






在做全文搜索的时候,我们经常会使用到es作为搜索引擎,用它来筛选出匹配度更高的文档。面对不同的场景,es默认的参数的排序结果可能并不能满足我们的需求,比如想降低词频或者文档长度的影响,那么我们如何根据实际场景调整参数呢?
作为铺垫,先让我们先来回顾一下es打分算法。
TF-IDF
在es 5.0 之前,使用的是TF-IDF算法(Term Frequency - Inverse Document Frequency)。TF-IDF理解起来并不困难,它由两部分组成,即TF(词频)-IDF(文档逆词频)。
简单点理解就是,TF代表单词在文档中出现的频率,频率越高证明这篇文档与搜索词越匹配。如果只使用TF可能会存在问题,比如有很多词他意义并不大,每段文章中都可能存在(比如“的”、“吗”等词),如果我们的搜索词内包含了这些词,那么可能文档越长评分就会越高,这显然是不合理的。IDF就是为了解决这个问题存在的,IDF代表了词的权重,搜索词越稀有,包含的文档可能就越匹配。
好了,我们了解基本原理,让我们看看具体计算公式是如何实现的
TF-IDF
简单的讲tf-idf 就是词频x词权重
TF-IDF
(
t
,
d
,
D
)
=
TF
(
t
,
d
)
×
IDF
(
t
,
D
)
\text{TF-IDF}(t, d, D) = \text{TF}(t, d) \times \text{IDF}(t, D)
TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
TF
让我们简单看一下公式
TF
(
t
,
d
)
=
freq(t,d)
totalWord(d)
\text{TF}(t, d) = \frac{\text{freq(t,d)}}{\text{totalWord(d)}}
TF(t,d)=totalWord(d)freq(t,d)
t:term,就是搜索词。
d:document,某篇文档。
freq(t,d):词t在文档d中的出现频率
totalWord(d):文档d所有词的个数
IDF
IDF
(
t
,
D
)
=
log
(
count(D)
count(t,D)
+
1
)
\text{IDF}(t, D) = \log\left(\frac{\text{count(D)}}{\text{count(t,D)} + 1}\right)
IDF(t,D)=log(count(t,D)+1count(D))
D:所有文档
count(D):所有文档数量
count(t,D):包含t的所有文档数量
缺点
在一个文档中如果一个词t的词频非常高,那么最终分数也会非常的高。例如一个文档中仅仅写了几十遍“中国”,那么一旦我们搜索语句中带有"中国"这个term(ex:中国最大的城市),这篇文档会因为中国这个词的词频过高,最终影响整个查询问题的综合效果。而BM25正是一种TF-IDF 的优化算法算法。
BM25(best match)
