









在学习python网络数据采集一书中,学习到11章——图片处理时,作者介绍了tesseract-ocr光学文字识别这一内容,随后在安装该工具的过程中遇到了很多的问题,在这里将其全部罗列出来,供读者参考。
1.安装tesseract
tesseract不是python的库文件,因此需要从网上下载安装,安装文件下载请点这里,进入网页后,根据需要选择高亮的蓝色字体进行下载,下载后按默认安装即可。
2.配置tesseract的环境变量
tesseract实际上是在windows命令行模式下使用的工具,因此需要配置其环境变量。配置方法如下:打开我的电脑属性——更改设置——高级——环境变量,在系统变量中添加tesseract的路径。

win+R输入cmd打开命令行工具,输入tesseract -v,出现如下说明即配置成功

3、TESSDATA_PREFIX变量设置
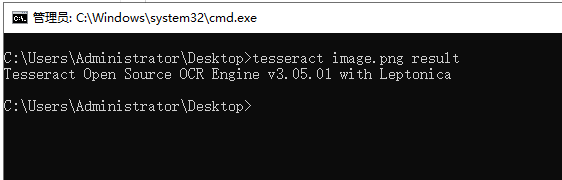
到这一步环境变量配置完成,但是此时直接使用tesseract对图片进行识别会提示错误
例如,在cmd窗口中使用命令tesseract 1.jpg res
出现如下的错误提示
Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize tesseract.主要原因在于没有设置TESSDATA_PREFIX变量,同样在环境变量中添加该变量可解决问题

4、命令行使用注意点
tesseract的命令格式为 tesseract image.(jpg,png...) res 其中res为最后的输出,默认为txt文件
注意的是在命令行中,image文件应该在执行该命令的文件夹中,否则会报错,显示
Error in fopenReadStream: file not found
Error in findFileFormat: image file not found
Error during processing.
因此,要么cd到图片文件的目录下,要么将图片所在位置完整给出,如C:1\2\image.jpg















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









