






🔥你绝对想不到——就在昨夜,硅谷的AI军备竞赛突然被扔进一颗“战术核弹”
链接地址:
凌晨三点的推特突然炸锅:NVIDIA悄无声息地开源了一个名叫Llama 3.1 Nemotron Ultra的模型。这个仅有2530亿参数的“小家伙”,竟然在多项任务中碾压了参数量多它2.6倍的顶级 MoE模型DeepSeek R1!更疯狂的是,它像装了物理外挂般能随时切换“大脑模式”——日常问答用省电模式,解数学题时秒变超频状态。
💡颠覆性的事实:模型性能的胜负手,从来不是参数量的军备竞赛
(此处插入选择题)
当两个AI模型对决时,你认为决胜关键是:
A)参数规模 B)算法效率 C)推理模式切换能力 D)硬件适配性
答案是——全错!NVIDIA这次用神经架构搜索(NAS)黑科技证明:“精准外科手术式”的模型裁剪才是王道。他们像《盗梦空间》的造梦师一样,把Meta原版Llama 3拆解重构:砍掉冗余注意力块、合并前馈网络、甚至发明出“跳层注意力”……最终调教出的模型,不仅能在8块H100显卡上狂奔,还自带“思维深度调节旋钮”。
❗️反常识暴击:
那个在Math 500测试中拿到97%准确率的“数学学霸”,和生成代码时pass@1暴增127%的“编程大神”,其实是同一个模型的不同人格——区别只在于开发者是否悄悄说了句“详细思考模式,启动!”
📌接下来你将看到:
- 1. 场景化拆解:为什么说这个模型是“AI界的瑞士军刀”?(内含代码工程师用Neatron Ultra 5分钟debug百万行仓库的神操作)
- 2. 行业地震分析:当推理成本砍半时,哪些AI公司将一夜破产?(对比图:跑通同类任务所需GPU集群的价格差)
- 3. 开发者实战指南:如何用一行Python代码切换AI的“天才模式”与“节能模式”(附HuggingFace部署避坑手册)
🚨此刻最该警惕的事:
当所有媒体都在吹捧97%的数学得分时,没人告诉你——那个在AIME25测试中被DeepSeek反杀8%的软肋,可能葬送你的关键业务场景……
(下一页将用《三体》的“降维打击”理论,解密NVIDIA如何用“模型瘦身术”重构AI竞争维度)
NVIDIA的"小怪兽"模型:如何用一半的体量击败行业巨头?
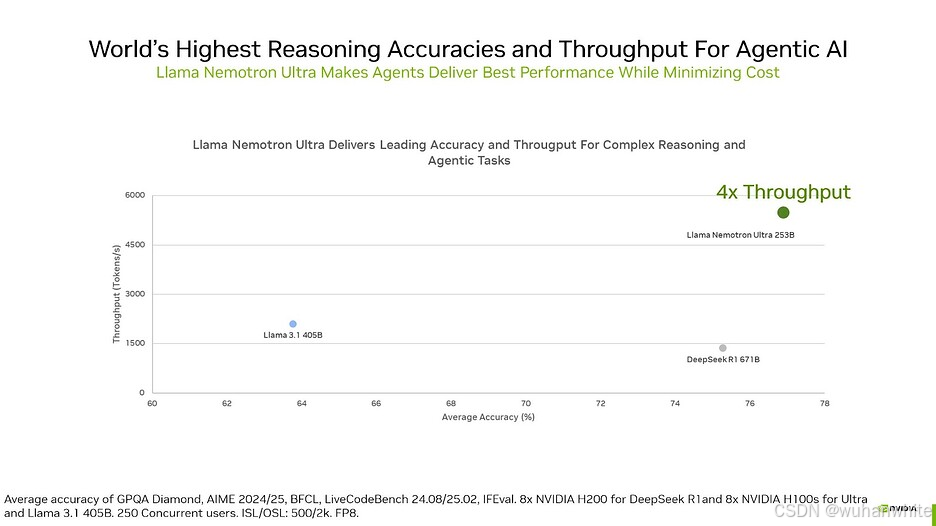
当所有人都在追求"越大越好"时,NVIDIA悄悄扔出了一个深水炸弹。 这个名为Nemotron Ultra的模型,体积只有DeepSeek R1的一半,却在大多数任务上实现了反超。更令人震惊的是,它能在"浅层推理"和"深层推理"之间自由切换,就像给AI装上了可调节的"智商开关"。这背后隐藏着怎样的技术革命?让我们揭开这个看似不可能的性能奇迹。
▍第一重颠覆:神经架构搜索(NAS)的魔法裁剪
