// T is the type of the object in the queue.队列中元素的类型
// N is granularity(粒度) of the queue,简单来说就是yqueue_t一个结点可以装载N个T类型的元素,可以猜想yqueue_t的一个结点应该是个数组
template <typename T, int N> class yqueue_t
{
public:
inline yqueue_t ();// Create the queue.
inline ~yqueue_t ();// Destroy the queue.
inline T &front ();// Returns reference to the front element of the queue. If the queue is empty, behaviour is undefined.
inline T &back ();// Returns reference to the back element of the queue.If the queue is empty, behaviour is undefined.
inline void push ();// Adds an element to the back end of the queue.
inline void pop ();// Removes an element from the front of the queue.
inline void unpush ()// 用于回滚操作,暂时先不管这个函数,用到再说
private:
// Individual memory chunk to hold N elements.
struct chunk_t
{
T values [N];
chunk_t *prev;
chunk_t *next;
};
// This class encapsulates several atomic operations on pointers.
template <typename T> class atomic_ptr_t
{
public:
inline void set (T *ptr_);//非原子操作
inline T *xchg (T *val_);//原子操作
inline T *cas (T *cmp_, T *val_);//原子操作
private:
volatile T *ptr;
}
// Removes an element from the front end of the queue.
inline void pop ()
{
if (++ begin_pos == N) {
chunk_t *o = begin_chunk;
begin_chunk = begin_chunk->next;
begin_chunk->prev = NULL;
begin_pos = 0;
</span><span style="color: #008000;">//</span><span style="color: #008000;"> 'o' has been more recently used than spare_chunk,
</span><span style="color: #008000;">//</span><span style="color: #008000;"> so for cache reasons we'll get rid of the spare and
</span><span style="color: #008000;">//</span><span style="color: #008000;"> use 'o' as the spare.</span>
chunk_t *cs =<span style="color: #000000;"> spare_chunk.xchg (o);<strong><span style="color: #3366ff;">//由于局部性原理,总是保存最新的空闲块而释放先前的空闲快
</span></strong></span><span style="color: #0000ff;">free</span><span style="color: #000000;"> (cs);
}
}</span></pre>
// Returns reference to the front element of the queue.
// If the queue is empty, behaviour is undefined.
inline T &front ()
{
return begin_chunk->values [begin_pos];
}
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Returns reference to the back element of the queue.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> If the queue is empty, behaviour is undefined.</span>
inline T &<span style="color: #000000;">back ()
{
</span><span style="color: #0000ff;">return</span> back_chunk-><span style="color: #000000;">values [back_pos];
}</span></pre>
总的来说yqueue_t还是比较好理解,现在可以来看一看ypipe_t的实现。
2、ypipe_t
先看下ypipe_t的介绍(注释)、类继承关系、类接口及数据成员
// Lock-free queue implementation.
// Only a single thread can read from the pipe at any specific moment.
// Only a single thread can write to the pipe at any specific moment.
// T is the type of the object in the queue.
// N is granularity of the pipe, i.e. how many items are needed to
// perform next memory allocation.
template <typename T, int N> class ypipe_t : public ypipe_base_t<T,N>
template </span><typename T, <span style="color: #0000ff;">int</span> N> <span style="color: #0000ff;">class</span><span style="color: #000000;"><strong><span style="color: #ff00ff;"> ypipe_base_t</span></strong>
{
</span><span style="color: #0000ff;">public</span><span style="color: #000000;">:
</span><span style="color: #0000ff;">virtual</span> ~<span style="color: #000000;">ypipe_base_t () {}
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">void</span> write (<span style="color: #0000ff;">const</span> T &value_, <span style="color: #0000ff;">bool</span> incomplete_) = <span style="color: #800080;">0</span><span style="color: #000000;">;
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">bool</span> unwrite (T *value_) = <span style="color: #800080;">0</span><span style="color: #000000;">;
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">bool</span> flush () = <span style="color: #800080;">0</span><span style="color: #000000;">;
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">bool</span> check_read () = <span style="color: #800080;">0</span><span style="color: #000000;">;
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">bool</span> read (T *value_) = <span style="color: #800080;">0</span><span style="color: #000000;">;
</span><span style="color: #0000ff;">virtual</span> <span style="color: #0000ff;">bool</span> probe (<span style="color: #0000ff;">bool</span> (*fn)(T &)) = <span style="color: #800080;">0</span><span style="color: #000000;">;
};
template </span><typename T, <span style="color: #0000ff;">int</span> N> <span style="color: #0000ff;">class</span> <strong><span style="color: #ff0000;">ypipe_t</span> </strong>: <span style="color: #0000ff;">public</span> <strong><span style="color: #ff00ff;">ypipe_base_t</span></strong><T,N><span style="color: #000000;">
{
</span><span style="color: #0000ff;">protected</span><span style="color: #000000;">:
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Allocation-efficient queue to store pipe items.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Front of the queue points to the first prefetched item, back of the pipe points to last un-flushed item.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Front is used only by reader thread, while back is used only by writer thread.</span>
yqueue_t <T, N><span style="color: #000000;"> queue;<span style="color: #339966;">//底层容器
</span></span><span style="color: #008000;">//</span><span style="color: #008000;"> Points to the first un-flushed item. This variable is used exclusively by writer thread.</span>
T *w;<span style="color: #0000ff;"><strong>//指向第一个未刷新的元素,只被写线程使用
</strong></span><span style="color: #008000;">//</span><span style="color: #008000;"> Points to the first un-prefetched item. This variable is used exclusively by reader thread.</span>
T *r;<span style="color: #0000ff;"><strong>//指向第一个还没预提取的元素,只被读线程使用
</strong></span><span style="color: #008000;">//</span><span style="color: #008000;"> Points to the first item to be flushed in the future.</span>
T *f;<span style="color: #0000ff;"><strong>//指向下一轮要被刷新的一批元素中的第一个
</strong></span><span style="color: #008000;">//</span><span style="color: #008000;"> The single point of contention between writer and reader thread.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Points past the last flushed item. If it is NULL,reader is asleep.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> This pointer should be always accessed using atomic operations.</span>
atomic_ptr_t <T> c;<span style="color: #0000ff;"><strong>//读写线程共享的指针,指向每一轮刷新的起点(看代码的时候会详细说)。当c为空时,表示读线程睡眠(只会在读线程中被设置为空)</strong></span>
// Initialises the pipe.
