







在科技飞速发展的今天,机器人技术正在以一种令人惊喜的方式贴近我们的生活。最近,Physical Intelligence 公司推出了 Pi 0.5 版本,这一创新设计不仅颠覆了传统机器人的运作模式,更让我们看到了未来智能设备融入日常生活的无限可能。Pi 0.5 的核心理念很简单却极具革命性:将机器人的“大脑”分散到身体的每一个角落,而不是集中在一个中央处理器上。想象一下,每个手指、每个关节、甚至一块柔软的硅胶皮肤都拥有自己的微型神经网络,能够即时感知、决策和调整。这意味着,机器人可以走进一个全新的环境,比如你家杂乱的客厅,立即识别出堆积的碗碟,并开始分类整理,而无需依赖地图或Wi-Fi连接。它不再是一个单一的指挥中心,而更像是一群快速反应的“肌肉团队”。
分散智能:从中央大脑到全身神经网络 🌐
传统的机器人设计中,所有传感器数据都需要传输到一个庞大的中央处理器进行计算,然后再将指令发送到四肢。这种模式在工厂流水线等固定环境中表现良好,但在充满变数的现实生活中,延迟、能耗和混乱往往让机器人束手无策。而 Pi 0.5 彻底改变了这一模式,引入了“Pi 节点”的概念。这些节点就像散布在机器人全身的小型乐高积木,分布在手指、肘关节,甚至柔软的硅胶手掌中。每个节点都配备了微型传感器、执行器和一个小型神经网络,能够以闪电般的速度进行强化学习更新。每次微小动作后,节点会自问:“这次动作是否减少了滑动?是否缓解了压力?”然后即时调整参数。

这种分散式智能的好处显而易见。由于“大脑”遍布全身,节点之间无需频繁与中央服务器通信,大幅减少了数据传输的延迟和能耗。在 Physical Intelligence 的测试中,一个软体机械手在使用本地反射回路后,抓握精度提升了30%,能耗降低了25%,相较于传统的“回传中央处理器”架构表现更为优异。同样,在可穿戴触觉套件上的测试也显示,反馈更顺畅,电池续航更长,用户体验更舒适,甚至避免了手部疲劳。这些节点还具备本体感知和触觉感知能力,当机械手在负载下弯曲或拉伸时,节点能在滑动发生前就做出补偿调整。更令人惊喜的是,这种设计对硬件要求极低,甚至可以在一个简单的 ESP32 微控制器上运行固件,真正实现了“智能无处不在”。


