






今天分享一篇关于如何获取基金数据的一个内容,由于目前的股市不太理想,理财也没有更好的渠道,我发现这几年的债券型基金还是比较好的,做得好的话,年化收益可以达到5%,而且也比较稳定,还具备金融活期属性,不过有个问题,债券型基金有几千只,如何从这几千只中找到最好的那几只呢。
首先我们去天天基金网,打开下面这个页面,列举了所有债券型基金
 https://fund.eastmoney.com/data/fundranking.html?spm=001.2.swh#tzq;c0;r;s1nzf;pn50;ddesc;qsd20230423;qed20240423;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb
https://fund.eastmoney.com/data/fundranking.html?spm=001.2.swh#tzq;c0;r;s1nzf;pn50;ddesc;qsd20230423;qed20240423;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb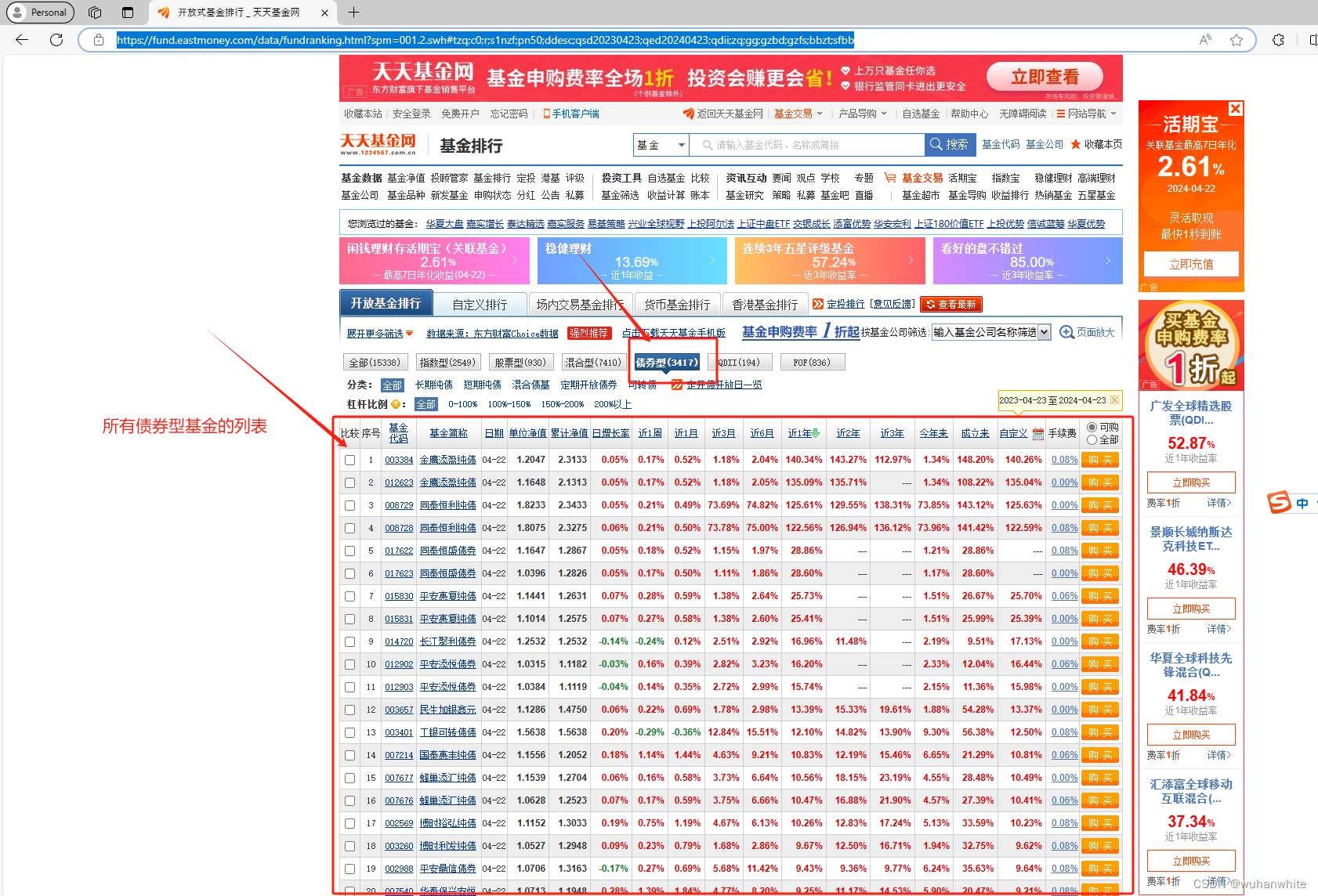
我平常关注的债基走势图发几个给兄弟姐妹朋友们看下:
可以看到这种债基的涨幅还是很好的,基本都是涨,很少跌,金融业专业术语叫回撤很小。
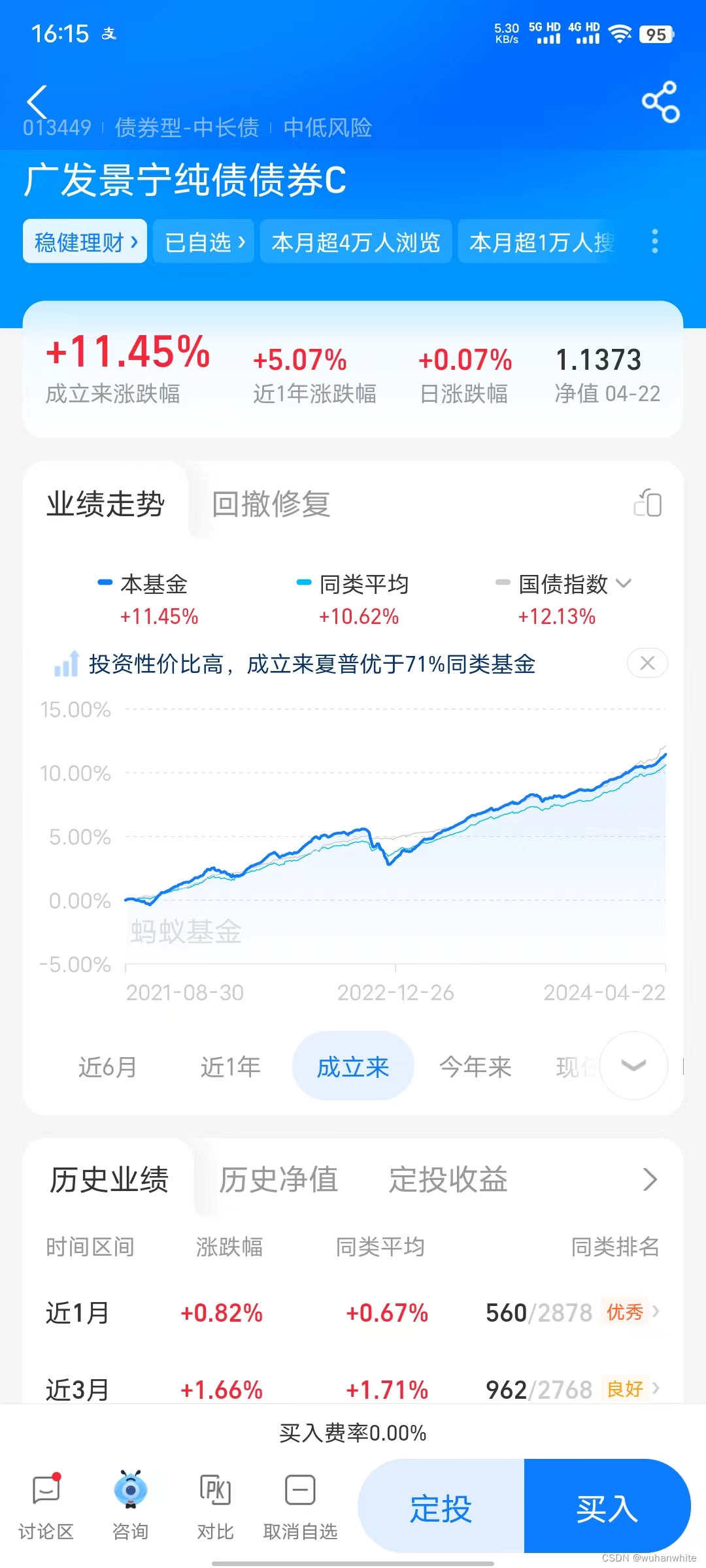
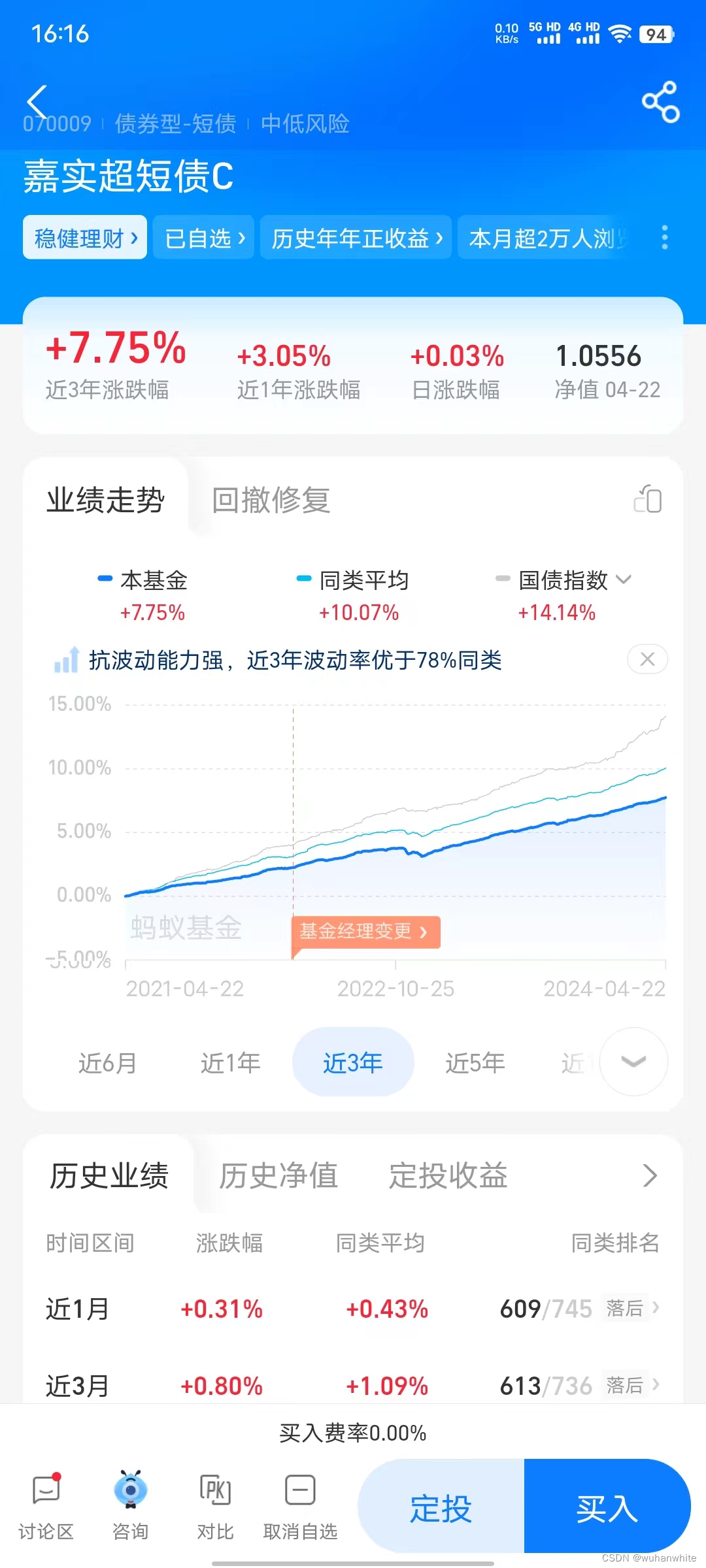
那么如何从几千只寻找到比这个更好的债基呢,
我的选债基的条件非常严格,以下几个必须条件
1,日增长率,近一周,近1月,近3月,近6月,近1年,近2年,近3年,今年来,成立来,这些数据必须要全部为正,看下图
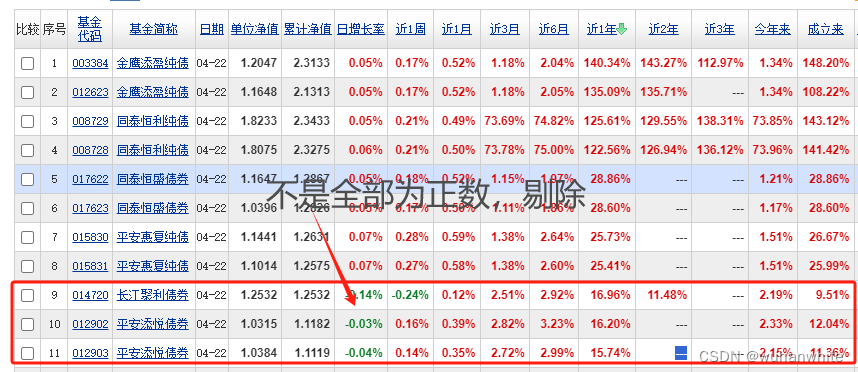
2,手续费为0
3,卖出规则是持有7天就可以卖出,相当于7天后就是活期属性了,这样即使债市发生风险,也可以很快就跑出来,不至于被套很久。
第一步,用python代码找出这些数据都为正数,并且手续费为0的基金,将这些基金存到一个表格中,代码如下:
