







python中str类

str(object) returns object.__str__()
Python中原始字符串(r'str')问题

python中unicode与GB
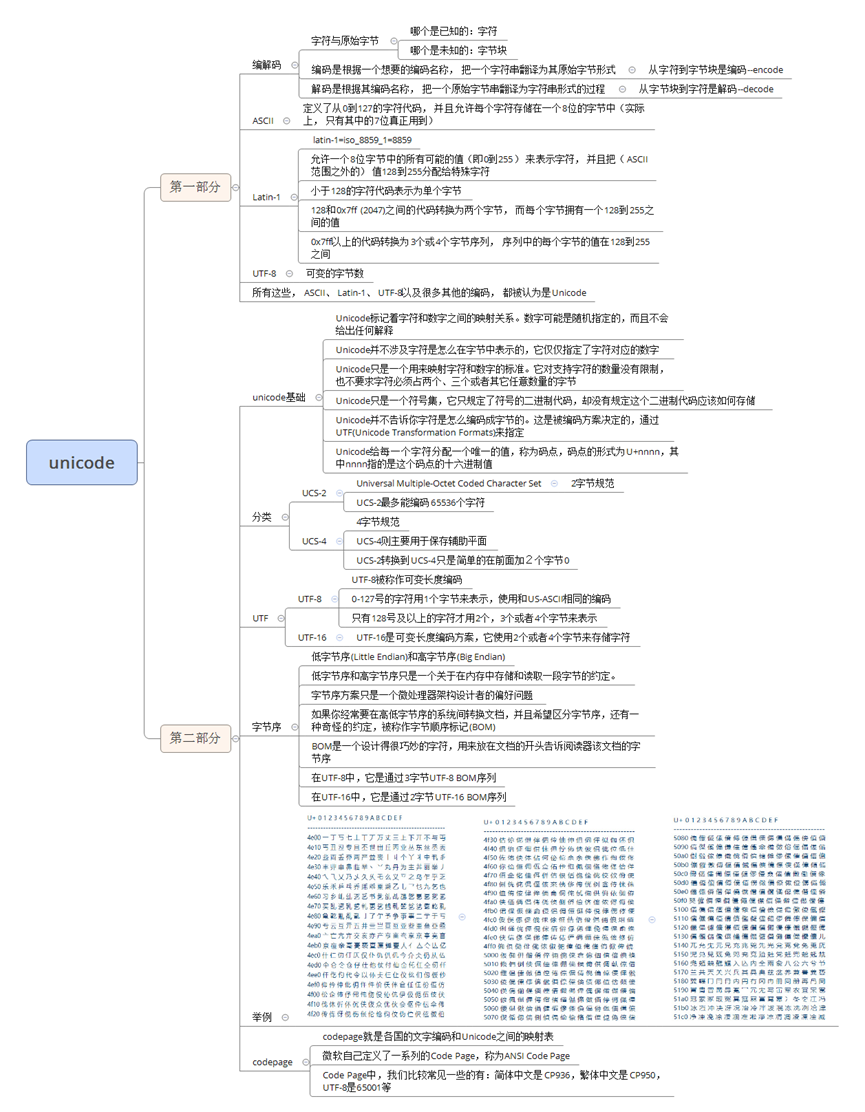
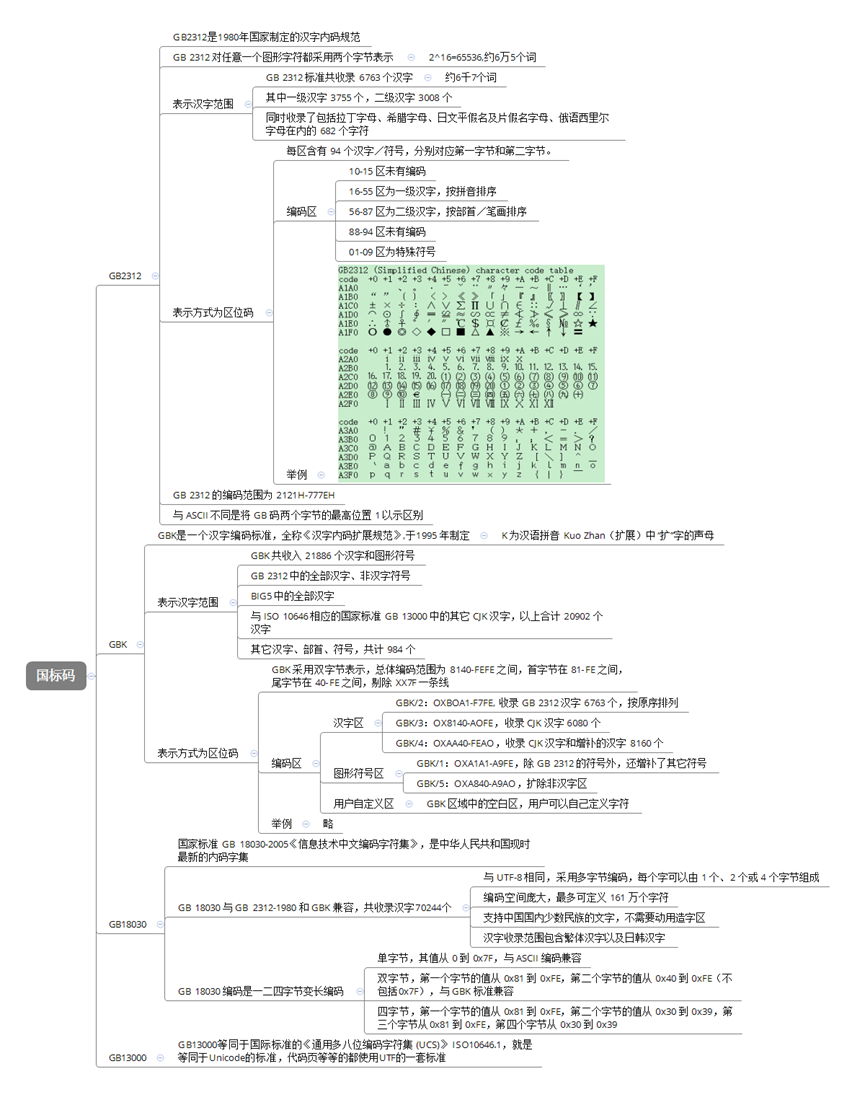
Python中的字符集问题
Python字符串类型
Python 2.X:
str表示8位文本和二进制数据
unicode用来表示宽字符Unicode文本
Python 3.X:
str表示Unicode文本(8位的和更宽的)
bytes表示二进制数据(不可修改)
bytearray,是一种可变的bytes类型(可修改)
在Python2.6中, 我们可以对简单的文本使用str并且对文本的更高级的形式使用二进制数据和unicode
在Python 3.0中, 我们将针对任何类型的文本(简单的和Unicode)使用str,并且针对二进制数据使用bytes或bytearray


重要:
python3中,字符串的编码使用str和bytes两种类型:
str字符串:使用unicode编码
bytes字符串:使用将unicode转化成的某种类型的编码,如utf-8,gbk
python3.x中字符创建方式
str对象:str()或’xxx’,”xxx”或三引号字符块
bytes对象:bytes()或b加在’xxx’,”xxx”或三引号字符块前面
bytearray对象:bytearray()函数来创建
python3.x中字符类型之间转换
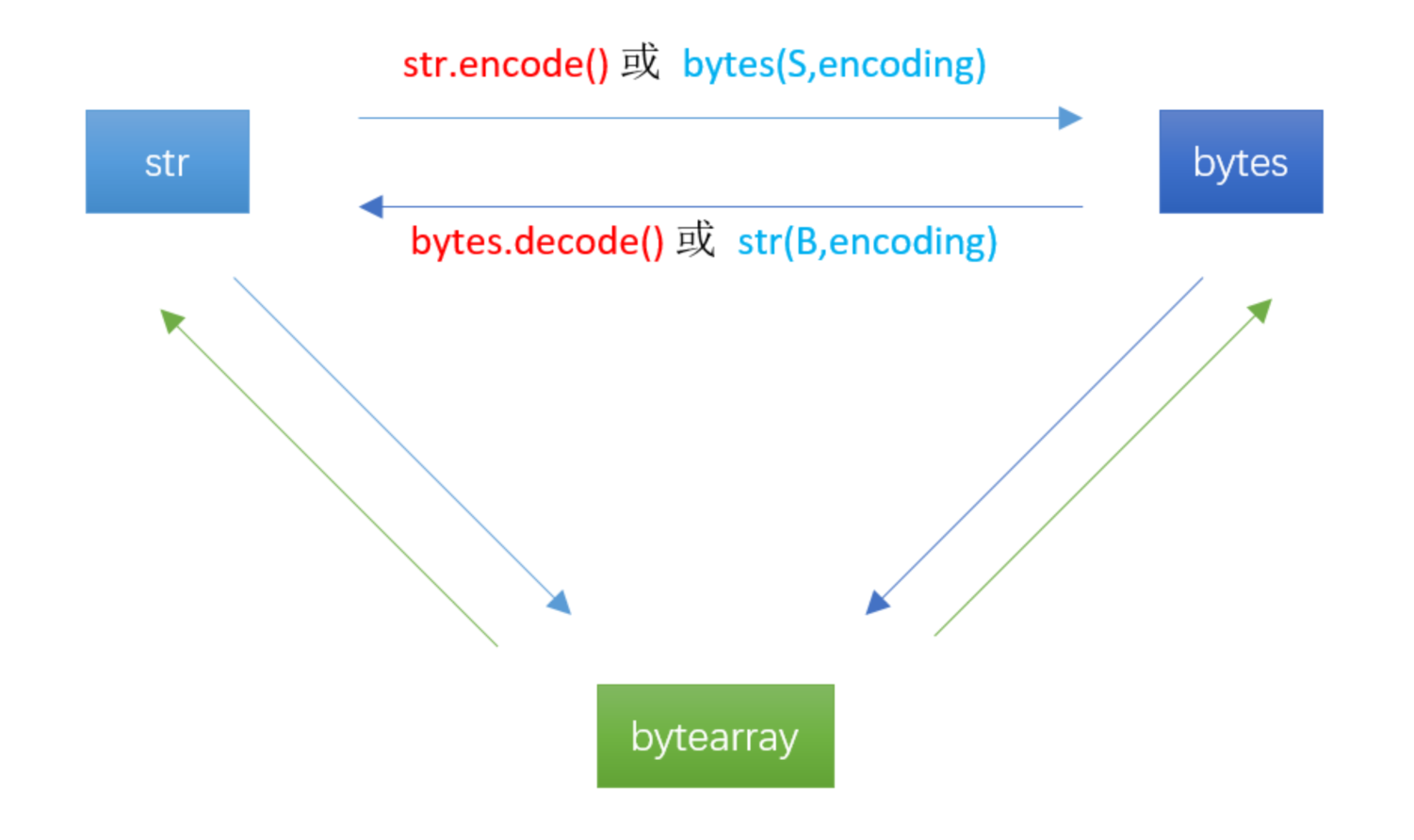
上述str.encode()和bytes.decode()函数没有输入参数
python3.X中字符编码方式之间的转换
字符串转换为不同的编码:
用方法调用手动地转换