传统的AI模型开发像在黑暗森林中摸索,而NVIDIA采用的神经架构搜索技术,则像给开发者配备了热成像仪。通过对Llama 3.1 405B模型的精准解剖,团队做出了大胆的"外科手术":某些网络块完全跳过了注意力机制,前馈层被压缩得更为紧凑,多个前馈网络则被融合成更高效的超级模块。这种"去肥增瘦"的操作,使得这个拥有2530亿参数的庞然大物,居然能在8块H100 GPU上流畅运行。
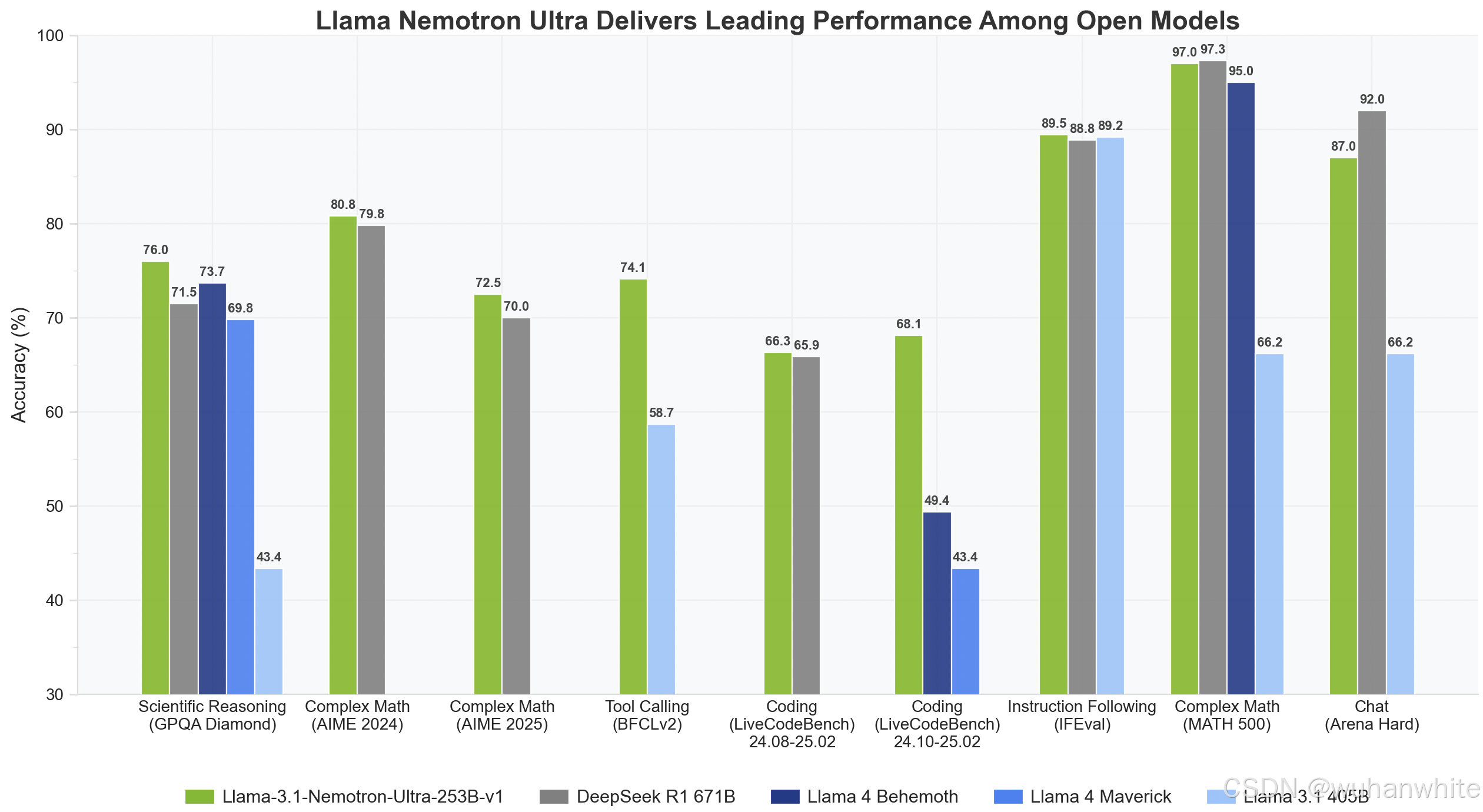
❗️数据冲击: 在数学500基准测试中,当开启"深度推理"模式时,模型准确率从80.4%飙升至97%,相当于让一个高中生突然掌握了菲尔兹奖得主的数学直觉。更惊人的是代码生成任务,在Live CodeBench测试中通过率从29.03%跃升至66.31%,这种性能跃迁堪比给程序员装配了"自动驾驶"系统。
▍第二重革新:可切换的"双模大脑"
想象你的手机能在省电模式和性能模式间无缝切换,Nemotron Ultra将这种理念带入了AI领域。当处理简单指令时切换为"推理关闭"模式,如同使用计算器的基本功能;面对复杂数学证明或代码生成时启动"推理开启"模式,瞬间变身超级计算机。这种动态资源调配的能力,使得它在保持高效率的同时,仍能应对高难度任务。
💡反常识认知: 在GPQA通用问答挑战中,该模型的表现从56.6%提升到76.01%,而竞争对手DeepSeek R1(拥有6710亿参数)在这个项目上反而略逊一筹。这彻底打破了"参数规模决定一切"的行业迷信,证明智能的质量不在于脑容量大小,而在于神经连接的有效性。
(以下是自然过渡段落)
这种突破性的表现并非偶然。NVIDIA构建了一个多阶段训练管道:从监督微调开始,经历强化学习的打磨,再到知识蒸馏的提纯。就像米其林大厨处理食材,每个环节都追求极致的火候控制。特别是使用了880亿token的继续预训练,配合FineWeb、BuzzV1.2等精选数据集,最终炼就了这个AI界的"六边形战士"。
▍第三重优势:商业化的开放生态
在这个各家紧抱核心技术的时代,NVIDIA却选择了全面开源。通过NVIDIA开放模型许可和Llama 3.1社区许可的双重保障,开发者可以自由获取模型权重甚至训练数据。这种开放姿态背后是深思熟虑的战略:当模型可以直接部署在聊天机器人、编程辅助工具等各种商业场景时,实际上是在为NVIDIA的硬件生态铺设更深的护城河。
🔥行业隐喻: 这就像特斯拉公开电动车专利,表面上放弃短期利益,实则为整个行业制定了以自家技术为标准的发展路线图。那些采用Nemotron Ultra的企业,未来很可能会自然地选择NVIDIA的GPU集群来部署服务。
(技术细节的自然衔接)
对于开发者而言,集成过程异常简单。使用Hugging Face Transformers库时,只需在系统提示中添加"detailed thinking on/off"就能控制推理深度。NVIDIA甚至贴心地给出了推荐参数:深度模式建议温度值0.6,而快速响应时采用确定性更强的贪婪解码。这种"开箱即用"的友好设计,大大降低了企业采用门槛。