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException, TimeoutException, StaleElementReferenceException
import time
# 初始化WebDriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.implicitly_wait(2) # 设置隐式等待时间为2秒
# 打开网页
url = "https://fund.eastmoney.com/data/fundranking.html?spm=001.2.swh#tzq;c0;r;s1nzf;pn50;ddesc;qsd20230423;qed20240423;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb"
driver.get(url)
# 设置最大翻页次数
max_pages = 70 //根据页面展示的翻页数来设置
current_page = 0
# 初始化DataFrame和数据列表
df = pd.DataFrame()
data_list = []
# 处理分页
while current_page < max_pages:
try:
# 获取当前页面上所有匹配的DOM元素
rows = driver.find_elements(By.CSS_SELECTOR, "#dbtable > tbody > tr")
for row in rows:
# 获取每个数据行的详细信息
code_name = row.find_element(By.CSS_SELECTOR, "td:nth-child(3) > a").text
daily_growth = row.find_element(By.CSS_SELECTOR, "td:nth-child(8)").text
one_week = row.find_element(By.CSS_SELECTOR, "td:nth-child(9)").text
one_month = row.find_element(By.CSS_SELECTOR, "td:nth-child(10)").text
three_months = row.find_element(By.CSS_SELECTOR, "td:nth-child(11)").text
six_months = row.find_element(By.CSS_SELECTOR, "td:nth-child(12)").text
one_year = row.find_element(By.CSS_SELECTOR, "td:nth-child(13)").text
two_years = row.find_element(By.CSS_SELECTOR, "td:nth-child(14)").text
three_years = row.find_element(By.CSS_SELECTOR, "td:nth-child(15)").text
this_year = row.find_element(By.CSS_SELECTOR, "td:nth-child(16)").text
since_inception = row.find_element(By.CSS_SELECTOR, "td:nth-child(17)").text
fee = row.find_element(By.CSS_SELECTOR, "td:nth-child(19)").text
# 检查所有百分比字段是否为正数,并且手续费为0.00%
percentages = [daily_growth, one_week, one_month, three_months, six_months, one_year, two_years, three_years, this_year, since_inception]
if all(percentage == "---" or (percentage.endswith('%') and float(percentage[:-1]) >= 0) for percentage in
percentages) and fee == "0.00%":
data_list.append({
"证券代码名称": code_name,
