







什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做
爬虫的更多用途
12306抢票
网站上的投票
短信轰炸
注册页面1
注册页面2
注册页面3
爬虫的分类
1.根据被爬网站的数量的不同,我们把爬虫分为:
通用爬虫 :通常指搜索引擎的爬虫,例如(https://www.baidu.com)百度、360、搜狐、谷歌、必应.......
通用爬虫的原理:
1)抓取网页
2)采集数据
3)数据处理
4)提供检索服务
通用爬虫如何抓取新网站?
1)主动提交url
2)设置友情链接
3)百度会和DNS服务商合作,抓取新网站
如果不想让百度爬虫你的网站:加一个文件robots.txt,可以限定哪些可以爬取我的网站,哪些不可以,例如淘宝的部分robots.txt内
这个协议仅仅是口头上的协议,真正的还是可以爬取的。
聚焦爬虫 :针对特定网站的爬虫
思路:代替浏览器上网
网页的特点:
(1)网页都有自己唯一的url
(2)网页内容都是HTML结构的
(3)使用的都是http,https协议
(1)给一个url
(2)写程序,模拟浏览器访问url
(3)解析内容,提取数据
2.爬虫的流程
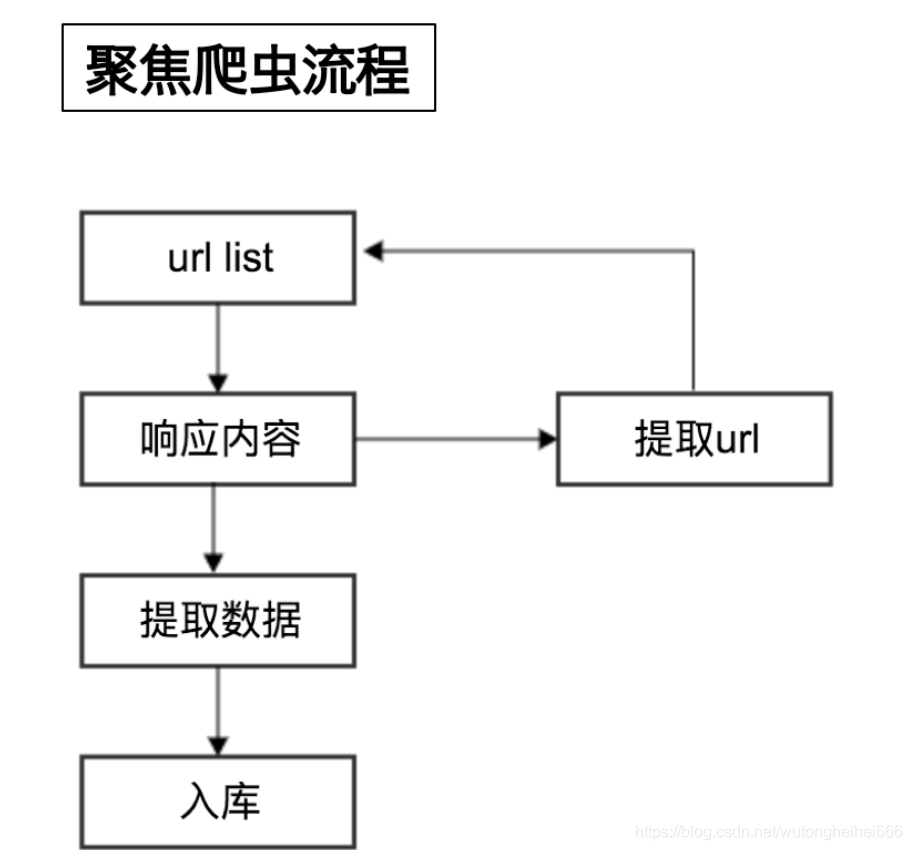
向起始url发送请求,并获取响应
对响应进行提取
如果提取url,则继续发送请求获取响应
如果提取数据,则将数据进行保存
3.robots协议
在百度搜索中,不能搜索到淘宝网中某一个具体的商品的详情页面,这就是robots协议在起作用
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
HTTP和HTTPS
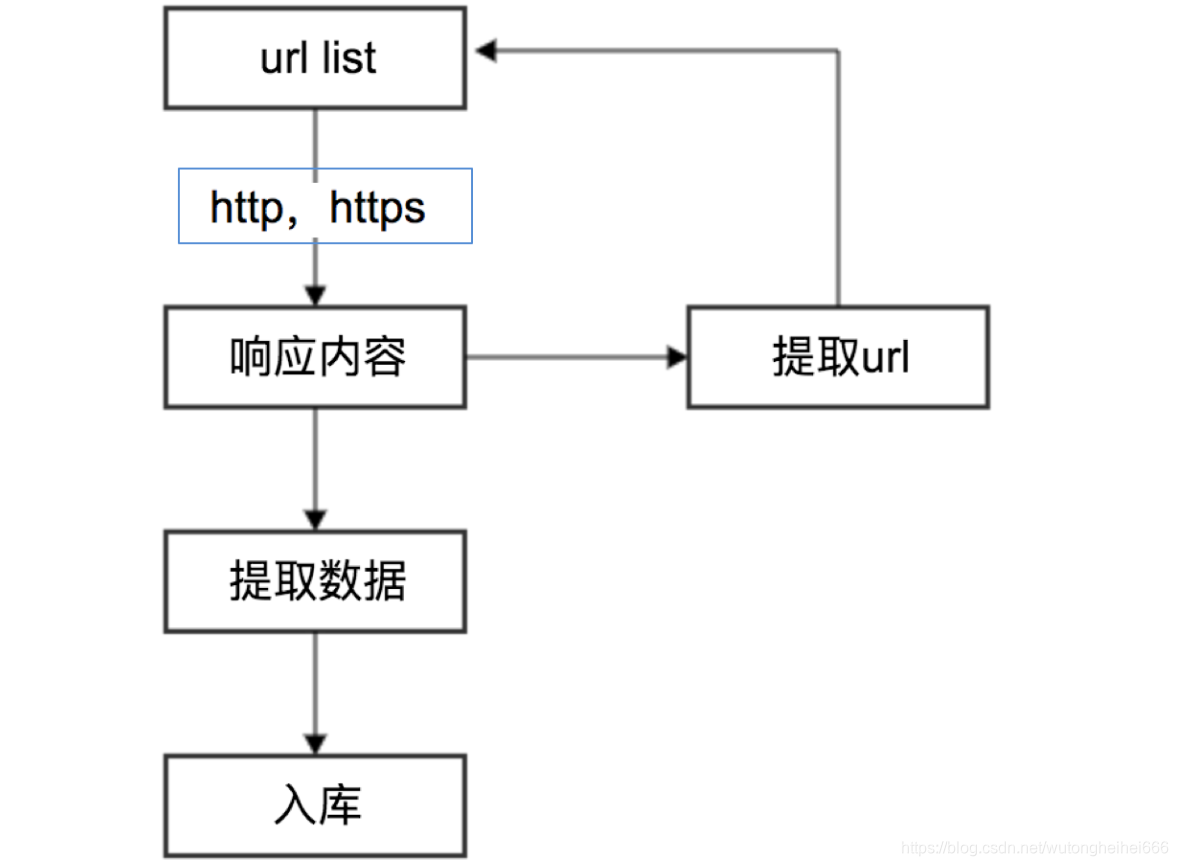
1.在发送请求,获取响应的过程中 就是发送http或https的请求,获取http或https的响应
2. http和https的概念
HTTP
超文本传输协议
默认端口号:80
HTTPS
HTTP +SSL(安全套接字层),即带有安全套接字层的超文本传输协议
默认端口号:443
HTTPS比HTTP更安全 ,但是性能更低
HTTP常见请求头
Host (主机和端口号)
Connection (链接类型)
Upgrade-Insecure-Requests (升级为HTTPS请求)
User-Agent (浏览器名称)
Accept (传输文件类型)
Referer (页面跳转处)
Accept-Encoding(文件编解码格式)
Cookie (Cookie)
x-requested-with :XMLHttpRequest (表示该请求是Ajax异步请求)
HTTP重要的响应头
Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
响应状态码(status code)
00:成功
302:临时转移至新的url(一般会用GET,例如原本是POST则新的请求则是GET)
307:临时转移至新的url(原本是POST则新的请求依然是POST)
404:找不到该页面
500:服务器内部错误
503:服务不可用,一般是被反爬
字符串相关
str,bytes以及互相转换:
str 使用encode方法转化为 bytes
bytes 通过decode转化为 str
字符集编码类型(ASCII,unicode,UTF-8):
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等
字符集(Character set)由字符构成,是多个字符的集合,如:ASCII字符集、GB2312字符集、GB18030字符集、Unicode字符集等
requests的使用
1.为什么是requests模块
requests简单易用
requests能够自动帮助我们解压(gzip压缩的等)响应内容
requests的底层实现就是urllib
requests在python2 和python3中通用,方法完全一样
2.requests的作用
作用:发送网络请求,返回响应数据
3.requests模块发送简单的get请求、获取响应
import requests
#目标url
url = 'https://www.baidu.com'
#向目标url发送get请求
response = requests.get(url)
#打印响应内容
print(response.text)
3.1response的常用属性:
response.text 响应体 str类型
respones.content 响应体 bytes类型
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request.cookies 响应对应请求的cookie
response.cookies 响应的cookie(经过了set-cookie动作)
3.2 response.text 和response.content的区别
response.text
类型:str