在文件输入输出上自动地转换
手动编码:U = S.encode('utf-8')
文件输出编码:open('utf8data','w', encoding='utf-8').write(S)
文件输入编码:open('utf8data','r', encoding='utf-8').read()或X = open('utf8data', 'rb').read();X.decode('utf-8')
X是文件对象(file object)
将list中的中文显示为出来
print('listnine list: %s' % str(listnine_list).decode('string_escape'))
import json
result = json.dumps(r_list, encoding='UTF-8', ensure_ascii=False)
print(result)chardet
import chardet
f = open('file','r')
fencoding=chardet.detect(f.read())
print(fencoding)Python中的字符串操作方法
字符串方法调用

isdecimal()
True: Unicode数字,全角数字(双字节)
False: 罗马数字,汉字数字
Error: byte数字(单字节)
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字
False: 汉字数字
Error: 无
isnumeric()
True: Unicode数字,全角数字(双字节),罗马数字,汉字数字
False: 无
Error: byte数字(单字节)
str.startswith(prefix[, start[, end]])
str.endswith(suffix[, start[, end]])
S.partition()与S.split()的区别
str.partition(sep):
Split the string at the firstoccurrence of sep, and return a 3-tuplecontaining the part before the separator, the separator itself, and the part
after the separator
返回第一个sep分割出的一个三元组(前部,sep,后部)
str.split(sep=None, maxsplit=-1):
Return a list ofthe words in the string, using sep as the delimiterstring
如果不指定maxsplit,则返回所有sep作为分割符的分割部分的list(即可能被分割为了多个部分,且不包含sep)


strip删除空白字符




Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。
语法:
str.zfill(width)
参数:
width -- 指定字符串的长度。原字符串右对齐,前面填充0。
返回值:
返回指定长度的字符串。
python中字符串之间的连接
方法1:直接通过加号(+)操作符连接
website = 'python' + 'tab' + '.com'
方法2:join方法
listStr = ['python', 'tab', '.com']
website = ''.join(listStr)
方法3:%占位符
website ='%s%s%s' % ('python', 'tab', '.com')
格式化操作符(%-formatting)
'%d%d' % (val1, val2)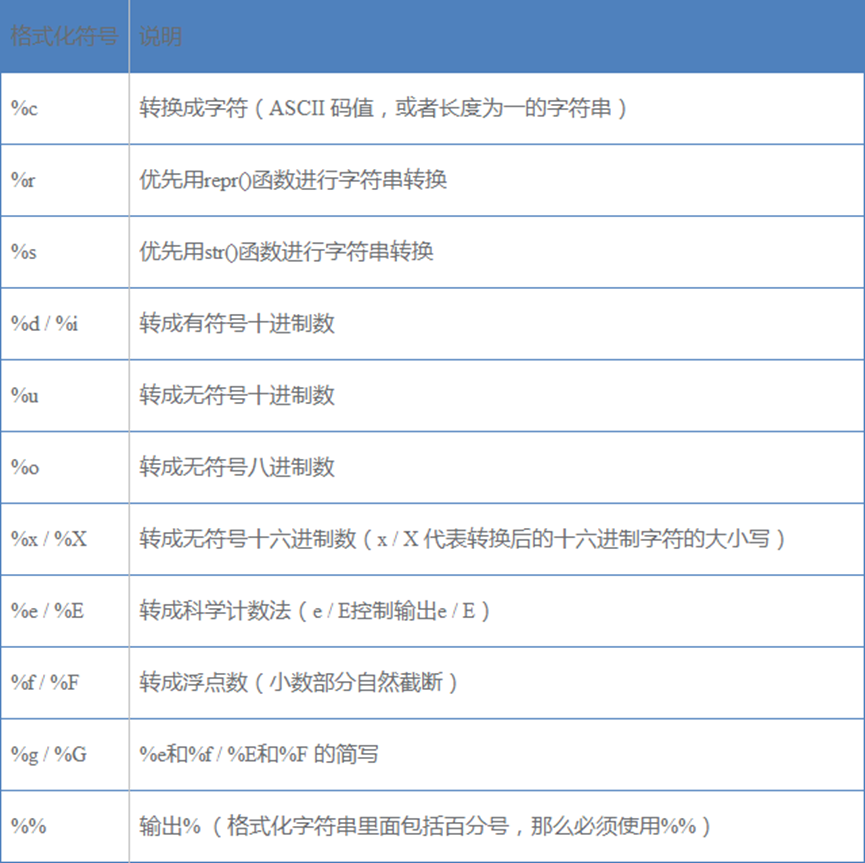

