






本月一篇人工智能论文登上了《科学》杂志的封面,三名别离来自麻省理工学院、纽约大学和多伦多大学的研究者开拓了一个‘只看一眼就会写字’的系统。与现在火热的盲学习的deep learning不同,此。。。
Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-level concept learning through probabilistic program induction.” Science 350.6266 (2015): 1332-1338.
翻译暂时不全,待补充,内容大部分转自http://chuansong.me/n/2030568
摘要
前言
尽管人工智能和机器学习已经取得了巨大的进步,但是机器还是无法掌握人类概念认识的两个方面。
首先,世界上存在无数自然和人造的事物,但人们都可以从一个或者几个例子中就学习到新的概念,但机器学习算法却需要几十个甚至几百个类似的例子才可以达到这样的程度。例如,人们要理解一种新颖的两轮车,只需要看1张图(图A1)就好了,就算是一个孩子也可以通过图A1-A3来理解这个新事物的概念。
相反的,许多领先的机器学习都要通过海量的数据模型才可以理解概念,特别是取得新层次的语音识别为基准的深度学习模型。
其次,人们学习的内容比机器更加丰富,即使对象只是一个简单的概念(图B),除了理解,人们还可以做到更多,例如举一反三(图B1、B2),剖析对象整体和局部的关系(图B3),以及在现有类别的基础上再做分类(图B4)。
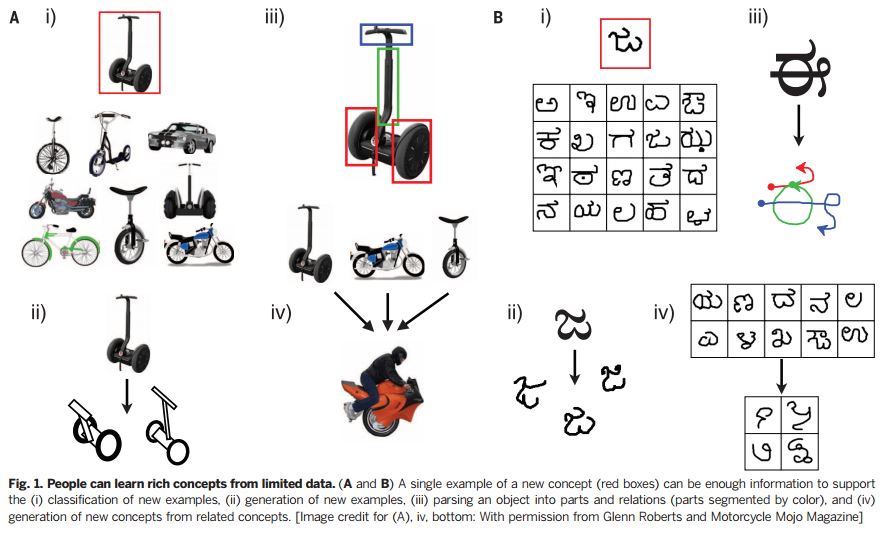
人们可以从有限的数据中学习到丰富的概念
相比之下,就算是最好的分类机器也难以做到这些,通常是需要专门的算法才可以一一尝试。
当前,我们正在试图探究人类这两方面的学习方法:人们是怎样通过一两个例子就可以学习新概念的?人们是如何进行这样抽象、丰富、灵活的再加工的?
当这两个问题叠加,又出现了新的挑战:如何基于如此简单的数据而产生丰富的加工成果?对于任何学习理论来说,越复杂的模型需要越多的数据,才可以达到良好的泛化,在新陈之间可以通用。但人类就是可以做到这一点,人脑中似乎有某种“导航”,帮助人类把简单的数据加工成复杂的成果。
