






yolov3放置在docker中/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample/04_detection/02_yolov3_darknet53/mapper

模型所需要的prototxt和caffe模型yolov3.caffemodel文件放置在docker中的/open_explorer/ddk/samples/ai_toolchain/model_zoo/mapper/detection/yolov3_darknet53路径下
![]()
1、 模型验证: ./01_check.sh
报错如下
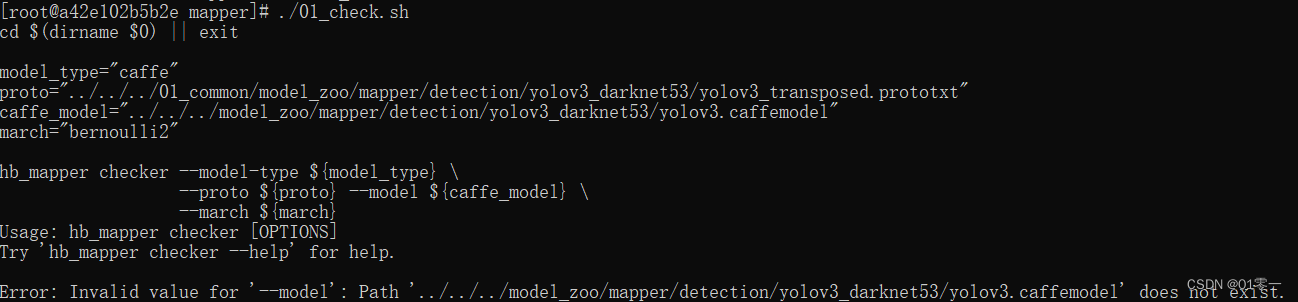
路径配置问题
vim 01_check.sh修改如下
![]()
通过检查
2、 准备校准数据: ./02_preprocess.sh

可以看到数据校准文件夹calibration_data_rgb_f32
3、模型转换 ./03_build.sh
报错如下

路径问题修改yolov3_darknet53_config.yaml如下

再次执行成功生成转换结果model_output文件夹 
模型转换后有三个关键文件:
yolov3_darknet53_416x416_nv12_original_float_model.onnx:图像量化前的模型yolov3_darknet53_416x416_nv12_quantized_model.onnx:图像量化后的模型yolov3_darknet53_416x416_nv12.bin:在BPU上用于推理的模型文件,输出结果与yolov3_darknet53_416x416_nv12_quantized_model.onnx一致。
4、运行推理
在官方给的demo中,04_inference.sh可以直接调用执行好的模型进行推理,但是为了我觉得这种方案对于未来要如何部署自己的模型是无意义的。
编写inference_model.py
import numpy as np
import cv2
import os
from horizon_tc_ui import HB_ONNXRuntime
from bputools.format_convert import imequalresize, bgr2nv12_opencv, nv122yuv444
from bputools.yolo_postproc import modelout2predbbox, recover_boxes, nms, draw_bboxs
modelpath_prefix = '/open_explorer/ddk/samples/ai_toolchain/horizon_model_convert_sample'
# img_path 图像完整路径
img_path = os.path.join(modelpath_prefix, '01_common/test_data/det_images/kite.jpg')
# model_path 量化模型完整路径
model_root = os.path.join(modelpath_prefix, '04_detection/02_yolov3_darknet53/mapper/model_output')
model_path = os.path.join(model_root, 'yolov3_darknet53_416x416_nv12_quantized_model.onnx')
# 1. 加载模型,获取所需输出HW
sess = HB_ONNXRuntime(model_file=model_path)
sess.set_dim_param(0, 0, '?')
model_h, model_w = sess.get_hw()
# 2 加载图像,根据前面模型,转换后的模型是以NV12作为输入的
# 但在OE验证的时候,需要将图像再由NV12转为YUV444
imgOri = cv2.imread(img_path)
img = imequalresize(imgOri, (model_w, model_h))
nv12 = bgr2nv12_opencv(img)
yuv444 = nv122yuv444(nv12, [model_w, model_h])
# 3 模型推理
input_name = sess.input_names[0]
output_name = sess.output_names
output = sess.run(output_name, {input_name: np.array([yuv444])}, input_offset=128)
print(output_name)
print(output[0].shape, output[1].shape, output[2].shape)
# ['layer82-conv-transposed', 'layer94-conv-transposed', 'layer106-conv-transposed']
# (1, 13, 13, 255) (1, 26, 26, 255) (1, 52, 52, 255)
# 4 检测结果后处理
# 由output恢复416*416模式下的目标框
pred_bbox = modelout2predbbox(output)
# 将目标框恢复到原始分辨率
bboxes = recover_boxes(pred_bbox, (imgOri.shape[0], imgOri.shape[1]),
input_shape=(model_h, model_w), score_threshold=0.3)
# 对检测出的框进行非极大值抑制,抑制后得到的框就是最终检测框
nms_bboxes = nms(bboxes, 0.45)
print("detected item num: {0}".format(len(nms_bboxes)))
# 绘制检测框
draw_bboxs(imgOri, nms_bboxes)
cv2.imwrite('detected.png', imgOri)
执行python3 ./inference_model.py

