







总体架构
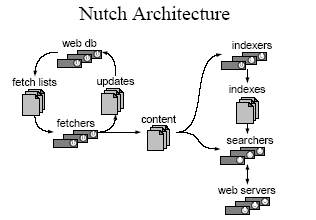
总体上,Nutch可以分为2个部分:抓取程序(crawler)和搜索程序(searcher)。抓取程序抓取页面并把抓取回来的数据做成反向索引,搜索程序则利用反向索引检索回答用户的查找关键词来产生查找结果。两者之间的接口是索引,两者都使用索引中的字段。实际上搜索程序和抓取程序可以分别位于不同的机器上,这样可以提升性能。
Crawler涉及的数据结构
抓取程序是被Nutch的抓取工具驱动的。这是一组工具,用来建立和维护几个不同的数据结构: web database, a set of segments, and the index,三者的物理文件分别存储在爬行结果目录下的db目录下webdb子文件夹内,segments文件夹和index文件夹。下面我们逐个解释上面提到的3个不同的数据结构。
web database, 或者WebDB, 是一个特殊存储数据结构,用来映像被抓取网站数据的结构和属性的集合。WebDB 用来存储从抓取开始(包括重新抓取)的所有网站结构数据和属性。WebDB只是被抓取程序使用,搜索程序并不使用它。WebDB 存储2种实体:页面和链接。页面表示网络上的一个网页,这个网页的Url作为标示被索引,同时建立一个对网页内容的MD5 哈希签名。跟网页相关的其它内容也被存储,包括:页面中的链接数量(外链接),页面抓取信息(在页面被重复抓取的情况下),还有表示页面级别的分数 score 。链接 表示从一个网页的链接到其它网页的链接。因此 WebDB 可以说是一个网络图,节点是页面,链接是边。
Segment 是网页的集合,并且它被索引。 Segment 的 Fetchlist 是抓取程序使用的url列表,它是从 WebDB中生成的。Fetcher的输出数据是从 fetchlist 中抓取的网页。Fetcher 的输出数据先被反向索引,然后索引后的结果被存储在segment 中。 Segment 的生命周期是有限制的,当下一轮抓取开始后它就没有用了。默认的重新抓取间隔是30天。因此删除超过这个时间期限的segment是可以的。而且也可以节省不少磁盘空间。Segment 的命名是 日期加时间 ,因此很直观的可以看出他们的存活周期。
index即索引库是反向索引所有系统中被抓取的页面,他并不直接从页面反向索引产生,它是合并很多小的 segment 的索引中产生的。Nutch 使用Lucene来建立索引,因此所有 Lucene 相关的工具API 都用来建立索引库。需要说明的是 Lucene 的 segment 的概念 和 Nutch 的 segment概念是完全不同的,不要混淆哦。可以参考 车东 的相关文章。 www.chedong.com 简单来说 Lucene 的segment 是 Lucene 索引库的一部分,而 Nutch 的 Segment 是WebDB中被抓取和索引的一部分。
Crawler工作原理
在分析了Crawler的数据结构后,接下来我们研究一下Crawler的工作原理和流程以及这些数据结构所扮演的角色。抓取是一个循环的过程:抓取蜘蛛从WebDB中生成了一个 fetchlist 集合;抽取工具根据fetchlist从网络上下载网页内容;蜘蛛程序根据抽取工具发现的新链接更新WebDB;然后再生成新的fetchlist;周而复始(注:蜘蛛是分两个部分的)。这个抓取循环在nutch中经常指: generate/fetch/update 循环。
一般来说同一域名下的url 链接会被合成到同一个 fetchlist。这样做的考虑是:当同时使用多个蜘蛛抓取的时候,不会产生重复抓取的现象;也可以防止过多的Fetchers对同一主机同时抓取造成主机负担过重。此外Nutch 遵循 Robots Exclusion Protocol, 网站可以用robots.txt 定义保护私有网页数据不被抓去。
上面这个抓取工具的组合是Nutch的最外层的,你也可以直接使用更底层的工具,自己组合这些底层工具的执行顺序达到同样的结果。下面把上述过程分别详述一下,括号内就是底层工具的名字:
01) 创建一个新的WebDB (admin db -create)。
02) 把开始抓取的跟Url 放入WebDb (inject)。
03) 从WebDb的新 segment 中生成 fetchlist (generate)。
04) 根据 fetchlist 列表抓取网页的内容 (fetch)。
05) 根据抓取回来的网页链接url更新 WebDB (updatedb)。
06) 重复上面3-5个步骤直到到达指定的抓取层数。
07) 用计算出来的网页url权重 scores 更新 segments (updatesegs)。
08) 对抓取回来的网页建立索引(index)。
09) 在索引中消除重复的内容和重复的url (dedup)。
10) 合并多个索引到一个大索引,为搜索提供索引库(merge)。
在创建了一个新的WebDB后,抓取循环 generate/fetch/update 就根据 最先第二步指定的根 url 在一定周期下自动循环了。当抓取循环结束后,就会生成一个最终的索引(从第7步到第10步)。
需要说明的是:上面第 8 步中每个 segment 的索引都是单独建立的,之后才消重(第9步)。第10步就是大功告成,合并单独的索引到一个大索引库。
Dedup 工具可以从 segment 的索引中去除重复的url。因为 WebDB 中不允许重复的url , 也就是说 fetchlist 中不会有重复的url,所以不需要对 fetchlist 执行 dedup 操作。上文说过,默认的抓取周期是30天,如果已经生成的旧 fetch 没有删除,而又生成了新的fetch 这是还是会出现重复的url的。当只有一个抓取程序运行的时候是不会发生上述情况的。
