




 本文介绍了如何使用Python的Difflib模块进行API返回内容的对比以及文本差异分析。通过SequenceMatcher类进行序列匹配,忽略特定元素,计算相似度;使用Differ类找出文本中的不同行;并利用HtmlDiff生成友好的HTML差异展示。这些工具在技术升级和测试中非常实用。
本文介绍了如何使用Python的Difflib模块进行API返回内容的对比以及文本差异分析。通过SequenceMatcher类进行序列匹配,忽略特定元素,计算相似度;使用Differ类找出文本中的不同行;并利用HtmlDiff生成友好的HTML差异展示。这些工具在技术升级和测试中非常实用。
背景:
最近项目中有需要技术升级,开发新的 API 替换原来的老的API,其功能不变,只是换了一种新方式实现。为了保准新接口的功能,测试过程中要将新 API 返回和原来的 API 返回做对比。有必要写一个 content compare tool,Python 就是一个很好的开发工具的利器。
Difflib:
Difflib 是 Python 的标准库模块,无需安装。作用时对比序列文本集之间的差异,并且支持输出可读性比较强的 HTML 文档。详情可以参考官网 Difflib ,下面会介绍几个常用的比较类。
class difflib.SequenceMatcher
比较两个给定的的字符串,找出相同的部分。
下面引用来自coderzcolumn python 教程中
SequenceMatcher(isjunk=None,a=‘’, b=‘’, autojunk=True) - It accepts two sequences and returns an instance of SequenceMatcher which can be used to find common subsequences.
isjunk - This parameteraccepts a functionthat takes as input a single element of the sequence and returns True if it junk else False. We can provide function if we want junk elements by ourselves. The default is None.
autojunk - This parameter accepts boolean value. If set to True, it enables auto junk finding functionality of the algorithm which we described in the introduction section. We can disable it by setting this parameter to False. The default is True.
举例:传入 isjunk 函数(忽略字符串中’,‘和’.'的比较)和默认 None 的情况
import difflib
from difflib import SequenceMatcher
l1 = "Hello, Welcome to CoderzColumn."
l2 = "Welcome to CoderzColumn, Have a Great Learning Day."
seq_mat_with_junk = SequenceMatcher(isjunk=lambda x: x in [",", "."], a=l1, b=l2, autojunk=True)
seq_mat_without_junk = SequenceMatcher(a=l1, b=l2, autojunk=True)
print("similarity with junk:{}".format(seq_mat_with_junk.ratio()))
print("similarity without junk:{}".format(seq_mat_without_junk.ratio()))
# output
similarity with junk:0.5609756097560976
similarity without junk:0.5853658536585366
class difflib.Differ
跟SequenceMatcher相反,是找出文本多行中的不同部分。
Differ(linejunk=None, charjunk=None)
linejunk,charjunk 参数为一个 function,忽略哪些行或则字符的比较。
4种行输出特征符号
| Code | Meaning |
|---|---|
| '- ’ | line unique to sequence 1 |
| '+ ’ | line unique to sequence 2 |
| ’ ’ | line common to both sequences |
| '? ’ | line not present in either input sequence |
举例:比较两字符串的不同
import difflib
from difflib import Differ
str1 = "I would like to order a pepperoni pizza.\n And you?"
str2 = "I would like to order a veggie burger.\n And you?"
str1_lines = str1.splitlines()
str2_lines = str2.splitlines()
d = difflib.Differ()
diff = d.compare(str1_lines, str2_lines)
for lines in diff:
print(lines)
output:
- I would like to order a pepperoni pizza.
+ I would like to order a veggie burger.
And you?
举例:比较文件内容的不同
import difflib
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.Differ(charjunk=lambda x: x in [",", ".", "-", "'"])
for line in difference.compare(a, b):
print(line, end="")
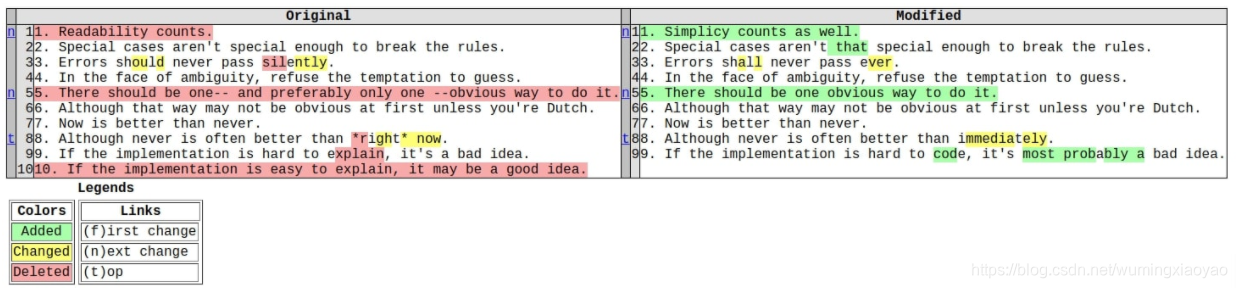
class difflib.HtmlDiff
以 html 格式更友好地显示不同部分
创建 HtmlDiff 实例
HtmlDiff(tabsize=8,wrapcolumn=None,linejunk=None,charjunk=IS_CHARACTER_JUNK)
tabsizeis an optional keyword argument to specify tab stop spacing and defaults to 8.
wrapcolumnis an optional keyword to specify column number where lines are broken and wrapped, defaults to None where lines are not wrapped.
比较方法,下面两个效果是一样的,都是返回 String,只是返回一个是 html file string, 一个是 html talbe sting
make_file(fromlines, tolines, fromdesc=‘’, todesc=‘’, context=False, numlines=5, *, charset=‘utf-8’)
make_table(fromlines, tolines, fromdesc=‘’, todesc=‘’, context=False, numlines=5)
fromdesc and todescare optional keyword arguments to specify from/to file column header strings (both default to an empty string).
context and numlinesare both optional keyword arguments. Set context to True when contextual differences are to be shown, else the default is False to show the full files. numlines defaults to 5. When context is True numlines controls the number of context lines which surround the difference highlights. When context is False numlines controls the number of lines which are shown before a difference highlight when using the “next” hyperlinks (setting to zero would cause the “next” hyperlinks to place the next difference highlight at the top of the browser without any leading context).
fromdesc 和 todesc 是显示 html 结果时头部信息用来标记区别版本。
context 为 Ture 只显示不同部分,False 是显示全部
numlines 是设置前面 Diff 部分间隔的行数。
举例:
import difflib
from IPython import display
a = open("original.txt", "r").readlines()
b = open("modified.txt", "r").readlines()
difference = difflib.HtmlDiff(tabsize=2)
with open("compare.html", "w") as fp:
html = difference.make_file(fromlines=a, tolines=b, fromdesc="Original", todesc="Modified")
fp.write(html)
display.HTML(open("compare.html", "r").read())
输出:

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