字符串内建函数(str.format())

example1
age = 25
name = 'Caroline'
print('{0} is {1} years old. '.format(name, age)) #输出参数
print('{0} is a girl. '.format(name))
print('{0:.3} is a decimal. '.format(1/3)) #小数点后三位
print('{0:_^11} is a 11 length. '.format(name)) #使用_补齐空位
print('{first} is as {second}. '.format(first=name, second='Wendy')) #别名替换
print('My name is {0.name}'.format(open('out.txt', 'w'))) #调用方法
print('My name is {0:8}.'.format('Fred')) #指定宽度example2
print("{:0>8.4f}".format(0.12345))
>>> 000.1235
语法是{}中所带:号即为格式限定符
其中0表示用0填充,默认用空格
其中>表示右对齐
其中8表示字符宽度为8,也即共占八个字符位置
其中.4表示保留小数点后4
其中f表示浮点数
字符串格式化方法(f-string)
简述
f-string是Python3.6之后出现的格式化语法
格式:f'要输出的字符串{要拼接的变量}'
f可以是大写,也可以是小写,
引号可以是单引号,也可以是双引号
精度控制
{浮点型变量:.nf} 保留n位小数,四舍五入
{整型变量:0nd} 保留n位,不足位用0补齐,如果超出则原样显示
%可以单独输出
自定义格式
自定义格式:对齐、宽度、符号、补零、精度、进制等