从上面的介绍可以看出,一般情况下我们只要从头执行的程序就可以了,不需要接触底层的工具。但是搜索引擎有很多“意外”,很多的时间需要花费在维护上,所以底层的工具也是需要掌握的。我将会在下文给你演示如何运行上述过程。
本文是面向一个中型的搜索引擎的,如果做像百度这样的抓取互联网数据的引擎,你就需要参考下面的资源。
资源列表:
1、Nutch project page Nutch项目的大本营,想必大家都知道。
2、邮件列表: nutch-user 和 nutch-dev
3、在写本文的时候 Map Reduce 已经放到nutch的svn中了,不过还不是发布版本。我记得是Doug Cutting 在签入完 MapReduce 后就去度假了,呵呵。
更多资源:
Nutch tutorial还有一个好消息,写过Eclipse Plugin 的人都知道,Eclipse 架构的强大之处,Nutch 的Plugin 也是基于Eclipse 的,不过现在的版本是 2.0 。详情看这里 PluginCentral
search option
Building Nutch: Open Source Search
Nutch: A Flexible and Scalable Open Source Web Search Engine
一般来说同一域名下的url 链接会被合成到同一个 fetchlist。这样做的考虑是:当同时使用多个蜘蛛抓取的时候,不会产生重复抓取的现象;也可以防止过多的Fetchers对同一主机同时抓取造成主机负担过重。此外Nutch 遵循 Robots Exclusion Protocol, 网站可以用robots.txt 定义保护私有网页数据不被抓去。
上面这个抓取工具的组合是Nutch的最外层的,你也可以直接使用更底层的工具,自己组合这些底层工具的执行顺序达到同样的结果。下面把上述过程分别详述一下,括号内就是底层工具的名字:
01) 创建一个新的WebDB (admin db -create)。
02) 把开始抓取的跟Url 放入WebDb (inject)。
03) 从WebDb的新 segment 中生成 fetchlist (generate)。
04) 根据 fetchlist 列表抓取网页的内容 (fetch)。
05) 根据抓取回来的网页链接url更新 WebDB (updatedb)。
06) 重复上面3-5个步骤直到到达指定的抓取层数。
07) 用计算出来的网页url权重 scores 更新 segments (updatesegs)。
08) 对抓取回来的网页建立索引(index)。
09) 在索引中消除重复的内容和重复的url (dedup)。
10) 合并多个索引到一个大索引,为搜索提供索引库(merge)。
在创建了一个新的WebDB后,抓取循环 generate/fetch/update 就根据 最先第二步指定的根 url 在一定周期下自动循环了。当抓取循环结束后,就会生成一个最终的索引(从第7步到第10步)。
需要说明的是:上面第 8 步中每个 segment 的索引都是单独建立的,之后才消重(第9步)。第10步就是大功告成,合并单独的索引到一个大索引库。
Dedup 工具可以从 segment 的索引中去除重复的url。因为 WebDB 中不允许重复的url , 也就是说 fetchlist 中不会有重复的url,所以不需要对 fetchlist 执行 dedup 操作。上文说过,默认的抓取周期是30天,如果已经生成的旧 fetch 没有删除,而又生成了新的fetch 这是还是会出现重复的url的。当只有一个抓取程序运行的时候是不会发生上述情况的。
从上面的介绍可以看出,一般情况下我们只要从头执行的程序就可以了,不需要接触底层的工具。但是搜索引擎有很多“意外”,很多的时间需要花费在维护上,所以底层的工具也是需要掌握的。我将会在下文给你演示如何运行上述过程。
本文是面向一个中型的搜索引擎的,如果做像百度这样的抓取互联网数据的引擎,你就需要参考下面的资源。
资源列表:
1、Nutch project page Nutch项目的大本营,想必大家都知道。
2、邮件列表: nutch-user 和 nutch-dev
3、在写本文的时候 Map Reduce 已经放到nutch的svn中了,不过还不是发布版本。我记得是Doug Cutting 在签入完 MapReduce 后就去度假了,呵呵。
更多资源:
Nutch tutorial还有一个好消息,写过Eclipse Plugin 的人都知道,Eclipse 架构的强大之处,Nutch 的Plugin 也是基于Eclipse 的,不过现在的版本是 2.0 。详情看这里 PluginCentral
search option
Building Nutch: Open Source Search
Nutch: A Flexible and Scalable Open Source Web Search Engine
参考文章:
http://today.java.net/pub/a/today/2006/01/10/introduction-to-nutch-1.html
http://www.firstdev.net/bbs/read.php?tid=1378&fpage=2















 5203
5203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









