







总共就 400 来页对数据挖掘的描述,剩下都是对 Weka Workbench 用法的讲解。
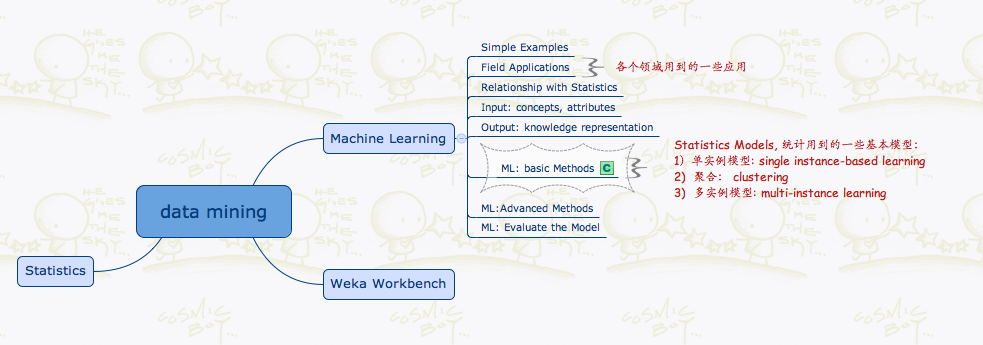
开始讲了 2 个比较入门级别的算法, 不知道如何翻译,扎抄原文如下:
- Inferring Rudimentary Rules
- Statistical Modeling
第一个算法也叫1R: Simplicity First: 最简单最优先法则
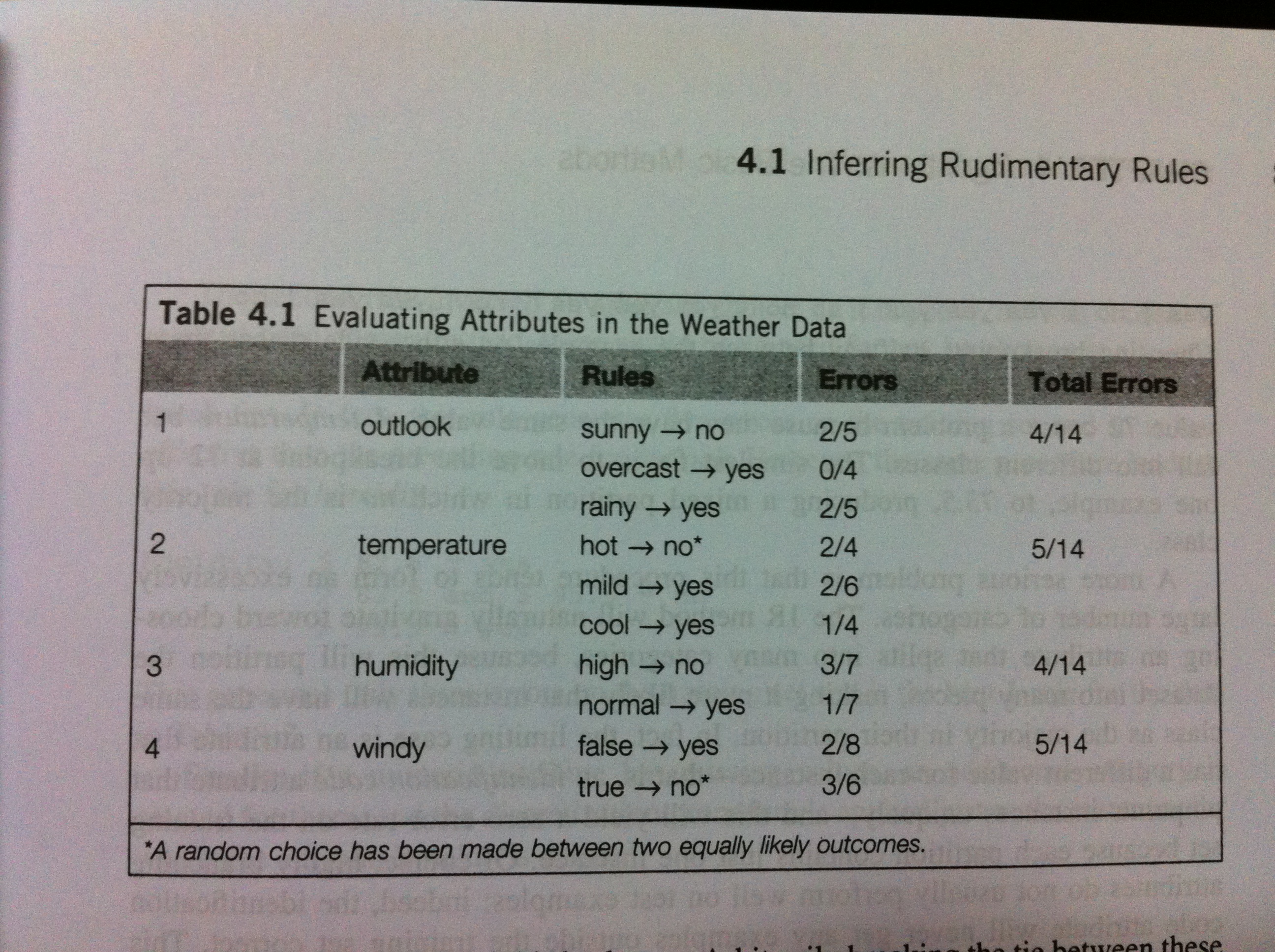
1) 根据每个不同的属性的值,设置一套与结论匹配的规则。如果与结论对应(假设其他属性值不变,因为某个属性值导致了结果经常出现),这个属性值代表的规则就为 true, 反之,则为 false; 把为 false 的记录简单相加,并除以符合这个属性的所有记录的个数,得到这个属性的某一些值与结论不合符的比例,比例最小的属性则对结论的关键性决定就越强
2) 根据第一条规则,为什么要计算“不符合”的属性比例,而不是计算“符合”属性的比例,这样不是更快捷?