双层设计:反射与常识的完美结合 🧠
Pi 0.5 并非单一的设备或神经网络,而是由两个层次组成,分别解决不同的难题。底层可以看作是机器人的“反射机制”,而上层则是机器人的“常识大脑”。底层负责快速反应,比如调整抓握力度或关节角度,确保动作的即时性和稳定性。而上层则是一个视觉-语言-动作模型(VLA),负责更高层次的决策和任务规划。
对于上层模型,Physical Intelligence 团队在数据多样性上下足了功夫。他们首先录制了约400小时的移动操作视频,涵盖了机器人在真实家庭中穿梭、撞到椅子、摸索锅柄的场景;接着又增加了在数十个不同环境中拍摄的静态机器人片段,甚至包括来自更简单机械臂的跨设备数据;最后,他们还将网络上的标准数据(如图像标注、问答、物体检测)以及人类逐步指导机器人完成复杂任务的语音指令数据融入训练集。这一庞大的“混合课程”让 Pi 0.5 学会了从“什么是枕头”到“陶瓷盘能承受多大力道”的各种知识。
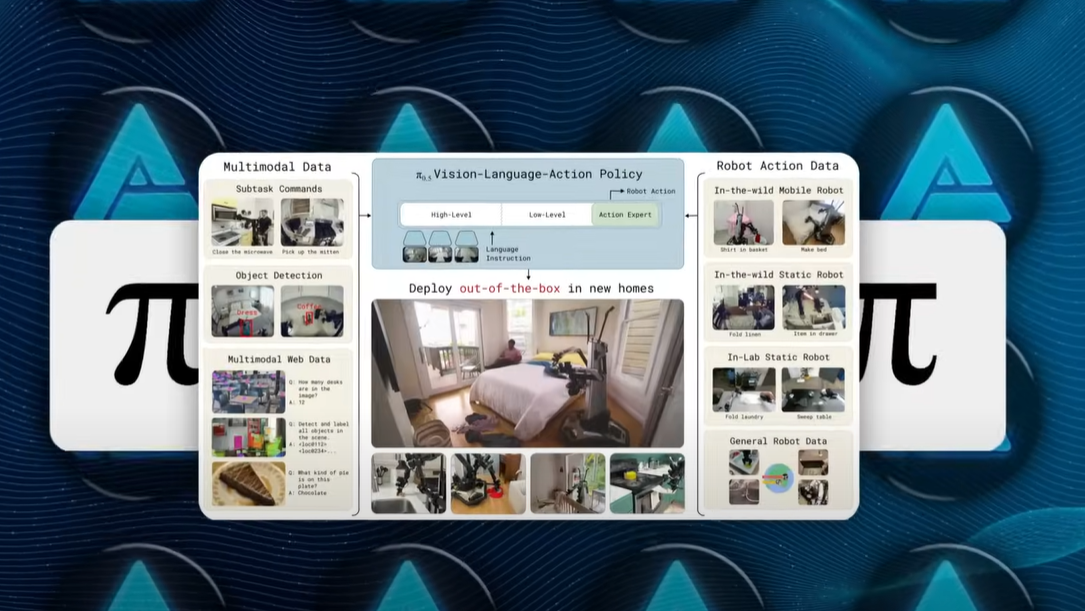
这种多样性训练的效果如何呢?在分布内清洁任务测试中(即与训练环境相似的家庭场景),Pi 0.5 实现了86%的语言指令遵循率和83%的任务完成率,甚至细致到将每一只盘子放入水槽这样的子任务。而在更具挑战性的分布外测试中(全新房屋、物体和光线条件),Pi 0.5 依然取得了94%的指令遵循率和任务完成率。如果剔除训练中的互联网图片数据,成功率会降至70%中段;若再去掉多环境机器人数据,成功率更是跌至31%。可见,数据的多样性不仅是锦上添花,更是机器人适应的命脉。
实时思考:机器人也有“内心独白” 💭
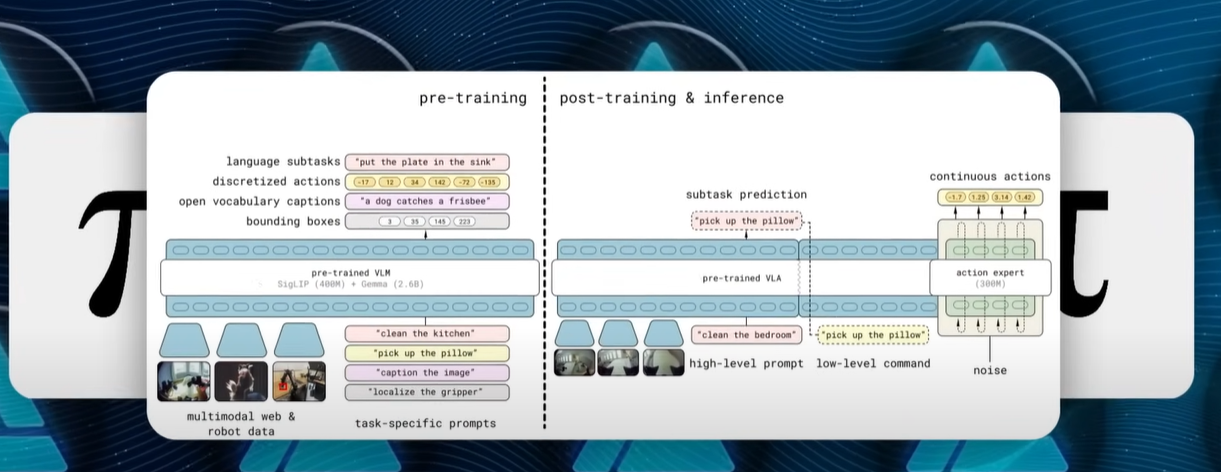
更令人着迷的是,Pi 0.5 在运行时每秒都会进行一次完整的“思维链”循环。首先,它会生成一个高层次的文本指令,比如“拿起枕头”,这一过程类似于 ChatGPT 生成句子的离散标记解码。接着,无需切换模型,它会将权重调整为连续流匹配模块,输出50个关节角度,形成1秒的动作片段。手臂随之移动,节点微调抓握力度,摄像头捕捉新画面,然后循环重新开始。整个过程将语言理解和物理动作融为一体,实时进行。
这种分层设计还模仿了人类神经系统的运作方式:底层的节点反射机制如同脊髓,负责即时处理重量和触感,而上层的 VLA 模型则像前额叶皮层,负责规划下一步目标。比如,当你在端咖啡杯时,脊髓会自动调整手部力度,而大脑则在思考钥匙放哪儿了。Pi 0.5 也是如此,上层模型以稍慢的节奏思考语义目标,而底层节点则快速稳定动作,确保盘子不掉落。
真实测试:走进陌生家庭的“智能帮手” 🏠
Pi 0.5 的能力在真实环境中得到了充分验证。团队将机器人带入陌生人的公寓,没有预扫描、没有标记,只是单纯记录成功和失误的视频。机器人能够整理床铺、折叠衣物、用海绵擦拭污渍、捡拾玩具。虽然偶尔会误识别毛绒玩具,或者手臂轨迹出现偏差,但大多时候它都能自我修正。甚至当旁观者故意在擦拭中途撞击手臂时,机器人也能重新计算并继续工作。你可以对它下达精确指令,比如“拿起圆刷子”,它会准确锁定目标;也可以模糊指令,比如“打扫卧室”,它会自动将任务拆分为小步骤并逐一完成。