f-string采用{content:format} 设置字符串格式,其中 content 是替换并填入字符串的内容,可以是变量、表达式或函数等,format是格式描述符。采用默认格式时不必指定 {:format},如上面例子所示只写 {content} 即可。
基本格式类型
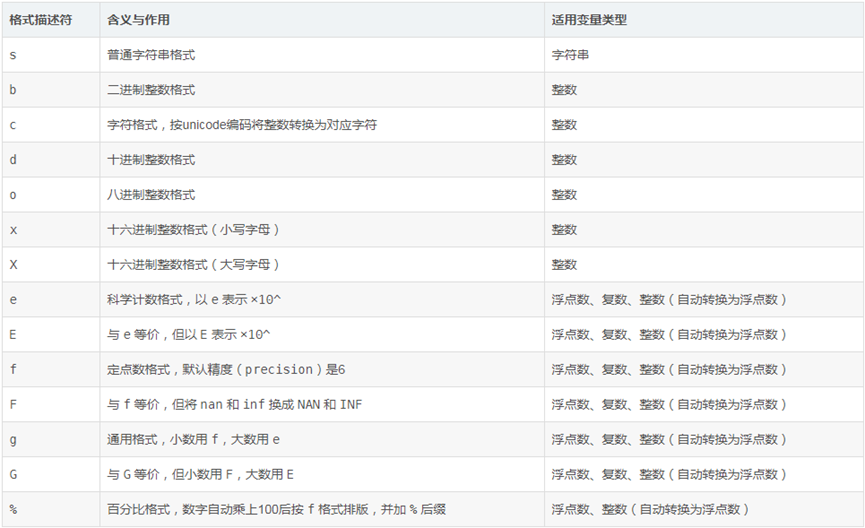
对齐相关格式描述符
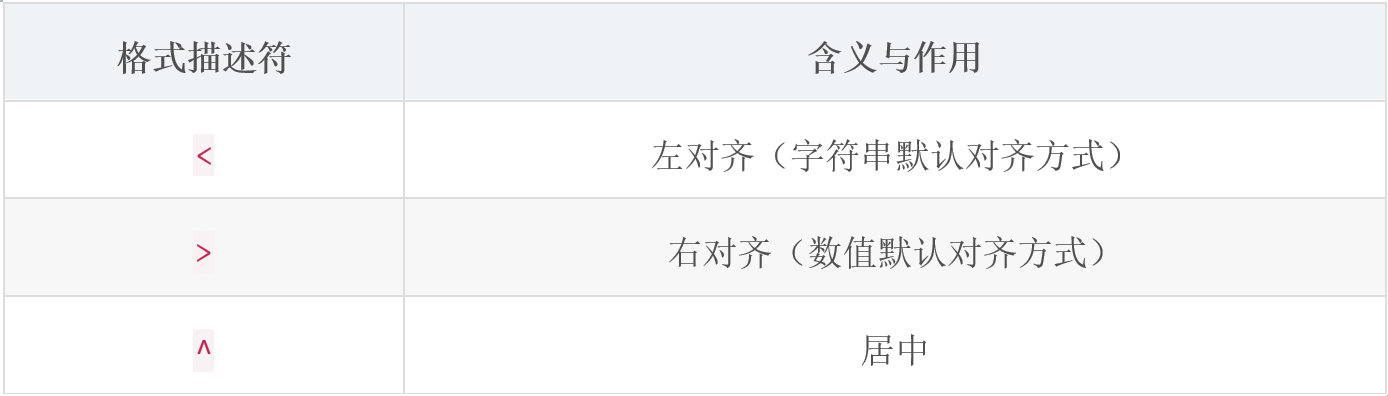
print(f'税前薪资是:{salary:<8}元, 缴税:{tax:<8}元, 税后薪资是:{aftertax:<8}元')宽度,精度,补零

注1:0width 不可用于复数类型和非数值类型,width.precision 不可用于整数类型。
注2:width.precision 用于不同格式类型的浮点数、复数时的含义也不同:用于 f、F、e、E 和 % 时 precision 指定的是小数点后的位数,用于 g 和 G 时 precision 指定的是有效数字位数(小数点前位数+小数点后位数)。
注3:width.precision 除浮点数、复数外还可用于字符串,此时 precision 含义是只使用字符串中前 precision 位字符。
>>> a = 123.456
>>> f'a is {a:8.2f}'
'a is 123.46'
>>> f'a is {a:08.2f}'
'a is 00123.46'
>>> f'a is {a:8.2e}'
'a is 1.23e+02'
>>> f'a is {a:8.2%}'
'a is 12345.60%'
>>> f'a is {a:8.2g}'
'a is 1.2e+02'
>>> s = 'hello'
>>> f's is {s:8s}'
's is hello '
>>> f's is {s:8.3s}'
's is hel '百分号