第二个算法是基于统计建模来判别属性值与结果的概率,核心思想是 - 每个属性同等重要与独立不相关
1) 假设有四个 Attribute, Outlook, Temperature, Humidity, Windy. 有一个结果 play ( true, false). 这四个属性对结果来说,是同等重要的,没有相互依懒或者权重的关系。
2)我们计算每个属性值对应结果 play(true, false) 的概率, 如下图所示: 归纳了每个属性值的两类概率:在本属性区域内的概率,和在整个数据集当中对应的概率
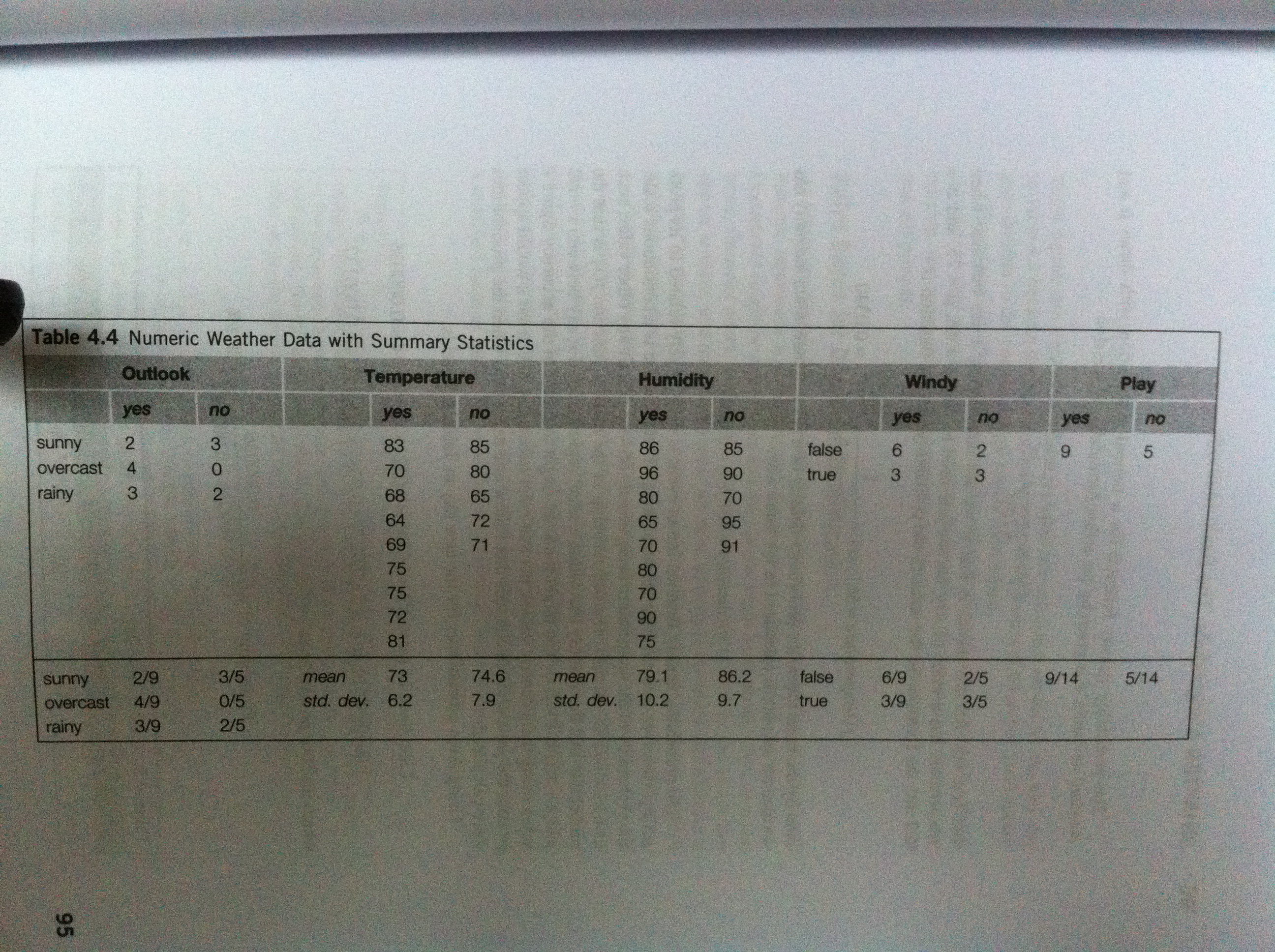
那么对于给定的一个预测值,我们预测它对应的 play(true, false) 对应的概率,是这样计算的:
假设:Outlook = Sunny, Temperature = cool , Humidity = high , Windy = true , Play = ?
P(play=yes)=2/9X3/9X3/9X3/9X9/14=0.0053
P(play=false)=3/5X1/5X4/5X3/5X5/14=0.0206
有一种异常,当一个属性值 比如 Temperature = Hard Cool, 那么概率就是 0 了。 我们可以这样解决:凑份子
P(play=yes)=(2+up1)/(9+u)X(3+up2)/(9+u)X(3+up3)/(9+u)…..
这里, p1 + p2 + p3 = 1. 那么我们就可以给这些附上权重,当然有点违背 Statistics Modeling 的初衷。
统计建模的概率计算法则:
















 2030
2030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











