







1、起因
前一阵看sqlserver,学到范式。想起日志服务器的表,觉得不规范(其实后来觉得没必要改,因为太规范反而不好查询),所以要改一下表结构,对比一下insert时间。另一个原因是,想对比下每次插入1条记录,和一次插入1000条记录,性能会优化多少。
2、现象
每次插入10W条左右数据。如果是新的数据,则每1000条数据耗时1.5~3秒;如果已经插入过(不管有没有delete),没1000条数据耗时10~20毫秒。
3、解惑
问同事,同事告知可能是因为缓存。但是为什么是缓存,说不上来。
3、偶然
偶然发现,每次insert新的数据后,从任务管理器可以看到内存增长。疑似内存泄露?问度娘。度娘还是告诉,可能是因为缓存。
4、确认
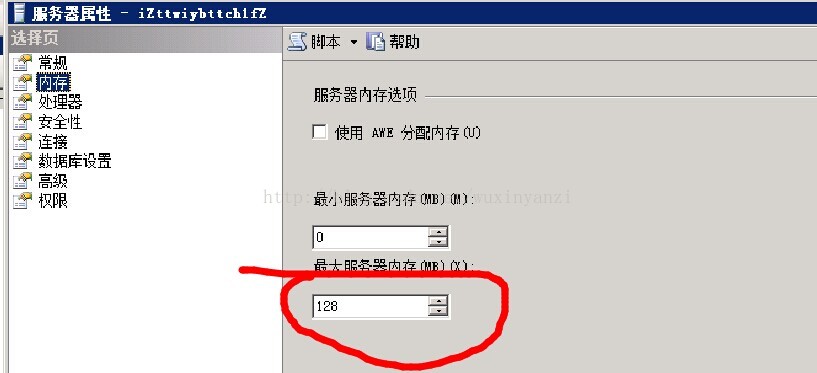
设置缓存,如下图。第二条的现象消失。内存增长的情况也和预计的一样。
5、缓存与插入速度的关系?
假设了几种可能,都被否了。不想在上面花时间了。。
6、最后贴上测试结果:
========================================================================
每次insert 1000条记录: 50秒
每次insert 1条记录: 33秒
2147483647M最大内存,2.3万条记录
每次insert 1000条记录: 46秒
每次insert 1条记录: 33秒
========================================================================
2147483647M最大内存,2.3万条记录
每次insert 50条记录,11秒;
=======================================================================
总结:
每次insert的记录,太多也慢,太少也慢。听同事说这个跟每条记录占用的空间也有关系。
爬坑结束。















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









