







《SUPERPOSITION AS DATA AUGMENTATION USING LSTM AND HMM IN SMALL TRAINING SETS》
链接:https://pan.baidu.com/s/1hMljmjUvC0e7TwZUB7oyTw
提取码:p9kk
摘要
考虑到音频和图像数据具有量子性(数据用密度矩阵表示),我们采用叠加增强的方法混合训练样本,在三层叠加的LSTM和HMM等训练结构上取得了较好的效果,并与普通的默认训练和混合增加进行了比较。这种增强技术源于混合方法,但基于量子特性提供了更坚实的理论推理。在俄语音频数字识别任务中,使用较少的训练样本数38%的训练样本数,取得了3%的改善(从68%提高到71%),而在同一任务中仅使用HMM训练500个样本,准确率提高了7,16%。此外,我们获得了1.1%的准确率比混合使用前900个样品在MNIST使用三层叠加LSTM。
关键词:量子叠加,增广,密度矩阵表示,数字识别。
1. INTRODUCTION
深度学习的主要挑战之一是在小型训练集上进行训练。ICLR-2018中引入了一种称为mix-up的良好正则化和增强技术。我们在量子信息的基础上对该技术进行了改进,并发展了一种用于数据增强的量子叠加技术。该技术包括:(1)从量子信息的角度考虑数据,或者考虑一些深结构的嵌入;(2)使用密度矩阵作为样本的中间表示;(3)使用叠加样本矩阵。我们所做的所有实验都需要通过引入从原始样本中获得的新的、有意义的样本来增加数据集的大小,从而为网络提供更多的多样性和对学习数据的暴露。这在一项科学研究中得到了报道,研究人员得出结论,实验结果使用4倍交叉验证,并以前1名和前5名的准确度报告,表明几何增强中的裁剪显著提高了CNN的任务性能[2]。本文的主要目的是研究和建立在HMM和LSTM中实现叠加原理的语音分类结果。关于俄语语音识别研究方向的重要性,以及在该方向上,特别是在噪声条件下,HMM的应用已经在[3]中得到了说明。由于俄语语音在不同人群中差异很大,通过实验和比较,科学家发现俄语识别效果并不太理想。因此,需要更有效的识别训练算法来达到实际目的[4]。
我们使用隐马尔可夫模型(HMM),因为它是80年代以来最流行的语音识别工具之一。在早期,该算法被应用于有噪声的数字通信链路中进行编码,通过概率密度函数计算语音参数对HMM模型的输出概率,搜索最佳状态序列,得到识别结果,是语音分类任务的一个很好的选择使用最大后验概率准则[5]。LSTM模型使用了一个激活函数,就像卷积神经网络一样,除了这种网络可以处理序列数据之外,它还考虑了先前接收到的输入。它是递归神经网络(RNN)在处理消失和爆炸梯度问题方面的一个“升级”,证明了它对上下文无关的126输出状态模型、上下文相关的2000输出状态嵌入大小模型的语音识别精度有了提高[6]。长短期记忆(LSTM)比标准递归神经网络(RNNs)和时间窗多层感知器(MLPs)快得多,精度也更高。研究人员还表明,一个两层深层LSTM-RNN,其中每个LSTM层都有一个线性递归投影层,可以超过最先进的语音识别性能[8]。今后,我们将坚定地决定使用3层堆叠的LSTM进行训练。
2. EXPERIMENT SETUP
实验在两个不同的数据集上进行,训练样本数较少,班级数较少:(a)俄语音频数字数据集(1775个样本,俄罗斯学生从0到9拼写的数字),(b)MNIST。测试了以下架构:(i)三层堆叠LSTM,(ii)HMM(仅用于音频)。我们用公式叠加初始样本
λ 2 D i 2 + ( 1 − λ 2 ) D j 2 + λ ∗ ( 1 − λ 2 ) ( D i ∗ D j + D j ∗ D j ) \lambda ^{2}D_{i}^{2}+(1-\lambda ^{2})D_{j}^{2}+\lambda *\sqrt{(1-\lambda ^{2})}(D_{i}*D_{j}+D_{j}*D_{j}) λ2Di2+(1−λ2)Dj2+λ∗(1−λ2)(Di∗Dj+Dj∗Dj)