"日增长率": daily_growth,
"近一周": one_week,
"近1月": one_month,
"近3月": three_months,
"近6月": six_months,
"近1年": one_year,
"近2年": two_years,
"近3年": three_years,
"今年来": this_year,
"成立来": since_inception,
"手续费": fee
})
# 等待2-3秒
time.sleep(1)
# 检查是否有下一页
# 检查是否有下一页
try:
# 尝试不同的选择器来查找下一页按钮
next_button_selectors = [
"#pagebar > label:nth-child(9)",
"#pagebar > label:nth-child(11)"
]
for selector in next_button_selectors:
try:
next_button = driver.find_element(By.CSS_SELECTOR, selector)
next_button.click()
current_page += 1
break # 如果找到了并点击了按钮,就跳出循环
except NoSuchElementException:
continue # 如果没有找到,尝试下一个选择器
except NoSuchElementException:
print("No next button found, possibly on the last page.")
break
except StaleElementReferenceException:
print("StaleElementReferenceException occurred, continuing.")
continue
# 将数据列表转换为DataFrame
df = pd.DataFrame(data_list)
# 将DataFrame写入Excel文件
df.to_excel("123.xlsx", index=False)
# 关闭浏览器
driver.quit()
由于设置了一些等待,所以运行时间大概半个小时,运行完成后会生成一个123.xlsx文件,这个文件内容大致如下:
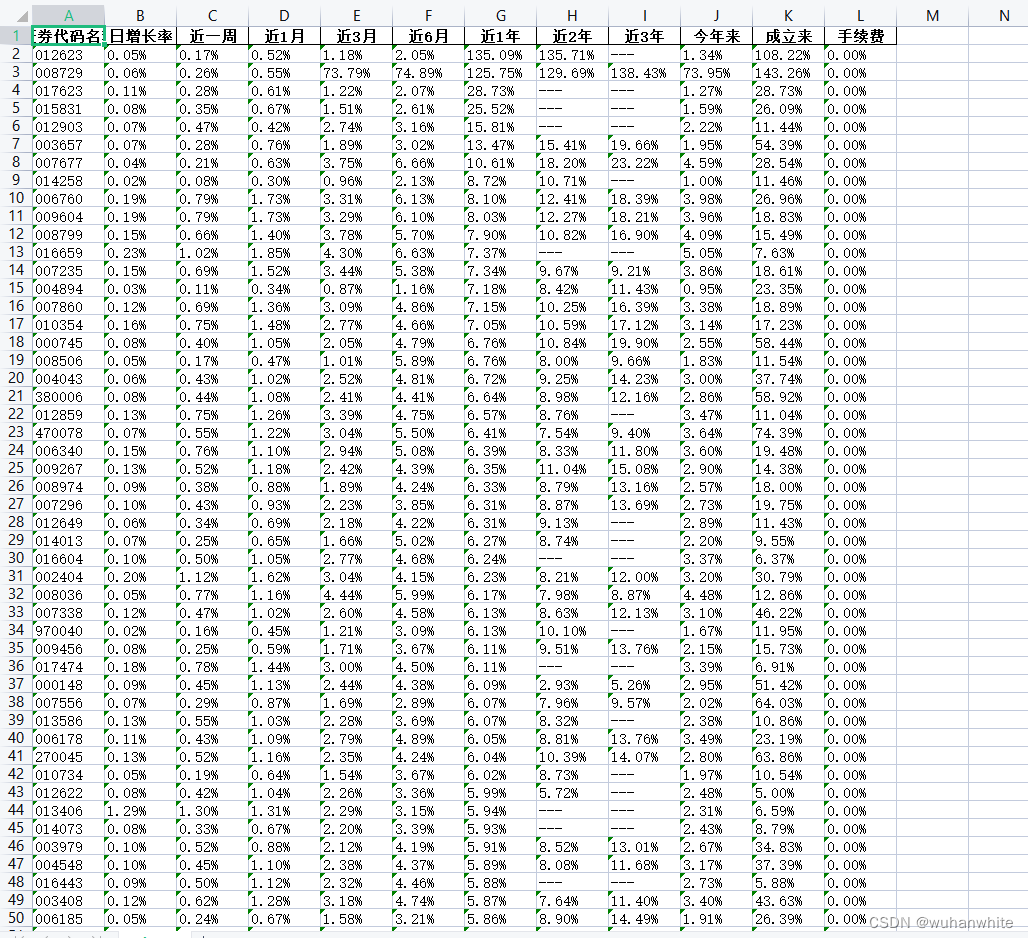
找到了1127个符合条件的基金。
第二步,从这1127个基金中找到持有7天就可以卖出的基金
一般在这个页面是可以获取基金的卖出费率的
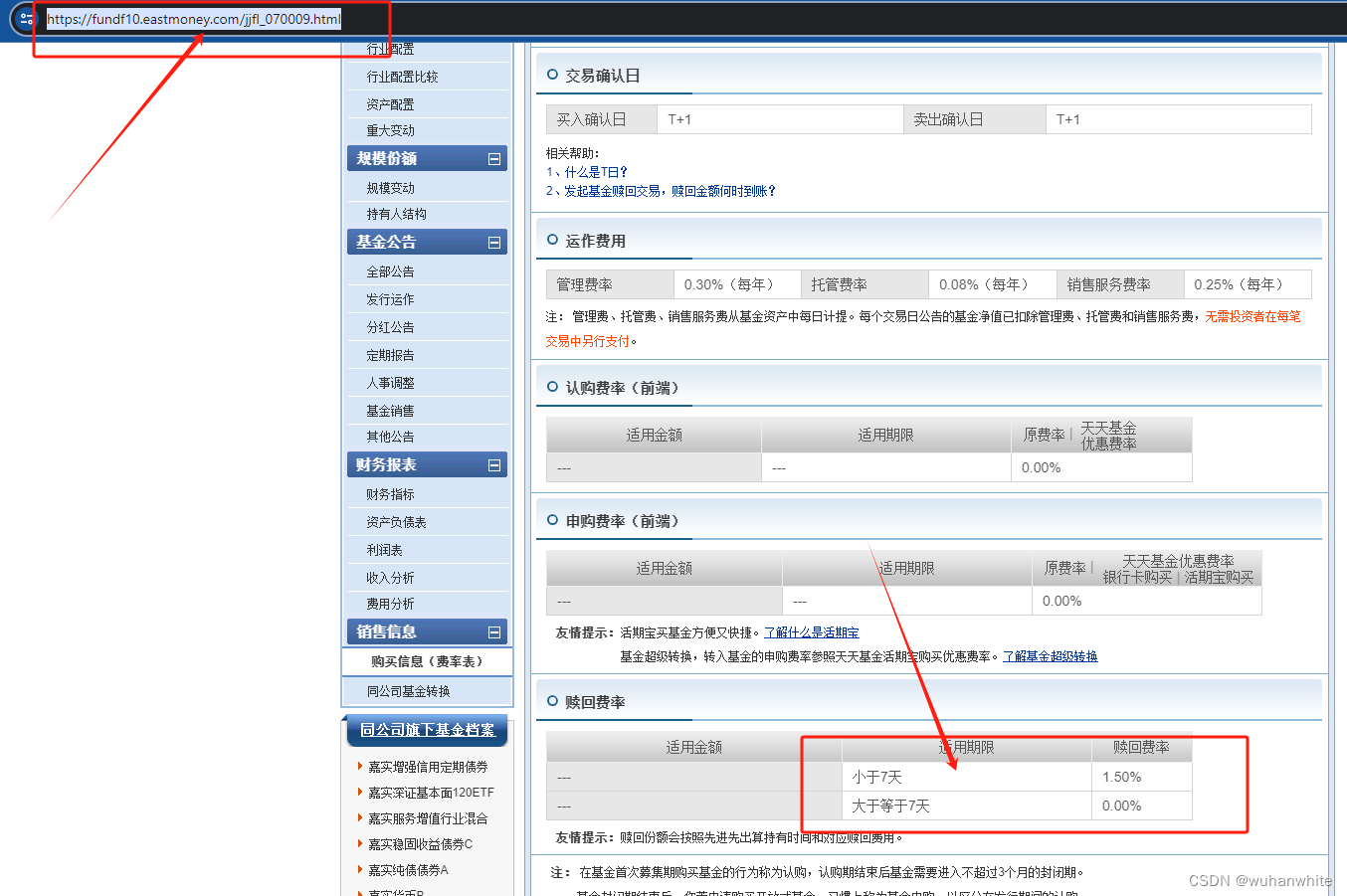
代码如下:
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException, WebDriverException, TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 初始化WebDriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# 读取Excel文件
df = pd.read_excel("123.xlsx", dtype={'证券代码名称': str})
# 确保DataFrame有足够的列来存储数据
additional_columns = ['新列1', '新列2', '新列3', '新列4']
for col in additional_columns:
if col not in df.columns:
df[col] = None
# 创建一个新的Excel文件,用于存储结果
output_file = "123_output.xlsx"
df.head(1).to_excel(output_file, index=False) # 只写入列头
# 遍历Excel文件中Sheet1的A列,从第2行开始
for index, row in df.iterrows():
if index >= 1: # 从第2行开始
code = row['证券代码名称'] # 保留原始的证券代码名称,包括前导零
url = f"https://fundf10.eastmoney.com/jjfl_{code}.html"
try:
# 打开网页
driver.get(url)