我们可以得到检测结果:

5、上板运行
将下图所示的一些文件拖到旭日X3派开发板中:
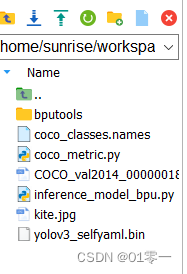
在执行前要安装一些包sudo pip3 install EasyDict pycocotools。
后处理代码inference_model_bpu.py如下:
import numpy as np
import cv2
import os
from hobot_dnn import pyeasy_dnn as dnn
from bputools.format_convert import imequalresize, bgr2nv12_opencv, nv122yuv444
from bputools.yolo_postproc import modelout2predbbox, recover_boxes, nms, draw_bboxs
def get_hw(pro):
if pro.layout == "NCHW":
return pro.shape[2], pro.shape[3]
else:
return pro.shape[1], pro.shape[2]
modelpath_prefix = ''
# img_path 图像完整路径
img_path = 'COCO_val2014_000000181265.jpg'
# model_path 量化模型完整路径
model_path = 'yolov3_selfyaml.bin'
# 1. 加载模型,获取所需输出HW
models = dnn.load(model_path)
model_h, model_w = get_hw(models[0].inputs[0].properties)
# 2 加载图像,根据前面模型,转换后的模型是以NV12作为输入的
# 但在OE验证的时候,需要将图像再由NV12转为YUV444
imgOri = cv2.imread(img_path)
img = imequalresize(imgOri, (model_w, model_h))
nv12 = bgr2nv12_opencv(img)
# 3 模型推理
t1 = cv2.getTickCount()
outputs = models[0].forward(nv12)
t2 = cv2.getTickCount()
outputs = (outputs[0].buffer, outputs[1].buffer, outputs[2].buffer)
print(outputs[0].shape, outputs[1].shape, outputs[2].shape)
# (1, 13, 13, 255) (1, 26, 26, 255) (1, 52, 52, 255)
print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
# 4 检测结果后处理
# 由output恢复416*416模式下的目标框
pred_bbox = modelout2predbbox(outputs)
# 将目标框恢复到原始分辨率
bboxes = recover_boxes(pred_bbox, (imgOri.shape[0], imgOri.shape[1]),
input_shape=(model_h, model_w), score_threshold=0.3)
# 对检测出的框进行非极大值抑制,抑制后得到的框就是最终检测框
nms_bboxes = nms(bboxes, 0.45)
print("detected item num: {0}".format(len(nms_bboxes)))
# 绘制检测框
draw_bboxs(imgOri, nms_bboxes)
cv2.imwrite('detected.png', imgOri)
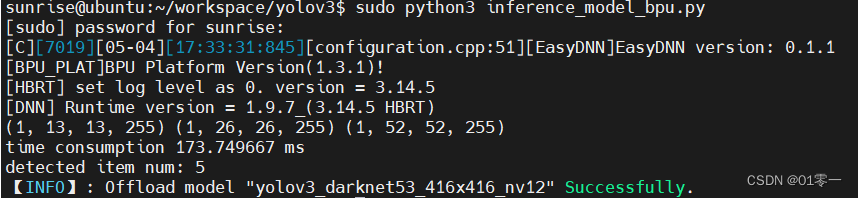
再执行 sudo python3 inference_model_bpu.py,成功输出。
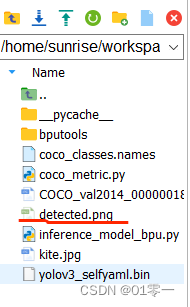
目录中多出了推理结果png文件,打开显示如下:
















 9107
9107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