inline ypipe_t ()
{
// Insert terminator element into the queue.
queue.push ();//yqueue_t的尾指针加1,开始back_chunk为空,现在back_chunk指向第一个chunk_t块的第一个位置
</strong></span></span><span style="color: #008000;">//</span><span style="color: #008000;"> Let all the pointers to point to the terminator.</span>
r = w = f = &<span style="color: #000000;">queue.back ();
c.</span><span style="color: #0000ff;">set</span> (&<span style="color: #000000;">queue.back ());
}
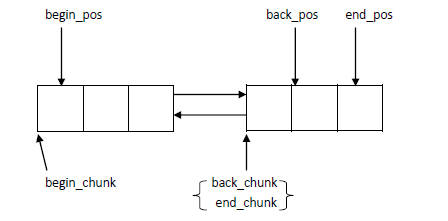
在ypipe_t中,back_chunk+back_pos类似vector的end迭代器,上面的注释"Let all the pointers to point to the terminator."也是这个意思,就是让r、w、f、c四个指针都指向这个end迭代器,有关这点在write的时候能看清晰的感受到。那么做完这一步,他们关系像下面这个样子:
inline void write (const T &value_, bool incomplete_)
{
// Place the value to the queue, add new terminator element.
queue.back () = value_;
queue.push ();
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Move the "flush up to here" poiter.</span>
<span style="color: #0000ff;">if</span> (!<span style="color: #000000;">incomplete_)
f </span>= &<span style="color: #000000;">queue.back ();
inline bool flush ()
{
// If there are no un-flushed items, do nothing.
if (w == f)
return true;
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Try to set 'c' to 'f'.</span>
<span style="color: #0000ff;">if</span> (c.cas (w, f) !=<span style="color: #000000;"> w) {
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Compare-and-swap was unseccessful because 'c' is NULL.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> This means that the reader is asleep. Therefore we don't care about thread-safeness and update c in non-atomic manner.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> We'll return false to let the caller know that reader is sleeping.</span>
c.<span style="color: #0000ff;">set</span><span style="color: #000000;"> (f);
w </span>=<span style="color: #000000;"> f;
</span><span style="color: #0000ff;">return</span> <span style="color: #0000ff;">false</span><span style="color: #000000;">;
}
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Reader is alive. Nothing special to do now. Just move the 'first un-flushed item' pointer to 'f'.</span>
w =<span style="color: #000000;"> f;
</span><span style="color: #0000ff;">return</span> <span style="color: #0000ff;">true</span><span style="color: #000000;">;
}
可以看到w==f 时,flush是直接返回的,什么也没做,而当write函数的incomplete_=false时,把 f 指向了新的结点,这个时候 w!=f 了,flush函数才有所作为,所以w、f指针合作可用来告知flush函数现在能否刷新。
// Reads an item from the pipe. Returns false if there is no value available.
inline bool read (T *value_)
{
// Try to prefetch a value.
if (!check_read ())
return false;
</span><span style="color: #008000;">//</span><span style="color: #008000;"> There was at least one value prefetched.Return it to the caller.</span>
*value_ =<span style="color: #000000;"> queue.front ();
queue.pop ();
</span><span style="color: #0000ff;">return</span> <span style="color: #0000ff;">true</span><span style="color: #000000;">;
// Check whether item is available for reading.
inline bool check_read ()
{
// Was the value prefetched already? If so, return.
if (&queue.front () != r && r)//判断是否在前几次调用read函数时已经预取数据了return true;
</span><span style="color: #008000;">//</span><span style="color: #008000;"> There's no prefetched value, so let us prefetch more values.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> Prefetching is to simply retrieve the </span><span style="color: #008000;">pointer from c in atomic fashion.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> If there are no items to prefetch, set c to NULL (using compare-and-swap).</span>
r = c.cas (&<span style="color: #000000;">queue.front (), NULL);<span style="color: #0000ff;"><strong>//尝试预取数据
</strong></span></span><span style="color: #008000;">//</span><span style="color: #008000;"> If there are no elements prefetched, exit.
</span><span style="color: #008000;">//</span><span style="color: #008000;"> During pipe's lifetime r should never be NULL, however,</span><span style="color: #008000;">it can happen during pipe shutdown when items </span><span style="color: #008000;">are being deallocated.</span>
<span style="color: #0000ff;">if</span> (&queue.front () == r || !<span style="color: #000000;">r)<strong><span style="color: #0000ff;">//判断是否成功预取数据
</span></strong></span><span style="color: #0000ff;">return</span> <span style="color: #0000ff;">false</span><span style="color: #000000;">;
</span><span style="color: #008000;">//</span><span style="color: #008000;"> There was at least one value prefetched.</span>
<span style="color: #0000ff;">return</span> <span style="color: #0000ff;">true</span><span style="color: #000000;">;






























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