其中,
D
i
D_{i}
Di 和
D
j
D_{j}
Dj 是从数据集中的第i个和第j个样本中获得的密度矩阵,方法是将状态向量的共轭与状态向量本身相乘。这里使用的状态向量是在最后一个致密层之前从致密层获得的。上述方程中的第三项是干涉。这种使用密度矩阵的方法仅适用于LSTM体系结构中的音频,它涉及到在一个神经网络(LSTM)上训练模型,并预测模型中的所有样本,以形成密度矩阵(将第二个最后一个密集层的层嵌入乘以其转置,得到每个样本的64 x 64矩阵),以及最后利用干涉叠加的方法,构造了一个具有相同三层LSTM结构的新模型。
对于MNIST,LSTM体系结构中也使用了相同的方法,但密度矩阵被样本矩阵取代:
λ 2 S i 2 + ( 1 − λ 2 ) S j 2 + λ ∗ ( 1 − λ 2 ) ( S i ∗ S j + S j ∗ S i ) \lambda ^{2}S_{i}^{2}+(1-\lambda ^{2})S_{j}^{2}+\lambda *\sqrt{(1-\lambda ^{2})}(S_{i}*S_{j}+S_{j}*S_{i}) λ2Si2+(1−λ2)Sj2+λ∗(1−λ2)(Si∗Sj+Sj∗Si)
我们也有权使用另一种方法,即使用样本矩阵本身代替密度矩阵,但没有干扰项:
λ S i 2 + ( 1 − λ 2 ) S j 2 \lambda S_{i}^{2}+\sqrt{(1-\lambda ^{2})}S_{j}^{2} λSi2+(1−λ2)Sj2
其中,Si和Sj是从数据集中的第i个和第j个样本中获得的样本矩阵。在这两种情况下,取的λ2值分别为:1、0.2、0.5和0.8。上面的方法是混合或叠加的“量子版本”,没有干涉,因为它使用量子概率。然而,在混合法中,使用了以下公式:
λ
S
i
+
(
1
−
λ
)
S
j
\lambda S_{i}+(1-\lambda)S_{j}
λSi+(1−λ)Sj
式中,取λ值为:1、0.2、0.5和0.8。所有这些方法都是在Keras框架下实现的,使用了支持GPU的TensorFlow后端和内置的分类交叉熵损失函数。使用Adam优化器时,即使Adam显示出相对于SGD的动量略有改善,但它适应不同层的学习速率比例,而不是像SGD[9]中那样手动选择。请注意,我们只使用前1100个音频样本进行训练,因为内存使用有限,对于大于1100的样本,我们多次遇到内存错误和长延迟。我们试着用超过最大内存的1100个样本进行实验。在隐马尔可夫模型中,我们没有使用密度矩阵的方法作为训练的拟合函数。隐马尔可夫模型只接受二维输入,而且不可能将密度矩阵展平用于训练,因为GPU不支持训练非常大的向量。这是因为HMM架构中使用的内置函数没有使用TensorFlow后端或Keras框架。目标标签是一个热编码的。这些都是软标签。例如,一个示例的格式可以是:[0,0.2,0,0,0,0,0,0,0.8]。此示例显示了一个从类别“1”和“9”中选择样本进行混合或叠加的情况。
3. RESULTS
第一个结果是通过对前900个MNIST样本的培训获得的,这些样本在LSTM上混合或叠加:
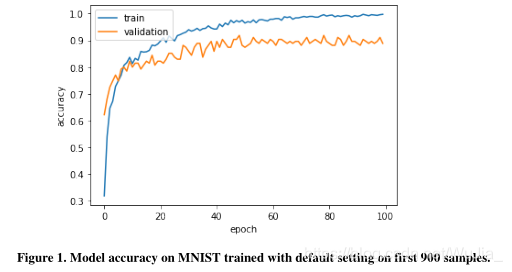
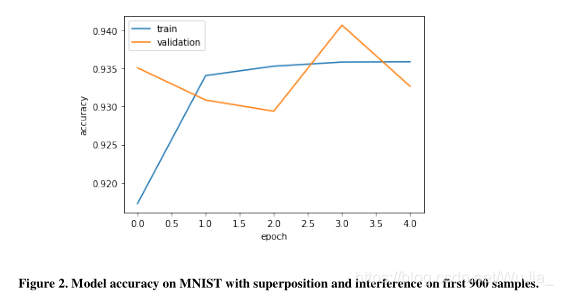
从上图中可以看出,由于训练精度和验证精度之间的差异从10个训练周期中分离出来,因此该模型稍微有点过拟合。这说明了在小数据集上训练最常见的问题:过度拟合。虽然训练的准确率几乎达到100%,但是我们可以看到验证的准确率只有90%。无混叠现象,测试准确率为90.25%。我们注意到,只有900个MNIST样本的混合方法在原始测试数据集上的性能显著提高了3%,而普通训练产生的性能提高了90.25%。对于有干扰的MNIST叠加,我们绘制了带有验证曲线的图来研究模型在训练过程中的行为。我们在原始测试数据上得到的结果比混合法好得多(增加了1%)。
