.1精确率
衡量的是预测为正例的样本中实际为正例的比例,即真正例/(真正例 + 假正例)。
2.2召回率
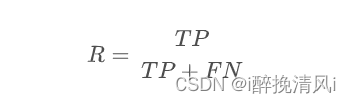
含义:实际为正例的样本有多少被预测为正;
2.3F值
F1值是精确率和召回率的调和平均,它综合考虑了精确率和召回率,F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。
2.4宏平均
F1值是精确率和召回率的调和平均,它综合考虑了精确率和召回率,F1 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。
2.5微平均
将所有类别的预测结果合并后计算指标,适用于类别样本数目差别较大的情况下,相当于把所有样本看成一个整体。















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