# 等待页面加载完成,最多等待10秒
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "body")))
# 获取指定的DOM元素
elements = []
selectors_1 = [
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(7) > div > table > tbody > tr:nth-child(1) > td:nth-child(2)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(7) > div > table > tbody > tr:nth-child(1) > td:nth-child(3)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(7) > div > table > tbody > tr:nth-child(2) > td:nth-child(2)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(7) > div > table > tbody > tr:nth-child(2) > td:nth-child(3)"
]
selectors_2 = [
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(6) > div > table > tbody > tr:nth-child(1) > td:nth-child(2)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(6) > div > table > tbody > tr:nth-child(1) > td:nth-child(3)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(6) > div > table > tbody > tr:nth-child(2) > td:nth-child(2)",
"#bodydiv > div:nth-child(12) > div.r_cont.right > div.detail > div.txt_cont > div > div:nth-child(6) > div > table > tbody > tr:nth-child(2) > td:nth-child(3)"
]
for selector in selectors_1:
try:
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR, selector))).text
elements.append(element)
except (NoSuchElementException, TimeoutException):
break
if len(elements) < 4:
elements = []
for selector in selectors_2:
try:
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.CSS_SELECTOR, selector))).text
elements.append(element)
except (NoSuchElementException, TimeoutException):
elements.append("N/A")
# 将提取的值写回到原Excel文件的相应行的M列
for i, element in enumerate(elements, start=df.columns.get_loc('新列1')): # 从新列1开始
df.at[index, df.columns[i]] = element
# 将当前行的数据写入Excel文件
current_row_df = df.iloc[[index]]
with pd.ExcelWriter(output_file, mode='a', engine='openpyxl', if_sheet_exists='overlay') as writer:
current_row_df.to_excel(writer, header=False, index=False, startrow=index)