在我们的音频数据集上测试了相同的LSTM架构,其中我们的模型在很大程度上过度拟合了训练数据,如下所示:
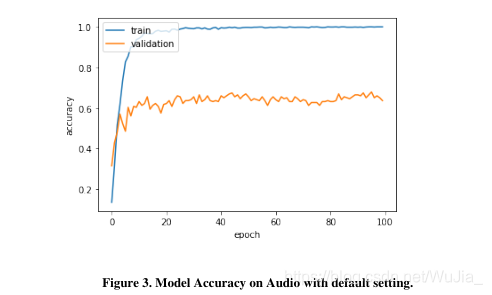
过度拟合背后的思想是训练精度与验证精度有很大的不同。从图中可以清楚地看到这一点。在过拟合的情况下,该模型对测试集分割的预测精度达到68.88%。混合方法产生的结果非常差(10%的测试精度)。我们的密度矩阵方法得到的结果也不令人满意,因为在原始的530个样本列车测试分割的音频测试集上,准确率只有35%。
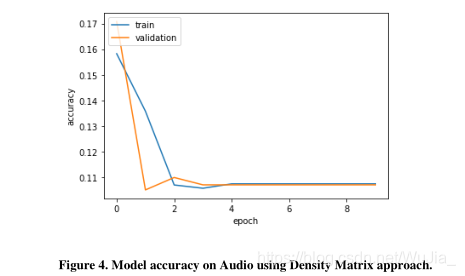
然而,我们通过对第一批1100个叠加音频样本的培训,取得了良好的效果,这些样本都是从零开始的干扰,而不使用任何之前的层嵌入:
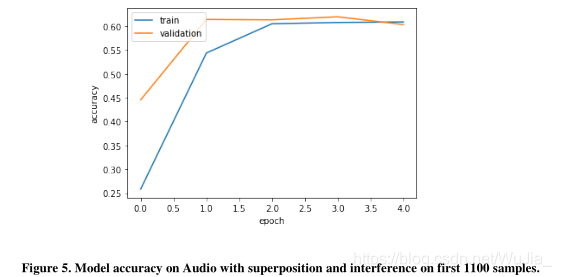
尽管这种带干扰的叠加模型的准确率仅为60%左右,且验证准确率几乎相同,但通过仅对1100个有干扰的叠加数据进行培训,它在整个音频数据集(353个文件)上以0.2的未见测试分割成功实现了71.38%。我们从我们的结果中得出的另一个重要观察是,该模型在预测“表观纯态”或类内叠加时预测更准确或错误较少,即模型能够正确预测具有相同标签的两个不同样本。在这种情况下,标签为“0”的样本和具有相同标签的另一个样本的叠加将有一个热目标[1.0,0,0,0,0,0,0]。该模型似乎比类内叠加态能更好地预测类内叠加态。对于一个仅从原始音频数据集1100个样本中获得的具有干扰的叠加状态训练模型,所获得的结果是令人满意的。最后,我们将HMM模型应用于有叠加的音频训练(“量子版本的混音或无干扰”)、混音方法、无叠加和混音。在这里,我们没有使用密度矩阵方法作为拟合函数用于训练HMM模型只接受2D输入,并且不可能平坦密度矩阵用于训练,因为GPU不支持训练非常大的向量。由于我们只能使用500个样本(每个班级50个样本)进行混合和叠加训练,因此我们仅为500个样本建立了一个基线分数(28.39%),没有混淆和叠加。然后我们在500个样本上使用混合方法,使用与LSTM中使用的lambda值相同的混合比例,但在这里我们获得了29.5%的准确度。但是,当在隐马尔可夫模型中使用叠加时,我们发现测试准确率(36.66%)比基线分数提高了约8.3%。在隐马尔可夫模型的训练过程中,我们只对类内叠加样本或“表观纯态”进行叠加,也就是说,我们的叠加训练数据集只有原始样本(没有叠加或纯态)和表观纯态。我们没有使用类间的重叠样本,因为首先,我们没有足够的内存来运行一个非常大的重叠数据集的代码;其次,我们在之前对叠加数据使用LSTM的实验中的观察表明,该模型在类内叠加时预测得更好。
4. RESULTS SUMMARY

5. CONCLUSIONS
通过对1775个原始样本中1100个样本进行干扰叠加,音频原始测试分割的准确率达到71.38%。当我们在没有叠加的情况下训练时,这个模型过于拟合了。叠加原理同样适用于900个样本的MNIST数据集,在10000个样本的原始测试数据集上产生94.1%的测试准确率,优于混合方法和默认测试精度。混合方法不适用于LSTM体系结构中的音频。对于使用LSTM结构的音频,在前一层嵌入得到的密度矩阵上应用叠加的方法效果不佳。将叠加原理应用于HMM,取得了36.66%的正确率。当我们有一个小的训练集时,叠加是一种很好的正则化技术。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









