







zmq内存分配
文件
\libzmq\src\yqueue.hpp
如何节省内存分配开销
怎么优化内存分配,先了解以下内存分配开销流程,分配内存这个操作,在c++使用new,delete关键字,c中使用malloc, free组合关键组,通过传入大小来申请一段连续的内存,当然这里的连续指的是逻辑连续,在物理上不一定是连续的,但是操作系统会帮我们屏蔽掉这些细节,分配给我们一块内存.
所以可以得出内存分配行为是需要一些消耗的.
所以,通常的内存分配优化方案为为,先分配一块大内存,再通过自己维护内存使用来进行内存的优化,zmq大致也是这么做的
zmq内存使用方案
struct chunk_t
{
T values[N];
chunk_t *prev;
chunk_t *next;
};
以chunk_t结构作为基本单元,来进行一组数据的存储,单从结构可以看出,这是典型的链表结构,prev指向前一个chunk,next指向后一个chunk,数组存放单一的结构元素
chunk_t *_begin_chunk;
int _begin_pos;
chunk_t *_back_chunk;
int _back_pos;
chunk_t *_end_chunk;
int _end_pos;
_begin_chunk 控制第一个chunk上插入
_begin_pos 表示chunk从哪一个下标开始储存
_back_chunk 表示当前可以存放的chunk
_back_chunk 表示当前可以存放的下标
_end_chunk 表示下一个下标可以存放的chunk
_end_chunk 表示下一个可以存放的下标
初始化
将所有代码中属性置零
inline yqueue_t ()
{
_begin_chunk = allocate_chunk ();
alloc_assert (_begin_chunk);
_begin_pos = 0;
_back_chunk = NULL;
_back_pos = 0;
_end_chunk = _begin_chunk;
_end_pos = 0;
}
插入元素 push ()
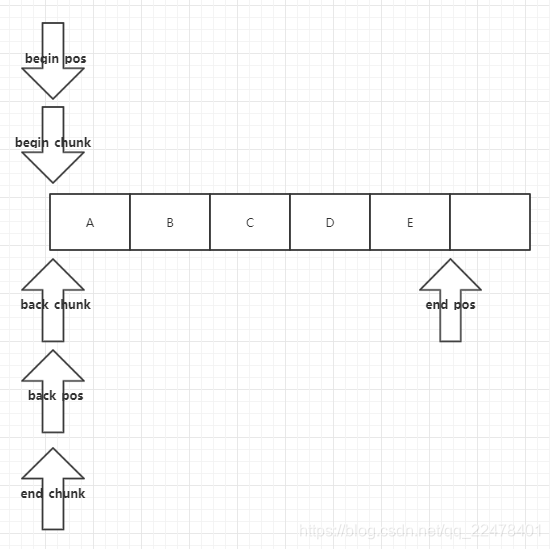
如果当前chunk元素够用时,在数组中插入元素, 移动end_pos.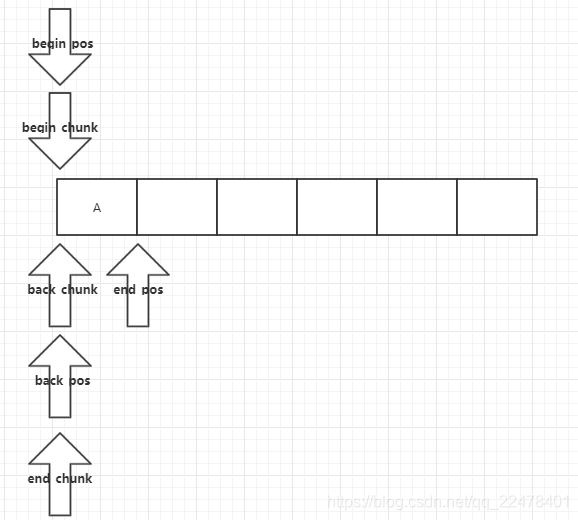
当当前end_pos等于当前chunk元素最大值时,会进行新chunk的创建添加,
chunk_t *sc = _spare_chunk.xchg (NULL);
if (sc) {
_end_chunk->next = sc;
sc->prev = _end_chunk;