total=3
pos=1
perc=pos/total
print(f"{perc:%}")
print(f"{perc:.2%}")
print(f"{perc:.3%}")
##33.333333%
##33.33%
##33.333%千位分隔符
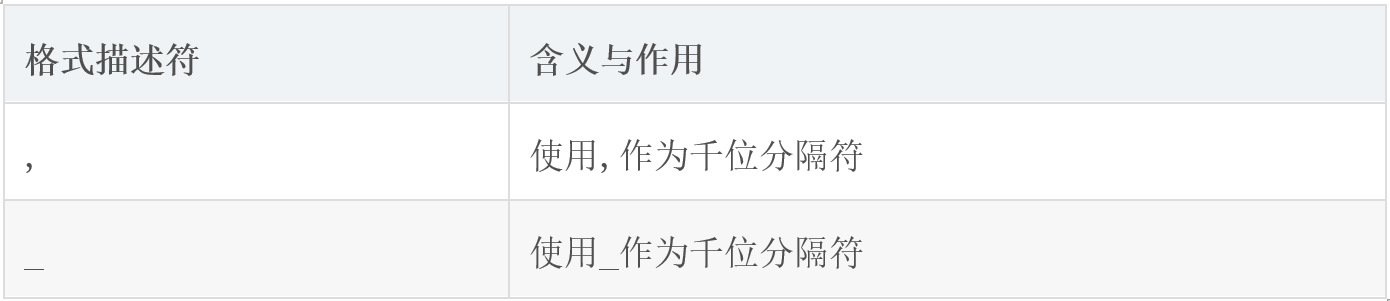
注1:若不指定 , 或 _,则f-string不使用任何千位分隔符,此为默认设置。
注2:, 仅适用于浮点数、复数与十进制整数:对于浮点数和复数,, 只分隔小数点前的数位。
注3:_ 适用于浮点数、复数与二、八、十、十六进制整数:对于浮点数和复数,_ 只分隔小数点前的数位;对于二、八、十六进制整数,固定从低位到高位每隔四位插入一个 _(十进制整数是每隔三位插入一个 _)。
>> > a = 1234567890.098765
>> > f'a is {a:f}'
'a is 1234567890.098765'
>> > f'a is {a:,f}'
'a is 1,234,567,890.098765'
>> > f'a is {a:_f}'
'a is 1_234_567_890.098765'
>> > b = 1234567890
>> > f'b is {b:_b}'
'b is 100_1001_1001_0110_0000_0010_1101_0010'
>> > f'b is {b:_o}'
'b is 111_4540_1322'
>> > f'b is {b:_d}'
'b is 1_234_567_890'
>> > f'b is {b:_x}'
'b is 4996_02d2'简单示例
>>> name = 'Fred'
>>> age = 42
>>> f'He said his name is {name} and he is {age} years old.'
