







论文:
END-TO-END ASR: FROM SUPERVISED TO SEMI-SUPERVISED LEARNING WITH MODERN ARCHITECTURES
摘要
利用伪标签(pseudo-labeling)ResNet,ConvNets,Transformers,使用CTC或者Seq2Seq损失函数,但半监督可改善整个体系结构和损耗函数中的所有模型,并弥合它们之间的许多性能差距。研究不同数量的未标记音频的效果,提出了几种评估未标记音频特性的方法,这些方法可以改善声学模型,使用更多音频训练的声学模型对外部语言模型依赖较少
引言
端到端语音识别系统比较简单,与其他领域一样,在ASR中使用自我和半监督学习,预训练的网络自行产生标签进行训练可以获得改进。我们在LIBRISPEECH上训练了一个模型,然后将该模型与语言模型结合使用以从未标记的音频生成伪标签。在没有使用外部语言模型的情况下WER为2.28%,4.88%,借助LM语言模型集束搜索,在测试集上WER达到了2.09%和4.11%
模型
ResNet 声学模型
resnets最初在计算机视觉领域引入[1],介绍了resnets在语音领域的应用,介绍resnets大致结构(几个卷积层以及skip connection),每一个卷积层后面都有ReLU,Dropout,以及LayerNorm[2],对于输入执行显著的池化(16帧---160ms)在整个网络深度上使用3个最大池化层,在CTC和Seq2Seq损耗函数之前使用了几乎完全相同的编码器体系结构,
为了更好的拟合未标记的数据,通过增加每个卷积层中的通道数来增加模型大小。
TDS Convolution 声学模型
TDS块[3],它由一个2-D卷积层和两个全连接层,以及ReLU函数,LayerNorm和他们之间的残差连接组成,
基于Transformer的声学模型
使用3层或者6层(3,3)的1-D CNN,每个卷积后跟GLU激活函数[4] ,对于只有三层来说,步幅为2,对于6层来说,间隔两层。编码器:输出80维,4 head,FFN ,Dmodel=1024,Dff=4096,共24层。36层使用Dmodel=768,dff=3072,解码器:6层,4head,dmodel=256,
语言模型
n-gram LMs, GCNN, Transformer-based LMs
伪标签的数据集和语言模型
使用wav2letter++进行语言活动检测,将音频分割成不超过36秒的块,使用[5]中的方法生成伪标签
文本数据集准备以及n-gram 语言模型训练
Decoding
解码旨在通过利用声学模型(AM)的后代和语言模型(LM)的困惑来选择最佳转录。我们使用单个外部LM执行一次通过波束搜索解码。可选地,为了进一步提高性能,我们使用更强大的基于NN的LM来重刻光束。
Beam-searcb Decoder
解码器从声学模型,建立在词典上的前缀Trie和外部LM作为后验输入。我们在验证集(dev-clean和dev-other)上调整语言模型权重α和单词插入罚分β。解码器输出最大的转录transcription y:
![]()
为了稳定Seq2Seq波束搜索,我们将EOS罚分γ引入以句子结尾标记完成的假设。 γ与其他超参数一起被调谐,我们的实验表明,这种策略有效地防止了解码器过早停止。为了提高解码效率,我们还结合了[6]中的阈值技术和[7]中提到的策略,包括假设合并,评分缓存和批量LM转发。对于之后的CTC解码,如果空白令牌的后验概率大于0.95,则仅考虑空白令牌。
重打分
从单程波束搜索解码器获取N个最佳假设的转录后,我们使用外部字级GCNN LM和Transformer LM来评估它们的对数概率,分别表示为logP1(y)和logP2( ˆ y)。然后,我们根据以下得分进行重新排序以对假设进行重新排序:
![]()
实验
声学模型训练
具有动量的普通SGD用于训练ResNet和TDS模型,而Adagrad [8]用于Transformer,在64个GPU上对模型进行训练,ResNet 和TDS batchsize为256,transformer为320
ResNet学习率在[0.05,0.5]中选择
TDS和Transformer模型的初始学习率则在[0.01,0.03]之间,特别的,对于Transformer使用32k或者64k 步的线性学习率预热时间表(Specifically, for Transformers, we apply a linear learning rate warm-up schedule for either 32k or 64k updates)
学习率衰减:Transformer 90epochs ResNet 和TDS模型 150epochs
所有层使用0.2的dropout,
所有模型都使用SpecAugment
语言模型
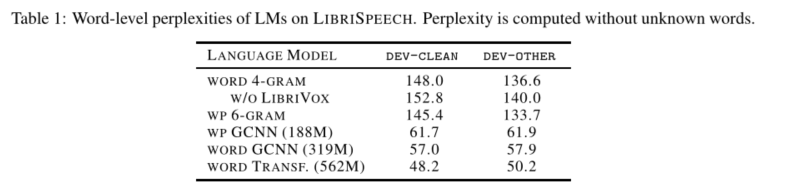
n-gram LM使用KenLM工具包进行训练,而GCNN和Transformer LM使用fairseq工具包进行训练。单词级4元gram和GCNN的训练方法与[32]相同。我们还训练了一个6gram单词的LM,其上下文大小与单词级4 gram LM相似,并且修剪了5 gram出现一次,出现6 gram出现两次或更少。单词块和单词级GCNN模型在8个GPU上使用Nesterov加速梯度下降[35]在22个时期进行训练,逐步学习率调度从1开始,当损失稳定时降低5倍。以下[12]使用梯度削波和权重归一化。单词级Transformer LM在128个GPU上进行Nesterov加速梯度下降训练,历时100个历元,平方根成反比。在前16000次迭代中,使用了将学习率从0线性增加到1的预热时间表。表1列出了所有LM变体的词级困惑。
结果
LiBRISPEECH:最好的声学模型是基于Transformers的,在未进行其他测试的情况下进行解码时达到6.98%,在进行解码和记录后达到5.17%,这表明端到端训练可以像传统的自举系统一样执行。
LIBRIVOX:在此组合数据集上对同时具有CTC和Seq2Seq损耗的变压器AM进行了为期5天的训练,无需解码或使用LM即可在测试清洁度上获得WER(其他为4.88%和2.28%),甚至在使用LM的管道中也是如此。解码/记录的结果显示在表2中,其中我们在清洗测试和其他测试上分别达到2.09%和4.11%,并且是对最新技术的进一步改进