我们首先来看一下BM25和TF-IDF的词频-分数曲线,可以看到当词频达到一定程度以后,BM25的分数会趋于固定。
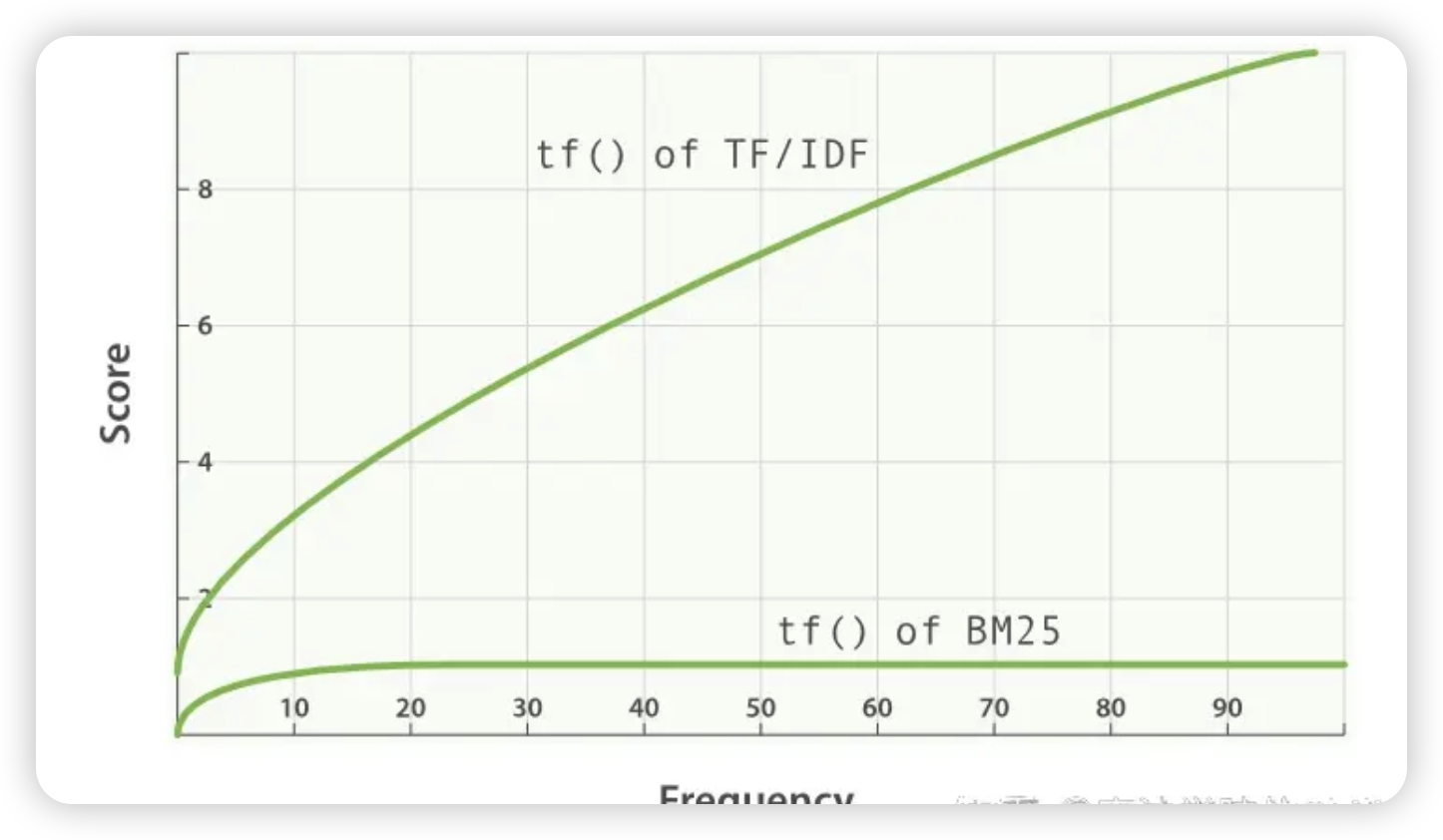
BM25 ( t , d ) = ∑ i = 1 n ( k 1 + 1 ) ⋅ f r e q ( t i , d ) k 1 ⋅ ( ( 1 − b ) + b ⋅ len ( d ) avg_len ) + f r e q ( t i , d ) ⋅ IDF ( t i , D ) \text{BM25}(t, d) = \sum_{i=1}^{n} \frac{{(k_1 + 1) \cdot freq(t_i, d)}}{{k_1 \cdot \left((1 - b) + b \cdot \frac{{\text{len}(d)}}{{\text{avg\_len}}}\right) + freq(t_i, d)}} \cdot \text{IDF}(t_i, D) BM25(t,d)=i=1∑nk1⋅((1−b)+b⋅avg_lenlen(d))+freq(ti,d)(k1+1)⋅freq(ti,d)⋅IDF(ti,D)
n 查询内容的总分词数, t i 第i个词, f r e q ( t i , d ) 第i个词在文档d中的频率 len d 文档d的长度 avg_len平均文档长度 k 1 词频调节参数 b 文档长度条件参数 \begin{align*} & n \text{ 查询内容的总分词数,} \\ & t_i \text{ 第i个词,} \\ & freq(t_i, d) \text{ 第i个词在文档d中的频率}\\ & \text{ len d} \text{ 文档d的长度 } \\ & \text{avg\_len} \text{平均文档长度} \\ & k_1 \text{ 词频调节参数 } \\ & b \text{ 文档长度条件参数 } \end{align*} n 查询内容的总分词数,ti 第i个词,freq(ti,d) 第i个词在文档d中的频率 len d 文档d的长度 avg_len平均文档长度k1 词频调节参数 b 文档长度条件参数
这里与TF-IDF计算方式稍有不同,分子分母都有count(t,D)
IDF
(
t
,
D
)
=
log
(
c
o
u
n
t
(
D
)
−
c
o
u
n
t
(
t
,
D
)
+
0.5
c
o
u
n
t
(
t
,
D
)
+
0.5
)
\text{IDF}(t, D) = \log\left(\frac{count(D) - count(t,D) + 0.5}{count(t,D) + 0.5}\right)
IDF(t,D)=log(count(t,D)+0.5count(D)−count(t,D)+0.5)
k1 的作用与调节
在讲述TF-IDF缺点时,我们提到,过高的词频会较大程度影响查询效果,所以BM25这里设计了K1参数。那么k1是如何影响分数的呢?