这篇文章旨在介绍贝叶斯学习程序(BPL)框架,如何依靠简单的例子来对新概念进行学习和加工,这种学习方法的主体是人类。
概念被表示为简单的概率性程序,也就是说概率生成抽象描述语言的结构化程序。
我们的框架汇集了三个关键信息:语意合成,因果关系,学习。根据这些来学习认知科学和机器学习在过去几十年的发展情况。把简单的原语合成丰富的概念,称为“语意合成”,这个过程会排除掉一些多余杂乱的信息并创造有用的信息,然后根据抽象的“因果关系”来处理,生成类别概念。通过观察来构造程序模型,通过开发先知和根据经验来理解新概念,达到BPL的“学会学习”。简而言之,BPL可以通过现有的碎片信息来重新加工,捕捉真实世界中的因果关系,重生成多层面的结果。
除了上面提到的简单图画来说明BPL,我们这里再用一组具有挑战性的学习任务来说明。这个任务使用的从Omniglot中抽取的简单视觉概念,这都是一些手写的字符。手写字符非常合适用来比较人类和机器学习的差异,人类可以认知自然事物,并且都有自身常用的基准学习方法。然而,机器学习算法是通过评估成百上千的训练示例后才能进行分类和解析。我们还通过更有创造性的项目来区别人类和计算机分别生成的概念,采用三种不同的深度学习模型来做比较,包括两种不同的深卷积网络,但是我们发现他们需要更多的概率模型才能完成一次性的学习任务。
贝叶斯学习程序
BPL从简单的随机程序中学习到概念,然后从整体、部分、空间关系等方面来加工。BPL以新方式来加工得到的部分信息,生成一个新型概念。然后新型概念作为下次加工的基础,进行再次加工。用二进制的公式表示如下:
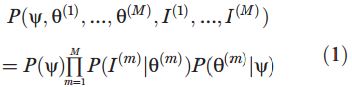
学会学习的模型拟合30个字符背后的条件和背景,使用图像和数据来分析,这符合深度学习的模型。生产出的新数据和新字符可以用到随后的再次加工任务中,为任务提供参考对象。

简单是视觉概念可以比较人类和机器的学习
手写字符是一个抽象的模式,这个模式包括部分和整体的关系,而书写结构反映因果关系。我们要建立一个新的书写类型,第一,样本模型主要部分x和子部分ni的组成,每个部分i = 1……x,它们由经验分类背景数据集合所得。第二,从样本数据中建立一个s模版,由采样的子部分组成。此数据集合源自学习背景数据所得的分散原始数据(图. 3A, iv) ,因此后者的概率则取决于前者。第三、主部分是参数化曲线的基础,它是抽样不同的控制点和规模参数所得;第四、主部分大致确定之后,它就开始独立运作,无论是开始、结束还是整个过程,都取决于关系R1(图. 3A, iv)。