改变未标记音频的数量。在这项研究中,我们对第3节中所述的原始集合中的伪标签的几个不同的随机选择子集进行了训练,结果在表3中给出。增加伪标签的数量严格提高了性能。列出的53.8k小时的结果使用的是第3.1节中概述的充分准备的数据集。经过80万次训练迭代后,给出的WER不会解码。
产生伪标签使用重叠文本的LM模型
训练只有伪标签的数据
无语言模型的端到端声学模型
带有足够的未标记音频,使用LM解码不会提高性能
我们展示了不需要很多培训步骤的简单管道的有效性。鉴于我们没有解码或LM的半监督结果,我们认为Seq2Seq / CTC损耗,传感器和微分解码是在没有外部LM的情况下通过以下方法获得端到端最新结果的可行方法半监督学习。
在具有HMM的ASR中重新引入了深层神经网络[24],许多最新模型仍然依赖于力对齐[18、33、28]。尽管如此,使用CTC [15,1],ASG [8,54],LF-MMI [17],序列对序列[4,5],转导[41]训练的端到端结果竞争越来越激烈,22]和微分解码[9]。 Listen Attend and Spell [4]是一个基于biLSTM的端到端模型系列,通过数据增强提高了正则化效果,从而获得了最新技术成果[38];因此,我们在所有实验中都使用SpecAugment。 Seq2Seq模型不限于RNN;时间深度可分离卷积也给出了很强的结果[20]。
参考文献
- He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Computer Vision and Pattern Recognition (CVPR), 2016
- Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Hannun, A., Lee, A., Xu, Q., and Collobert, R. Sequence-to-sequence speech recognition with time-depth separable convolutions. Interspeech 2019, Sep 2019. doi: 10.21437/interspeech.2019-2460.
- Dauphin, Y . N., Fan, A., Auli, M., and Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning - V olume 70, ICML’17, pp. 933–941.JMLR.org, 2017.
- Kahn, J., Lee, A., and Hannun, A. Self-training for end-to-end speech recognition. arXiv preprint arXiv:1909.09116, 2019.
- Hannun, A., Lee, A., Xu, Q., and Collobert, R. Sequence-to-sequence speech recognition with time-depth separable convolutions. Interspeech 2019, Sep 2019. doi: 10.21437/interspeech.2019-2460
- Zeghidour, N., Xu, Q., Liptchinsky, V ., Usunier, N., et al. Fully convolutional speech recognition. CoRR, abs/1812.06864, 2018. URL https://arxiv.org/abs/1812.06864.
- Duchi, J., Hazan, E., and Singer, Y . Adaptive subgradient methods for online learning and stochastic optimization.Journal of machine learning research, 12(Jul):2121–2159, 2011
















 2936
2936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