此刻我们正站在AI演进的关键分水岭上。 当业界还在为千亿参数模型争得头破血流时,NVIDIA用这个"小而美"的案例证明:未来的竞争维度正在发生本质变化。下一章,我们将深入剖析哪些行业会最先被这场效率革命颠覆,以及普通开发者如何乘上这波技术红利——毕竟,当恐龙还在为体型骄傲时,哺乳动物已经悄悄进化出了更聪明的大脑。
全文总结
NVIDIA的这款Neatron Ultra 253B,凭借其独特的“动态推理开关”和高效的硬件适应性,成功在小体量模型中实现了超越巨头DeepSeek R1的性能表现。它不仅在代码生成、问答推理等任务上展现出惊人的灵活性,还能够以更低的硬件成本运行——仅需8块H100 GPU就能驾驭这个2500亿参数的庞然大物。更令人兴奋的是,它完全开源,开发者可以自由下载、微调,甚至商用。
这款模型的核心亮点在于它的**“推理模式切换”**功能——通过简单的系统指令,就能在“深度思考”和“快速响应”之间无缝切换。比如,数学和代码任务的准确率在开启推理模式后飙升近20%,而日常对话和简单指令则能以更低延迟完成。这种设计不仅优化了资源利用率,还为开发者提供了前所未有的控制权。
此外,**超长上下文支持(128K tokens)**让它成为处理复杂文档、代码库和长对话的理想选择。而通过神经架构搜索(NAS)技术,NVIDIA对底层模型结构进行了智能剪裁和压缩,确保它在保持高性能的同时,大幅降低了内存占用。
行动建议
如果你是一位开发者,以下是你可以立即尝试的步骤:
- 1. 下载模型:前往Hugging Face获取开源权重和训练数据,确保你的硬件环境支持BF-16或FP8精度。
- 2. 配置推理模式:在代码中通过
detailed thinking on/off指令切换推理深度,根据任务需求灵活调整。 - 3. 测试长文本处理:上传大型文档或代码库,验证其长上下文理解能力,比如法律合同分析或代码调试。
- 4. 安全评估:尽管模型开源,但务必进行伦理和偏见的本地化测试,尤其是面向公众的产品。
如果是企业用户,可以考虑:
- • 低成本部署:对比传统大模型的硬件需求,Neatron Ultra的压缩架构能显著降低运营成本。
- • 多语言支持:尝试在英语之外的场景(如德语、西班牙语)中测试其表现,挖掘全球化应用的潜力。
引发思考的结尾句
在这个“越大越好”的AI竞赛中,NVIDIA用Nemotron Ultra证明了一件事:真正的智能不在于参数的数量,而在于如何高效地使用它们。当技术开始学会“做减法”,或许是时候问自己:我们追求的到底是模型的规模,还是解决问题的实际能力?
(⚠️ 注意:实际部署前,请务必阅读NVIDIA的开源协议条款,并确保合规使用。)
Hugging Face地址:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