# 打印当前写入的行数
print(f"写入到Excel的行数: {index + 1}")
except (WebDriverException, TimeoutException) as e:
print(f"Error occurred while accessing {url}: {e}")
continue # 跳过当前迭代,继续下一个
# 关闭浏览器
driver.quit()
运行中终端会提示写入了多少条数据,
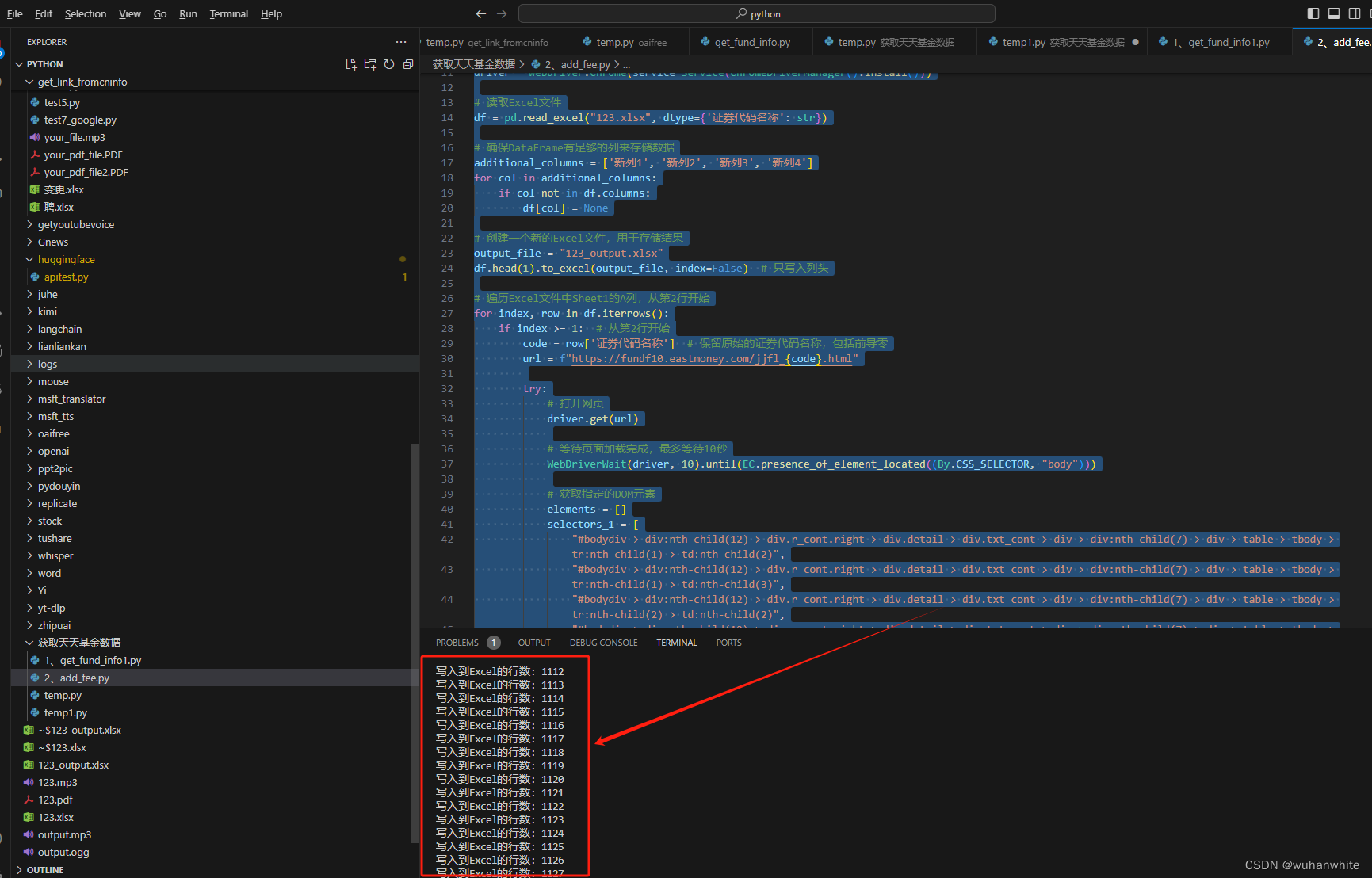
最终运行了1-2小时后,得到了一个excel表格,将这1127个基金的费率情况都获取了下来
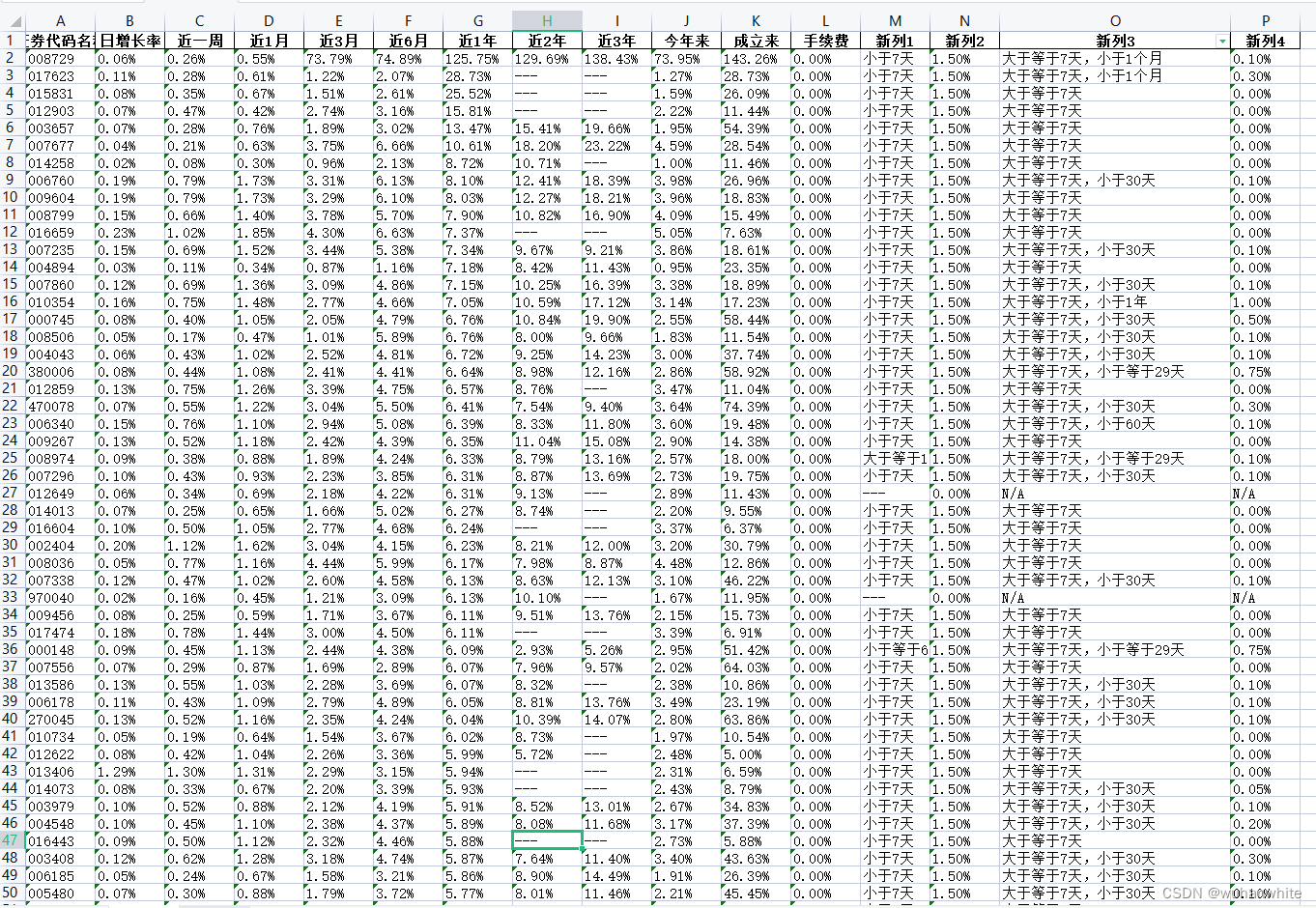
第三步,用excel开始筛选,排序找到心仪的短债基金
筛选出持有7天就能卖出的基金,筛选出来有448个基金
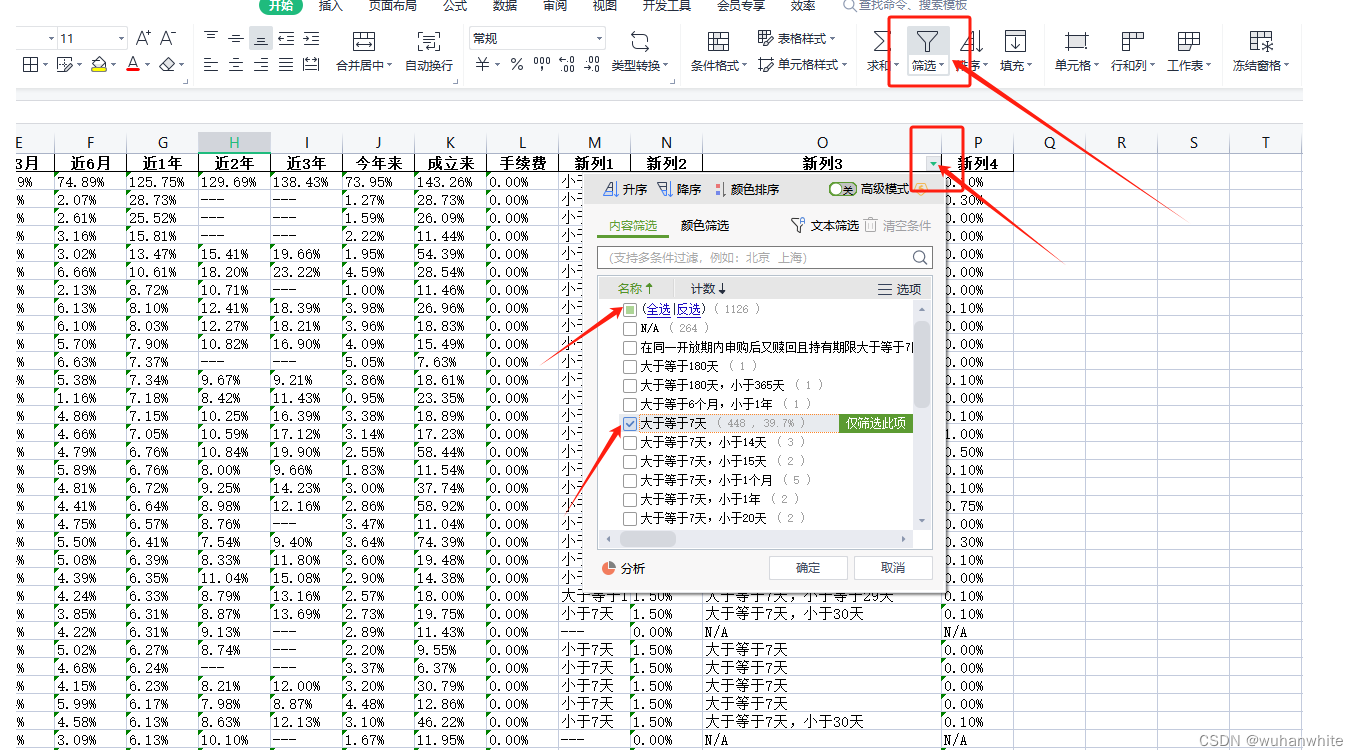
这448个基金就是满足我前面3个条件的基金,然后再进行一个排序,比如找出近一周或者近1个月最好的几个基金排名,我这里按照近一月排名最前的几个基金如下:
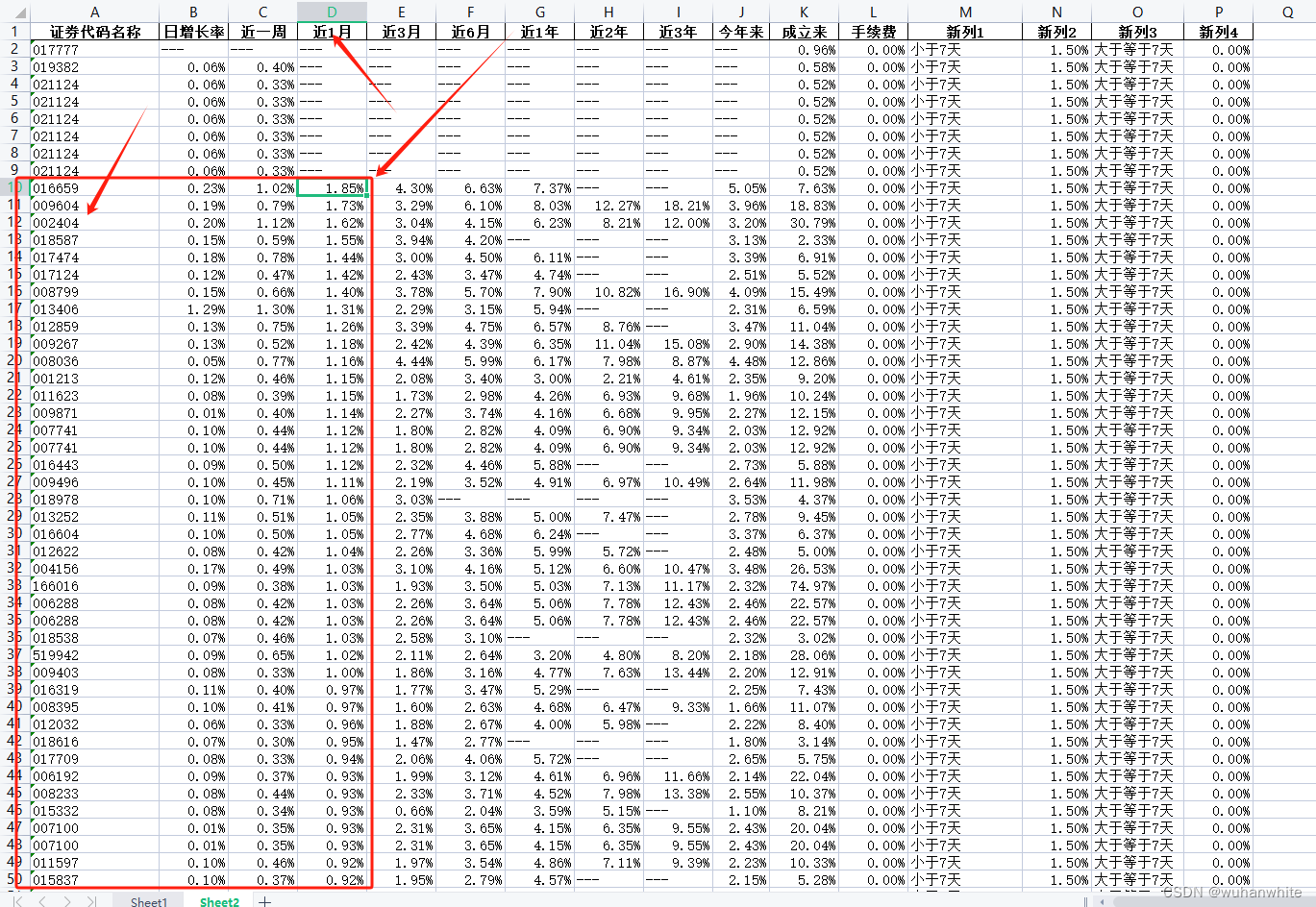
比如:016659,009604,去支付宝上看下这2个基金的走势
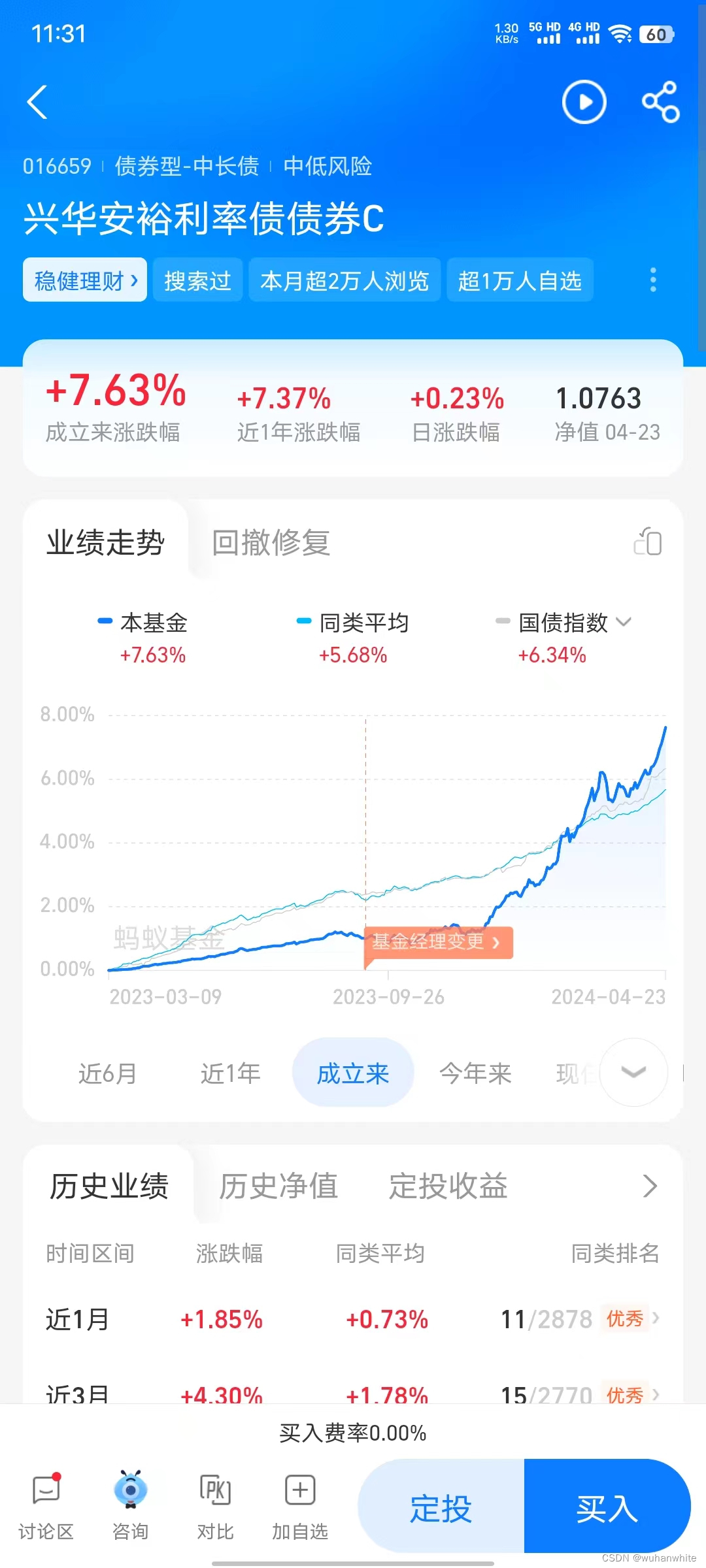
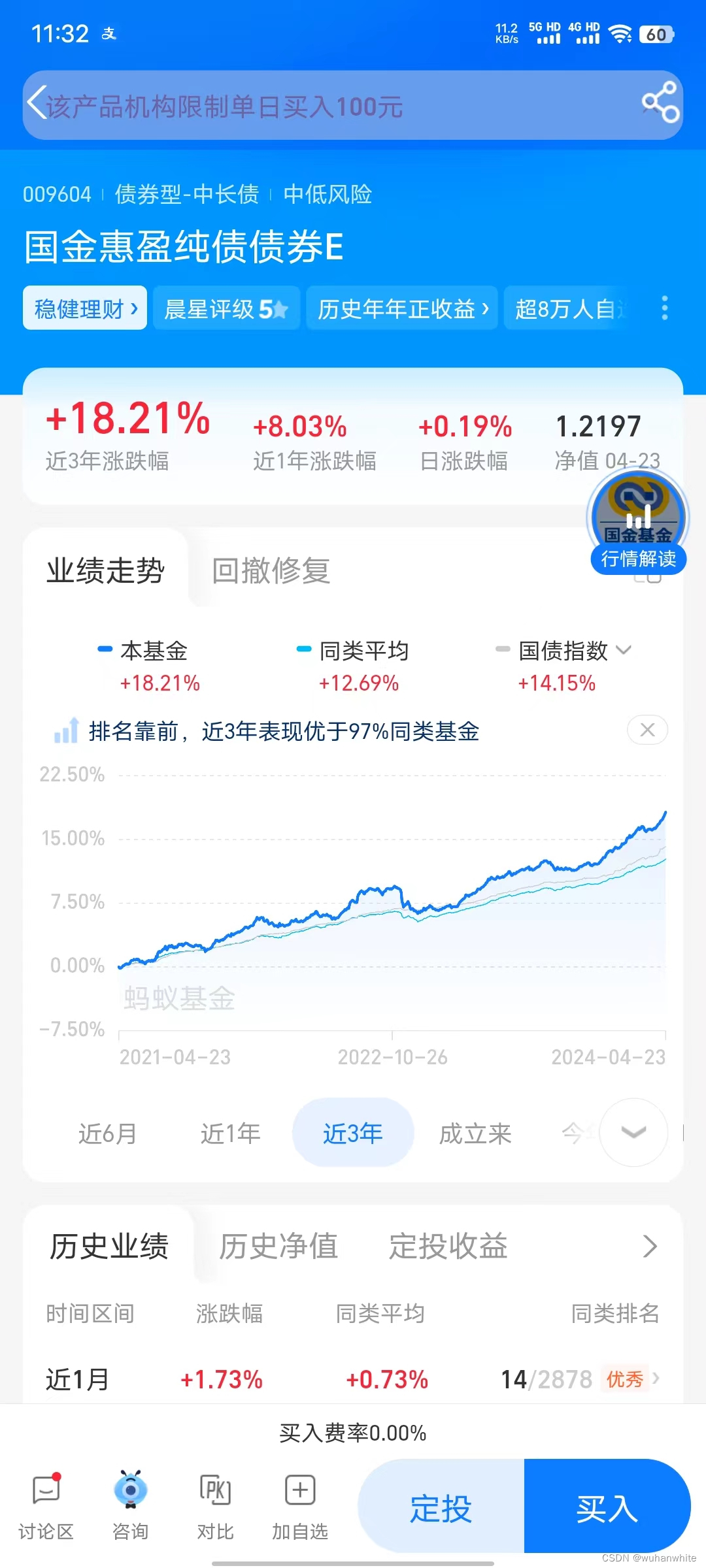
从这个表上看到,这2个产品的月涨幅都在1%以上,年化收益岂不是可以达到10%以上,现在这个时候,理财能有这个收益可是妥妥的小幸福啊。通过这个方法,是不是可以找到那种风险最小,7天就可以卖出,而且,收益超过年化5%的稳健债券型基金?现在国内哪里还能轻松找到年化4%以上的稳健增长的理财产品呢?不过有些债券型基金在支付宝上不能买,有些在银行的基金中也不能买,如果对这个感兴趣的话,想要这400多个基金的代码的话,可以在本帖下留言,共同探讨IT人员如何通过理财赚取睡后收入。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