He said his name is Fred and he is 42 years old.>>> name = 'Fred'
>>> age = 42
>>> 'He said his name is {} and he is {} years old.'.format(name, age)
'He said his name is Fred and he is 42 years old.'字符与数字之间转换
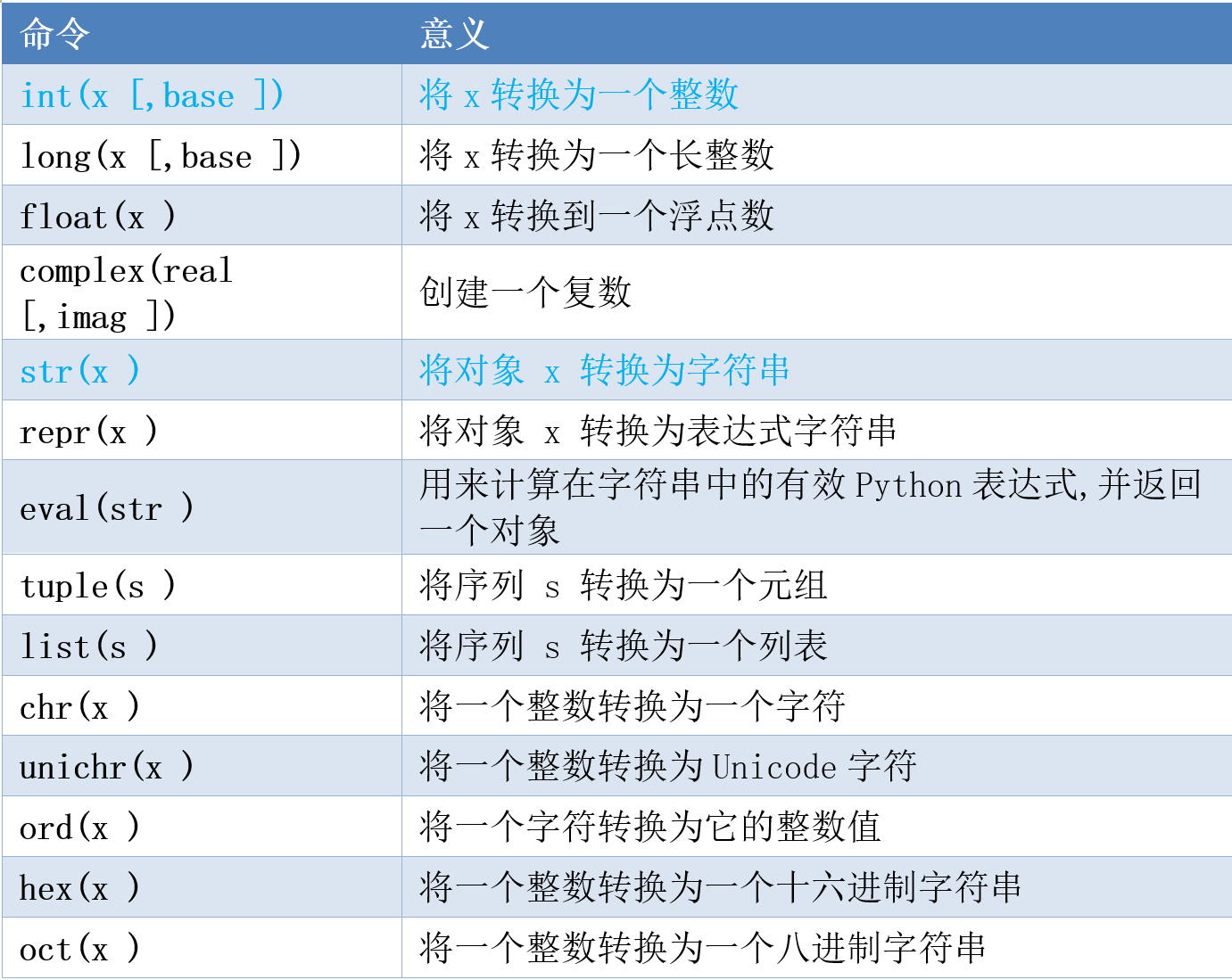
将数字转化为百分数形式
rate = .1234
print('%.2f%%' % (rate * 100))rate = .1
res = format(rate, '.0%')
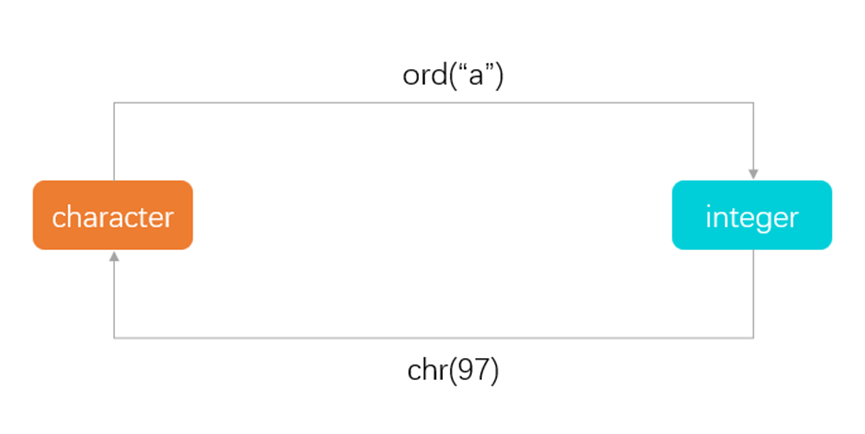
ord和chr
ord(c)是字符转ASCII码
chr(n)是ASCII码转字符
hex和int
hex():十进制数转十六进制字符串
语法:
hex(number)
Parameter(s): number-要转换为十六进制的有效数字。
返回值: str –以给定数字的字符串格式返回十六进制值。
int():字符串数字转数字类型,base决定字符串数字的进制
例如:
int("10",16)
>>> x = 12345
