







(内容仅供技术探讨,切勿用于商业用途)
好久没有去电影院看电影了,新上映的电影因为版权原因看不了,老电影又不知道看什么,好难啊。。。不如我们看看榜单上都有啥好电影推荐吧,这次就对某瓣电影下手吧
一、开发环境
IDE:Pycharm
Python 3.7 (三方库:requests、lxml)
二、网站分析调研
1、目标网站
aHR0cHM6Ly9tb3ZpZS5kb3ViYW4uY29tL3RvcDI1MD9zdGFydD0wJmZpbHRlcj0=
2、分析流程
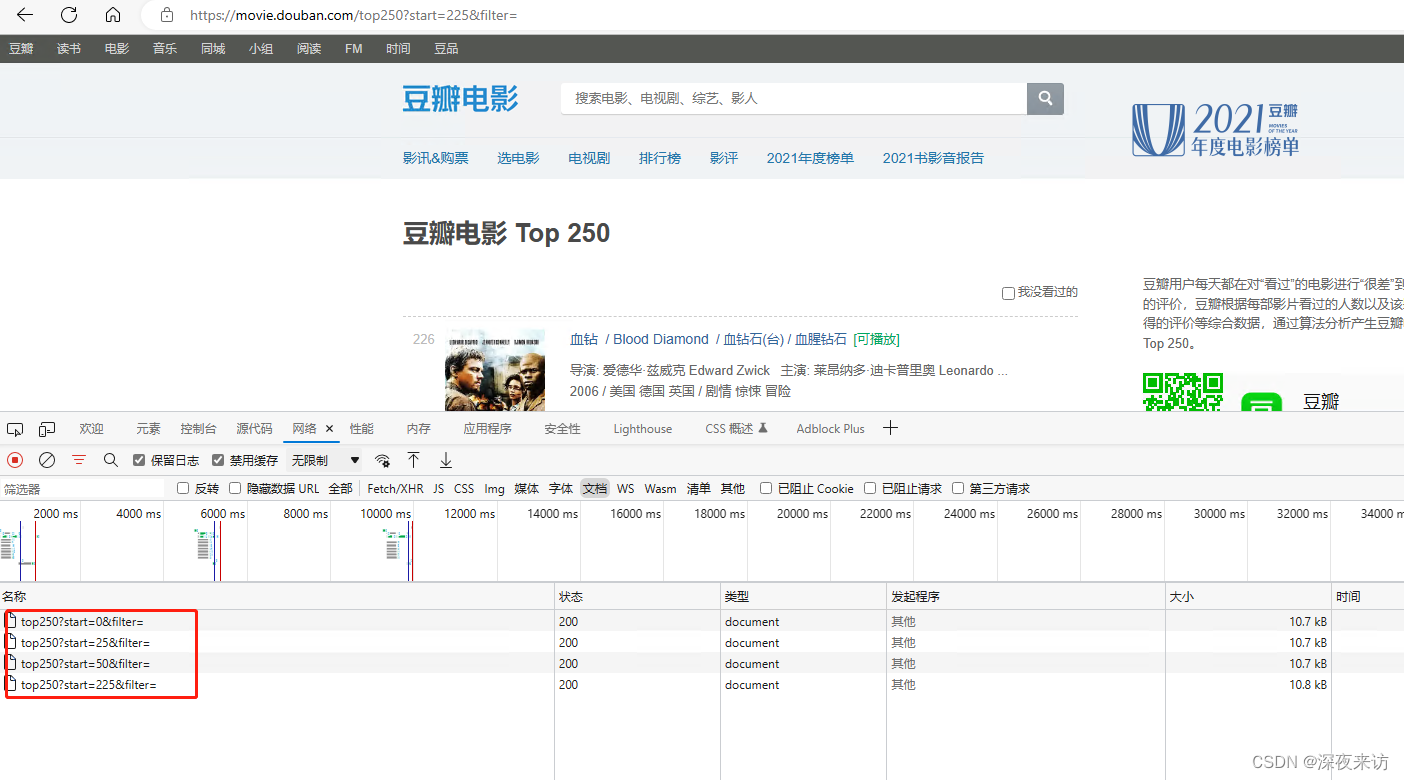
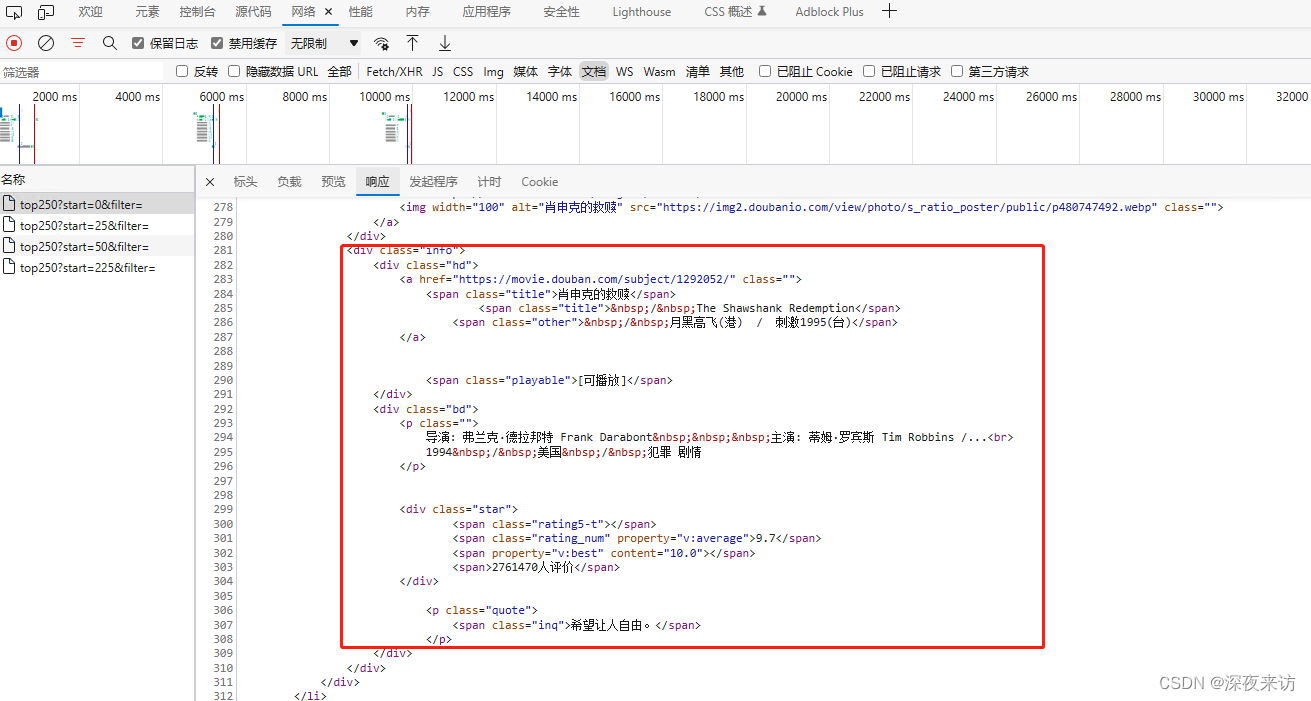
通过查看不同页面,不难发现,每一页的链接,只有一个start参数再变,并且值始终是25的倍数。也就是说,这的参数代表的是电影索引的起始值。
分析后我们不难得出结论,此电影列表,每页25条数据,start从0开始,共计10页,start每页递增25;并且每部电影的数据都在class属性为info的div标签中。
至此,我们需要的所有链接及所需提取数据的位置都已确定,接下来遍可以开始开发我们的程序了。
三、程序开发
1、生成全部链接
本次提取的数据,一共10页,根据起始索引值进行翻页操作。代码如下
def generate_url():
"""
链接生成器
"""
for i in range(25):
url = f"https://movie.douban.com/top250?start={25*i}&filter="
yield url2、请求并解析数据
def process_page(url):
"""
获取并解析指定页面信息
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54"
}
response = requests.get(url, headers=headers)
response.encoding = "UTF-8"
html = etree.HTML(response.text)
results = []
movieList = html.xpath('//div[@class="info"]')
for ch in movieList:
item = dict()
# 标题
item['title'] = ch.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
# 副标题
item['otherTitle'] = ch.xpath('div[@class="hd"]/a/span[@class="other"]/text()')[0].strip("/\xa0")
# url
item['url'] = ch.xpath('div[@class="hd"]/a/@href')[0] # url
# 评分
item['star'] = ch.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0]
# 引言(名句)
item['quote'] = ch.xpath('div[@class="bd"]/p[@class="quote"]/span/text()')[0] if ch.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') else ""
results.append(item)
print(item)
return results3、保存数据至CSV
需要注意的一点是,我们保存数据是多次保存,所以只需要在第一次保存是写入表头,之后保存则无需再此写入表头
def save_results(results):
"""
保存数据
"""
if not os.path.exists('douban.csv'):
with open('douban.csv', 'a+', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'otherTitle', 'star', 'quote', 'url'])
writer.writeheader() # 写入表头
for ch in results:
writer.writerow(ch)
else:
with open('douban.csv', 'a+', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'otherTitle', 'star', 'quote', 'url'])