} else {
_end_chunk->next = allocate_chunk ();
alloc_assert (_end_chunk->next);
_end_chunk->next->prev = _end_chunk;
}
_end_chunk = _end_chunk->next;
_end_pos = 0;
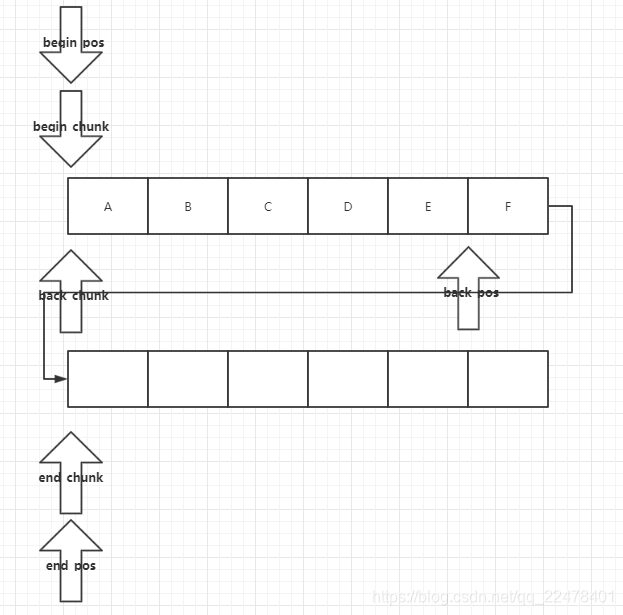
再插入一个元素后 back_chunk和back_pos也会进行相应的移动
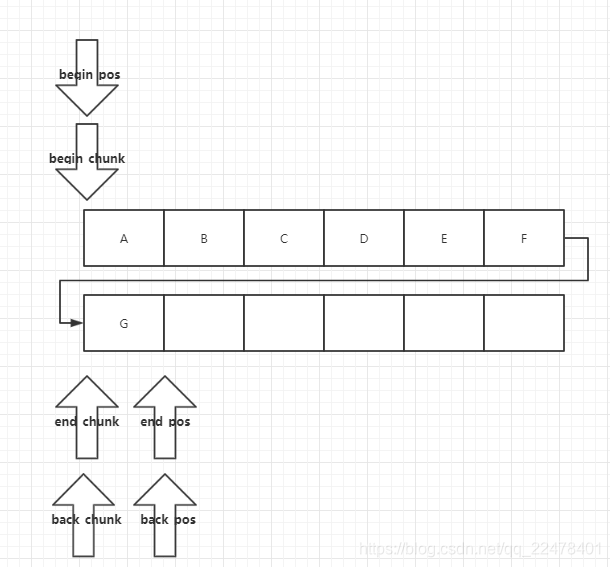
拿出元素 pop()
移动begin_pos即完成了元素的获取
inline void pop ()
{
//如果所有对象都弹出,则销毁当前chunk
if (++_begin_pos == N) {
```
}
}
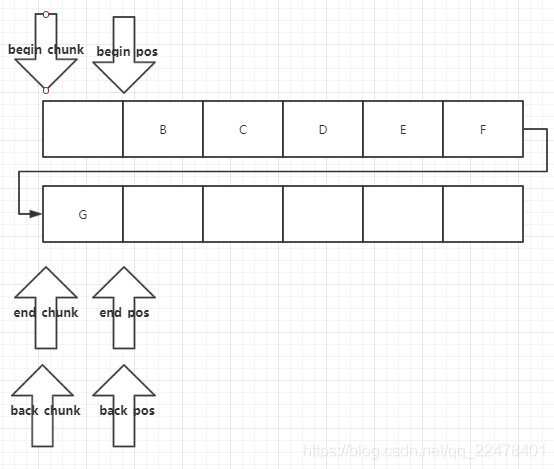
当然当begin_pos到数组最后一个元素时,也需要做整体chunk的操作
inline void pop ()
{
//如果所有对象都弹出,则销毁当前chunk
if (++_begin_pos == N) {
chunk_t *o = _begin_chunk;
_begin_chunk = _begin_chunk->next;
_begin_chunk->prev = NULL;
_begin_pos = 0;
// 对当前chunk和备用chunk指针进行交换,删除备用那个
chunk_t *cs = _spare_chunk.xchg (o);
free (cs);
}
}
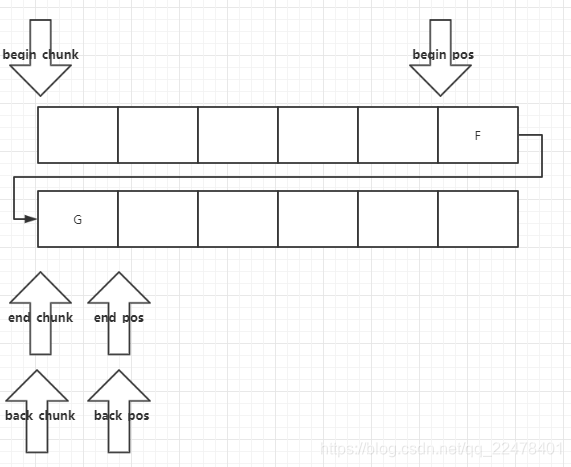
重点来了
在当前pop到最后一个chunk时,begin_pos和begin_chunk指向了下一个chunk,而当前chunk并不直接销毁,而是放入
atomic_ptr_t<chunk_t> _spare_chunk;
当然如果原来就有_spare_chunk就有,则再删除.
结构中,在下次push操作需要分配chunk 时,优先使用_spare_chunk , 减少分配操作
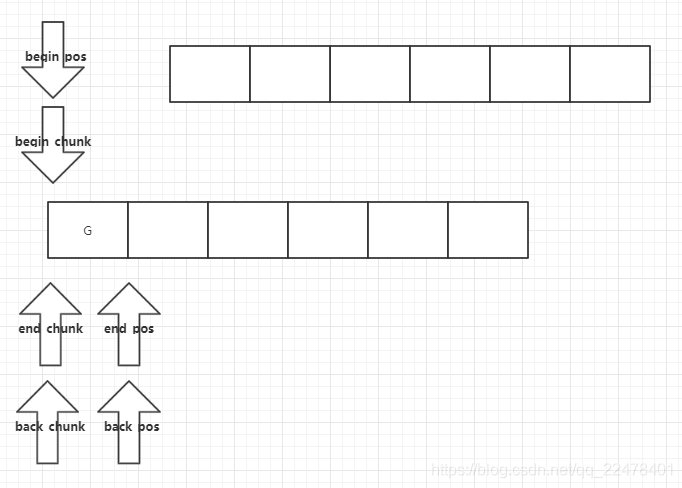
yqueue用于mailbox中,也是命令队列,遵守先进先出规则,以消费者生产者模型来进行描述,当生产和消费持平时,不会发生内存分配,chunk会被循环利用.














 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