从能耗角度看,分散式设计堪称亮点。每个节点仅运行必要的计算核心,使得移动底座的续航时间更长。这也是为什么机械手演示中能耗降低了25%的原因。更令人惊讶的是,这些节点可以在微控制器甚至纽扣电池上运行,真正实现了边缘智能的低功耗优势。
未来展望:从实验室到生活的无限可能 🚀
当然,Pi 0.5 并非完美无瑕。它有时会选择错误的计划,撞到柜子,或者以错误的角度抓取叉子。团队坦言,他们的目标是打造能从自身运行中学习(无需人类标注)、能即时提问澄清、并在不同硬件间迁移技能的模型。想象一下,同一个“大脑”可以从双臂移动底座切换到可穿戴外骨骼套件,而无需重新训练。他们也在积极寻找合作伙伴,覆盖超市、医院、养老院等场景,以获取更多真实世界数据,喂养这个“数据怪兽”。
回到最初的愿景,Pi 0.5 的真正魅力在于两点:一是嵌入身体的智能(Pi 节点),让机器人无需等待Wi-Fi反馈就能感知并调整力度;二是数据丰富的 VLA 模型,让它能在全新环境中自如应对。这两层设计模糊了训练套路与真正适应性之间的界限。每秒钟,机器人都在与自己进行一场无声对话:“高层次目标是洗碗,第一步是拿起勺柄,节点请施加三牛顿抓力并注意滑动……好,现在转向水槽。”这种“思维链”与本体感知的结合,正是 Pi 0.5 的突破所在。
多年来,我们见过能在特定场地完成高难度动作的机器人,也见过能侃侃而谈却无法拧开门的语言模型。而 Pi 0.5 通过边缘反射与数据驱动的“看护大脑”结合,缝合了两者的差距。它或许只是一个中点——如其名字所示,介于 Pi 0 和未来的 Pi 1 之间。但这个中点已经足以让机器人走进陌生厨房,识别未见过的盘子,规划清理任务,并在不到10毫秒内调整抓握力度,同时不耗费过多电量。如果这只是旅程的一半,那么接下来的路程将更加令人期待!
你会最先信任 Pi 0.5 机器人完成哪项家务呢?是洗碗、叠衣服,还是整理房间?欢迎留言分享你的想法!😊


















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