for ch in results:
writer.writerow(ch)四、程序运行
我们将上边的几个方法整合起来,运行下看看效果
import csv
import os
from lxml import etree
import requests
class DoubanSpider(object):
@staticmethod
def generate_url():
"""
链接生成器
"""
for i in range(25):
url = f"https://movie.douban.com/top250?start={25*i}&filter="
yield url
@staticmethod
def process_page(url):
"""
获取并解析指定页面信息
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54"
}
response = requests.get(url, headers=headers)
response.encoding = "UTF-8"
html = etree.HTML(response.text)
results = []
movieList = html.xpath('//div[@class="info"]')
for ch in movieList:
item = dict()
# 标题
item['title'] = ch.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
# 副标题
item['otherTitle'] = ch.xpath('div[@class="hd"]/a/span[@class="other"]/text()')[0].strip("/\xa0")
# url
item['url'] = ch.xpath('div[@class="hd"]/a/@href')[0] # url
# 评分
item['star'] = ch.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0]
# 引言(名句)
item['quote'] = ch.xpath('div[@class="bd"]/p[@class="quote"]/span/text()')[0] if ch.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') else ""
results.append(item)
print(item)
return results
@staticmethod
def save_results(results):
"""
保存数据
"""
if not os.path.exists('douban.csv'):
with open('douban.csv', 'a+', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'otherTitle', 'star', 'quote', 'url'])
writer.writeheader() # 写入表头
for ch in results:
writer.writerow(ch)
else:
with open('douban.csv', 'a+', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'otherTitle', 'star', 'quote', 'url'])
for ch in results:
writer.writerow(ch)
def run(self):
"""
启动
"""
for url in self.generate_url():
results = self.process_page(url)
self.save_results(results)
if __name__ == '__main__':
spider = DoubanSpider()
spider.run()

可以看到,运行结果符合我们预期。
还在等什么,还不赶紧动手试试~~















 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









