







目录
- 错误:Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
- 错误:预测结果执行着就变nan了
- 错误:预测值是nan
- 错误:list.sort()函数输出为None
- 错误:KeyError Traceback (most recent call last)
- 错误:RuntimeError: multi-target not supported at C:/w/b/windows/pytorch/aten/src\THCUNN/generic/ClassNLLCriterion.cu:15
- 网络不学习
- 数据不均衡
- TypeError: 'str' object does not support item assignment
- 'utf-8' codec can't decode byte 0xbe in position 0: invalid start byte
- SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: malformed \N character escape
- AttributeError: 'float' object has no attribute 'decode'
- 有编码解码问题,可以尝试
- to_csv() 参数
- open()函数的参数说明
- 下载sentence_transformers包
- 使用mean函数求list的平均值
错误:Can’t call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
错误原因:想要转换的张量带有梯度,直接将其转换为numpy数据将破坏计算图
错误:预测结果执行着就变nan了
原因:忘记给全连接层加激活函数
错误:预测值是nan
解决:做的是回归,更换激活函数,将relu更换为sigmoid
错误:list.sort()函数输出为None
如果在重新给列表排序的时候,给它嵌套到其它语句中,比如说赋值语句,或者print语句,最后打印输出的结果都是None。
例如
错误1:list=list.sort()
错误2:print(list.sort())
解决:
单独作为一行出现
例如
a = [5, 2, 3, 1, 4]
a.sort()
print(a)
错误:KeyError Traceback (most recent call last)
背景:训练集和测试集转成dataset形式的,然后random_split,最后DataLoader
解决了两次
1:更新dataframe后index忘记调,random_split中应该是乱的,迭代失败
2:忽视了进dataset的数据是dataframe类型的,dataset中不能直接data[i]索引行
错误:RuntimeError: multi-target not supported at C:/w/b/windows/pytorch/aten/src\THCUNN/generic/ClassNLLCriterion.cu:15
在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的。
如果target是这样的【batchszie,1】就会出现上述的错误。应该用squeeze()函数降低纬度。
网络不学习
- 特征提取的不好
- 模型用的不对
- 损失函数不行
数据不均衡
https://blog.csdn.net/login_sonata/article/details/54290402
TypeError: ‘str’ object does not support item assignment
str_ = ‘abcdefg’
str_[1] = str_[2]
解决方法:在python中,字符串是不可变对象,不能通过下标的方式直接赋值修改。同样的不可变对象还有:数字、字符串和元组。
将字符串数据转为list,list(str_)即可
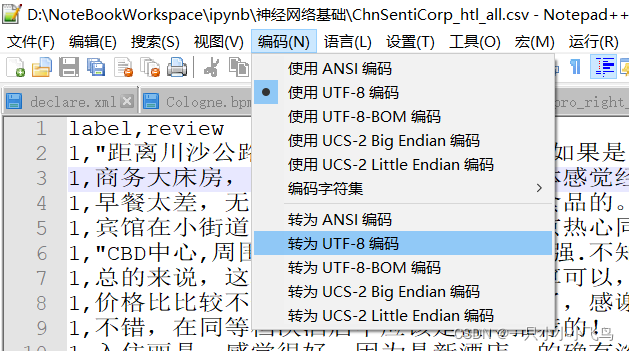
‘utf-8’ codec can’t decode byte 0xbe in position 0: invalid start byte
编码问题,使用Notepad++打开数据集文件,将编码转为UTF-8即可
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: malformed \N character escape
没有处理路径中的\转义字符,路径前加r或者写成\
AttributeError: ‘float’ object has no attribute ‘decode’
读取存储为.csv格式的文件,报属性错误。
解决方法:在read_csv后面加上.astype(str)
有编码解码问题,可以尝试
file = open(path, encoding=‘gb18030’, errors=‘ignore’)
file = open(‘D://Document And Settings3/lqz/Desktop/Walden2.txt’, ‘w’)
encoding = ‘gbk’
encoding = ‘utf-8’
encoding = ‘utf-8-sig’ (似乎可以解决Excel打开保存的csv文件中文乱码的问题)
encoding = ‘gb18030’
encoding = ‘gb18030’, errors = ‘ignore’
to_csv() 参数
header=None 不要表头,也就是每列的名字
index=False 不要行号
encoding=。。。。
open()函数的参数说明
‘r’:默认值,表示从文件读取数据。
‘w’:表示要向文件写入数据,并截断以前的内容
‘a’:表示要向文件写入数据,添加到当前内容尾部
‘r+’:表示对文件进行可读写操作(删除以前的所有数据)
‘r+a’:表示对文件可进行读写操作(添加到当前文件尾部)
‘b’:表示要读写二进制数据
下载sentence_transformers包
pip install sentence_transformers -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
使用mean函数求list的平均值
必须这样导包才行。。。import numpy 不行。。。。
from numpy import *
list_ = [1,2,5,6]
print(mean(list_))














 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