解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding=”gbk”
response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde(“utf8”)
获取网页源码的通用方式:
response.content.decode()
response.content.decode("GBK")
response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
4.发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content)
# 打印响应对应请求的请求头信息
print(response.request.headers)
4.1为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
4.2 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
4.3用法
requests.get(url, headers=headers)
4.4完整代码
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
# print(response.content)
# 打印请求头信息
print(response.request.headers)
5.发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个 ?,那么该问号后边的就是请求参数,又叫做查询字符串
5.1 什么叫做请求参数:
例1:https://www.baidu.com/s?wd=python&a=c
5.2 请求参数的形式:字典
kw = {'wd':'长城'}
5.3 请求参数的用法
requests.get(url,params=kw)
5.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
5.5 两种方式:发送带参数的请求
对https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式
#方式一:利用params参数发送带参数的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
# 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?wd=python&a=c'-->{'wd': 'python', 'a': 'c'}
print(response.content)
也可以直接对https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数
# 方式二:直接发送带参数的url的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
# kw = {'wd': 'python'}
# url中包含了请求参数,所以此时无需params
response = requests.get(url, headers=headers)
request发送POST请求
1.哪些地方我们会用到POST请求?
登录注册( POST 比 GET 更安全)
需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方会去模拟浏览器发送post请求
2.requests发送post请求语法:
response = requests.post("http://www.baidu.com/", data=data, headers=headers)
data 的形式:字典
总结:
在模拟登陆等场景,经常需要发送post请求,直接使用requests.post(url,data)即可
requests处理cookie
1.引入
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie相关的请求
2.爬虫中使用cookie的利弊
带上cookie的好处
能够访问登录后的页面
能够实现部分反反爬
带上cookie的坏处
一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
那么上面的问题如何解决 ?使用多个账号
3.requests处理cookie的方法
#使用requests处理cookie有3种方法:
cookie字符串放在headers中
把cookie字典传给请求方法的cookies参数接收
使用requests提 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2675
2675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









