







1. 设置Hadoop用户:
sudo addgroup hadoop #创建hadoop用户组
sudo adduser -ingroup hadoop hadoop #添加hadoop用户到hadoop组中
sudo gedit /etc/sudoers #为hadoop用户添加权限
在root设置权限的代码下添加一行:
hadoopALL=(ALL:ALL) ALL
2. 配置安装ssh
sudo apt-get install openssh-server #安装ssh-server
设置免密码登录localhost(本机)
ssh-keygen -t rsa -P "" #使用rsa加密算法,密码为空
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #将公钥追加到authorized_keys中,该文件保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容
测试是否可以免密码登录localhost:
ssh localhost
成功login,exit退出!
3. 安装与配置Java:
sudo apt-get install openjdk-7-jdk #安装
配置Java环境:
sudo gedit /etc/profile #编辑/etc/profile文件
在最后添加:
export JAVA_HOME=/usr/java/jdk1.7.0_04
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
更改默认配置选项:
sudo update-alternatives --install /usr/bin/Java java /usr/java/jdk1.7.0_04/bin/java 300
sudo update-alternatives --install /usr/bin/jar jar /usr/java/jdk1.7.0_04/bin/jar 300
sudo update-alternatives --install /usr/bin/javah javah /usr/java/jdk1.7.0_04/bin/javah 300
sudo update-alternatives --install /usr/bin/javap javap /usr/java/jdk1.7.0_04/bin/javap 300
source /etc/profile #立马生效
java -version #查看java版本
env | grep JAVA_HOME #查看环境中JAVA_HOME的设置值是什么
4. 安装配置Hadoop2.4.0
下载+解压hadoop2.4.0
#########################单机模式Start###########################
配置:
sudo gedit /etc/profile
添加:
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_67
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
sudo gedit /home/hadoop/etc/hadoop/hadoop-env.sh
修改JAVA_HOME变量如下:
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_67
单机模式配置OK!运行自带WordCount示例:
在hadoop下创建input文件夹,并且拷贝一个文档进去:
cd /home/hadoop
mkdir input
cp READM.txt input
执行WordCount:bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output
成功!
#########################单机模式End###########################
#######################伪分布式模式Start##########################
先前的配置步骤与上述单机模式的一样,下面进行其他的配置:
配置core-site.xml:包含了Hadoop启动时的配置信息
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置yarn-site.xml:包含了MapReduce启动时的配置信息
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
创建和配置mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置hdfs-site.xml:配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录
在hadoop下创建目录:
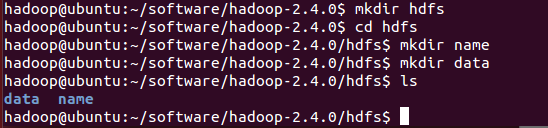
配置hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/software/hadoop-2.4.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/software/hadoop-2.4.0/hdfs/data</value>
</property>
</configuration>
格式化hdfs:
hdfs namenode -format
格式化后就可以启动hadoop:
start-dfs.sh:启动NameNode,DataNode,SecondaryNameNode
start-yarn.sh:启动NodeManager,Resourcemanager

配置OK~!
浏览器打开 http://localhost:50070/,会看到hdfs管理页面.
浏览器打开http://localhost:8088,会看到hadoop进程管理页面.
#######################伪分布式模式End##########################
5. 配置Eclipse上的hadoop插件:
下载插件hadoop.eclipse-kepler-plugin-2.2.0.jar:
http://pan.baidu.com/s/1mgqQYuc
把插件移动到eclipse的plugins目录下:
sudo mv hadoop-eclipse-kepler-plugin-2.2.0.jar /usr/local/eclipse/plugins/
重启eclpise,配置Hadoop installation directory:
打开Windows—Preferences,点击Hadoop Map/Reduce选项,设置Hadoop安装路径。
配置Map/Reduce Locations。
6. 关闭hadoop环境:
stop-dfs.sh
stop-yarn.sh
Over!















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









