







数据清洗
数据清洗主要是删除原始数据集中地无关数据、重复数据、平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。
缺失值处理的方法可分为3类:删除记录、数据插补和不处理。

删除含有缺失值的记录的方法有很大的局限性,它是以减少历史数据来换取数据的完备,会造成资源的大量浪费,将丢弃了大量隐藏在这些记录中的信息。尤其在数据集本来就包含很少记录的情况下,删除少量记录可能会严重影响到分析结果的客观性和正确性。
拉格朗日插值法


拉格朗日插值公式结构紧凑,在理论分析中很方便,但是当插值节点增减时,插值多项式就会随之变化,导致拉格朗日插值必须重新计算,而牛顿插值法可以避免这一点。
Python代码实现
# -*- coding: utf-8 -*-
from scipy.interpolate import lagrange
x = [3, 6, 9]
y = [10, 8, 4]
print( lagrange(x, y) )结果:

解释:

lagrange(x, y)(10)表示进行插值,插值自变量为10,输出插值结果为2.22……
即,lagrange(x, y)中两个参数:把一系列点当成是函数关系 y = f(x),输出结果为根据函数f求出的对应的y值。
Python代码实现
首先从原始数据集中确定因变量和自变量,取出缺失值前后5个数据(前后数据中遇到数据不存在或者为空的,直接将数据舍去,将仅有的数据组成一组),根据取出来的10个数据组成一组,然后采用拉格朗日多项式插值公式:
# -*- coding: utf-8 -*-
"""
拉格朗日插值代码
"""
import pandas as pd #导入数据分析库
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = './missing_data.xls' #输入数据路径,需要使用Excel格式
outputfile = './missing_data_processed.xls' #输出数据路径,需要使用Excel格式
#header表示数据中是否存在列名,如果在第0行就写0,并且开始读数据时跳过相应的行数,不存在可以写None
data = pd.read_excel(inputfile, header = None)
#自定义列向量插值函数
#s为列向量,n为被插值的位置,K为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数,转换成列表
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果,n是被插值的位置
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile, header = None, index = False) #输出结果缺值的数据文件:
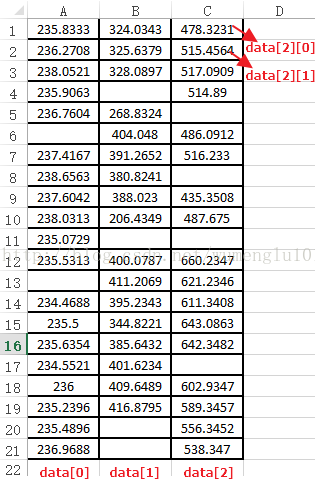
代码执行后的结果文件(红框圈出插值的数据):
















 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