我们来简化一下bm25算法,以方便观察。
假设文档某个文档d长度等于平均文档长度,即len(d)=avg_len。参数b(后面再说)设置为1,不考虑IDF,那么公式将会变为。
BM25
(
t
,
d
)
=
∑
i
=
1
n
(
k
1
+
1
)
⋅
f
r
e
q
(
t
i
,
d
)
k
1
+
f
r
e
q
(
t
i
,
d
)
\text{BM25}(t, d) = \sum_{i=1}^{n} \frac{{(k_1 + 1) \cdot freq(t_i, d)}}{{k_1 + freq(t_i, d)}}
BM25(t,d)=i=1∑nk1+freq(ti,d)(k1+1)⋅freq(ti,d)
简化坐标系上的公式就是
y
=
k
1
∗
(
x
)
(
k
1
+
x
)
y= \frac{{k1*(x)}}{{(k1+x)}}
y=(k1+x)k1∗(x)
当k1取es默认值1.25时,它的曲线时这样的。
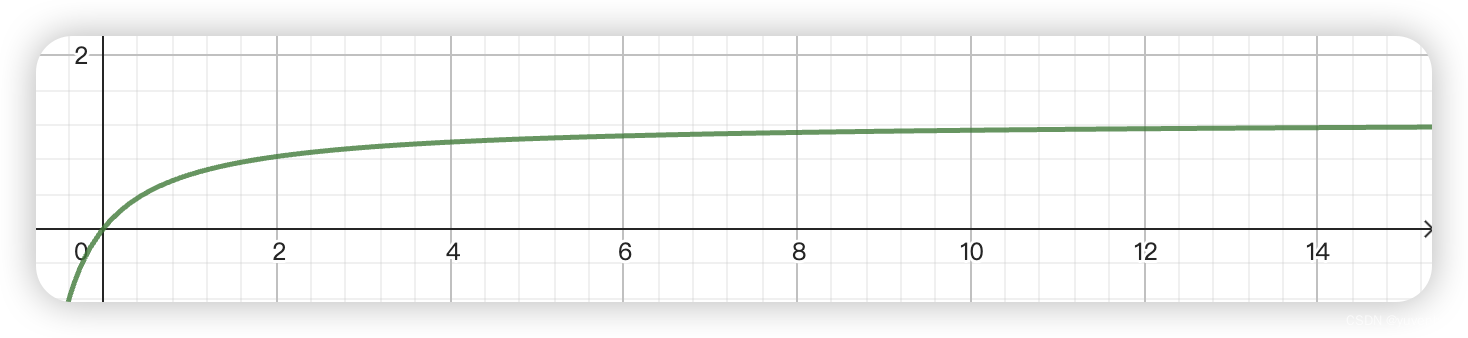
如果我们希望词频的影响更小一些,那么我们就可以把k1调小,实现类似于 只要含有这个词,大家freq分数都差不多这样的效果。如果我们希望词频影响大一点,实现类似多次提到那么久可能含有更多相关信息的效果。一般情况下我们并不需要调整k1。
b 的作用与调节
b的主要作用是控制文档长度对分数的影响,比如在相同词频的情况下,文档越短,那么短的文档中term就越重要。
同样的,我们为b参数再简化一下公式,去掉IDF,k1我们取常数1。
BM25 ( t , d ) = ∑ i = 1 n 1.75 ∗ f r e q ( t i , d ) ( 1 − b ) + b ⋅ len ( d ) avg_len + f r e q ( t i , d ) \text{BM25}(t, d) = \sum_{i=1}^{n} \frac{{ 1.75*freq(t_i, d)}}{{ (1 - b) + b \cdot \frac{{\text{len}(d)}}{{\text{avg\_len}}} + freq(t_i, d)}} BM25(t,d)=i=1∑n(1−b)+b⋅avg_lenlen(d)+freq(ti,d)1.75∗freq(ti,d)
可以发现,b越大文档len(d)/avg_len 影响越大,也就是文档长度的影响越大,es中b的默认值为0.75。
在我的日常使用中发现,当我们在搜索标题这种短文本时,0.75会对结果产生比较大的影响,我们可以根据实际情况调小b的数值。
策略的查看与修改
如何查看打分过程
在查询时,增加"explain": true参数,可以在查询结果的details内看到分数是如何计算的。
GET /scenic/_search
{
"explain": true,
"query": {
}
}
结果:
{
"details": [
{
"value": 3.814343,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.0,
"description": "boost",
"details": []
},
{
"value": 4.4669995,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 9750,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 849219,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.42694688,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1.0,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.0,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.3,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 6.0,
"description": "dl, length of field",
"details": []
},
{
"value": 2.802814,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
修改打分参数
在es中,我们可以在索引settings中增加一个similarity方案。
{
"index": {
"similarity": {
"name_similarity": {
"type": "BM25",
"b": 0.3,
"k1": 1.25
}
}
}
}
然后在mapping里面指定使用这个方案。
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"similarity":"name_similarity",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}















 1603
1603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