>>> format(x,'b')
'11000000111001'
>>> format(x,'o')
'30071'
>>> format(x,'x')
'3039'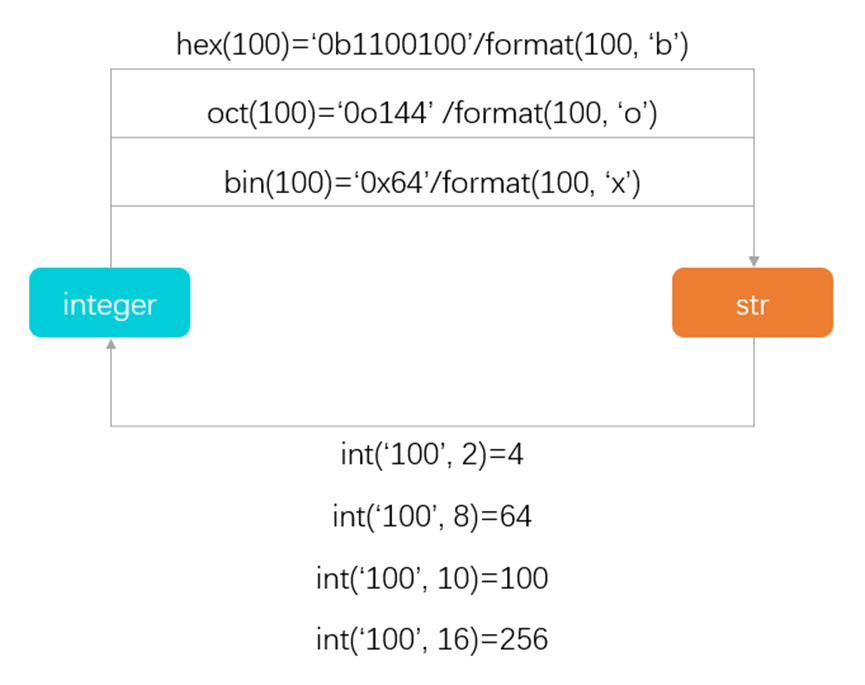
num1 = 100
# num2 = bin(num1)
num2 = format(num1, "b")
print(type(num2), num2)
# num2 = oct(num1)
num2 = format(num1, "o")
print(type(num2), num2)
# num2 = hex(num1)
num2 = format(num1, "x")
print(type(num2), num2)
print()
num2 = int("100", 2)
print(type(num2), num2)
num2 = int("100", 8)
print(type(num2), num2)
num2 = int("100", 10)
print(type(num2), num2)
num2 = int("100", 16)
print(type(num2), num2)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