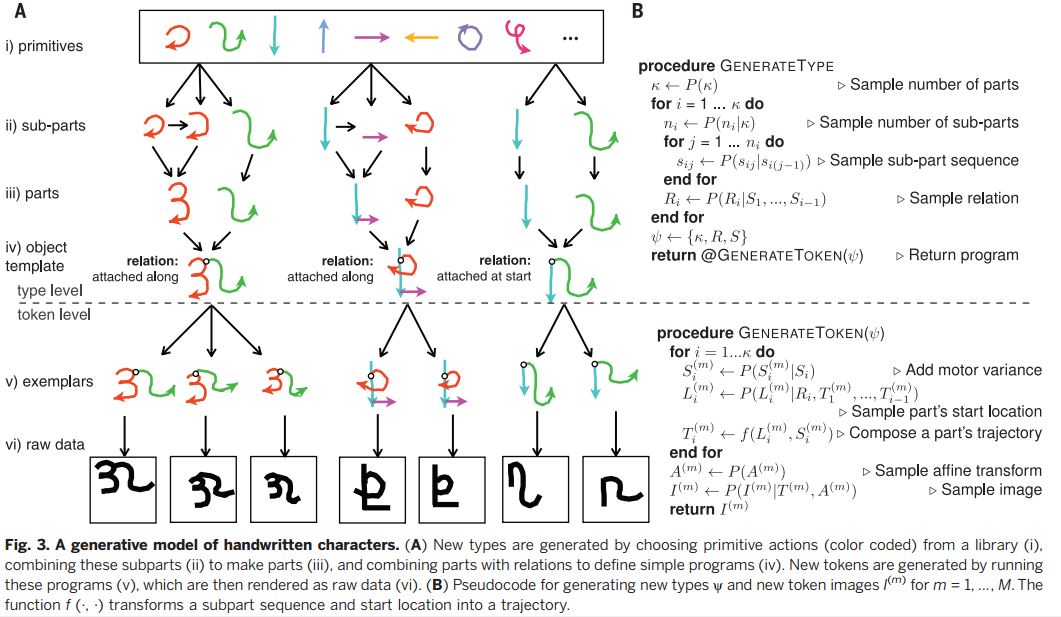
手写符号生成模型
(A)通过选择数据库中的原始运行数据(颜色编码)生成新类型,结合这些子部分(II)形成主要部分(III),并利用主要部分和关系定义简单的程序(IV)。通过运行这些程序,新的规则生成(v),然后又将其作为原始数据呈现(VI)。(B)继而产生新的规则。
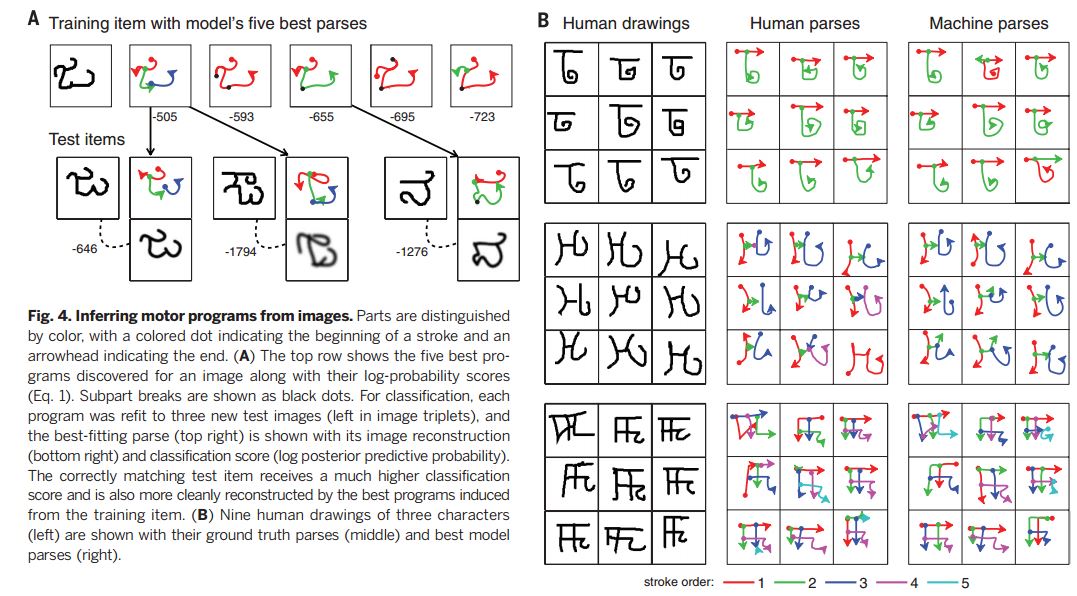
运行轨迹推断程序
不同的部分以颜色区分,有颜色的一点代表开始的一笔,有颜色的箭头则表示结束。(A)最上面的一行显示了5个顶级程序。(公式一)。分开处以黑点呈现。为了分类,每个程序被重组成三张测试图片,最佳拟合程序以图片重组和分类分数呈现。正确的配对将会得到很高的分类分数,也将会更有规律地被这些最优程序重组。(B)9个人写的字,左边是真实笔画解析,右边是程序给出地解析。
字体规则的生成是通过字体的每个部分及其之间的关系和墨水如何从笔挥洒到纸张组成。首先,书写者差异性导致写出的字体与程序认定规则的字体有所偏差。其次,笔画轨迹的开始位置是由示意图所提供的关系R1到它之前的笔画。第三,全球字体变形已经被采样,包括以及其他多种会影响因素。最后,二进位制图像是由一个随机的渲染功能, 通过灰度油墨把笔画轨迹联合起来。
之后的推断需要搜索程序中的大量组合。我们的策略是使用快速的自下而上的方法生成一系列的候选解析。最优方案则通过连续优化和局部搜索的方式,从离散逼近达到最后分布。图表4A展示了图形重组的过程,当得到分布高分后,即可证明图片属于同一组。图表4B几组展示比较了系统的最高分解释与基于人类真实书写情况的解释。
结果
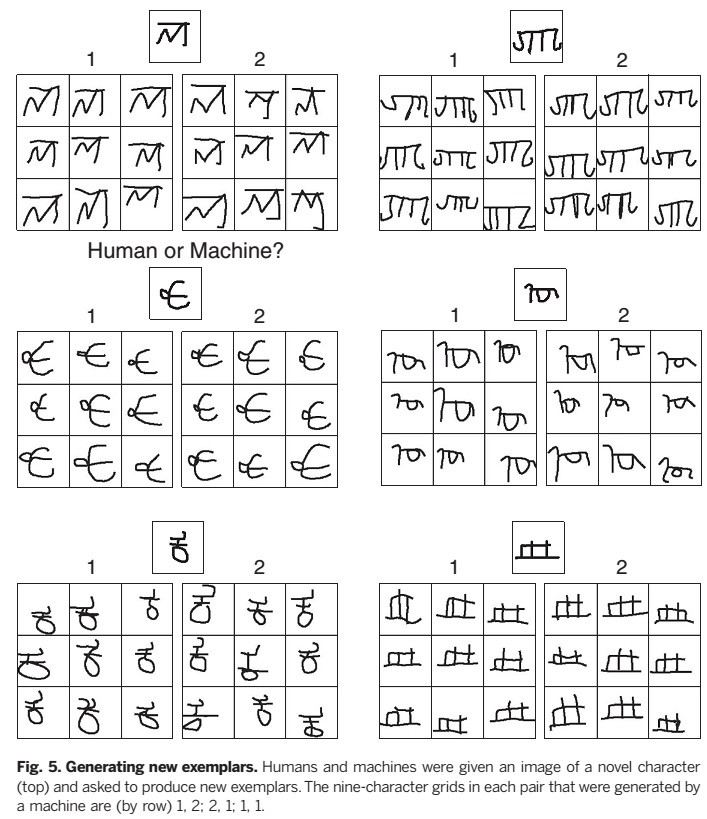
产生新的样例
人、BPL、替代模型的被放在5个学习概念模式中进行比较(图5中示例任务)。所有的行为实验都在亚马逊的Mechanical Turk进行的,实验过程与细节在section5展示。实验主要结果由图表六呈现,变量控制等报告在section s6中。
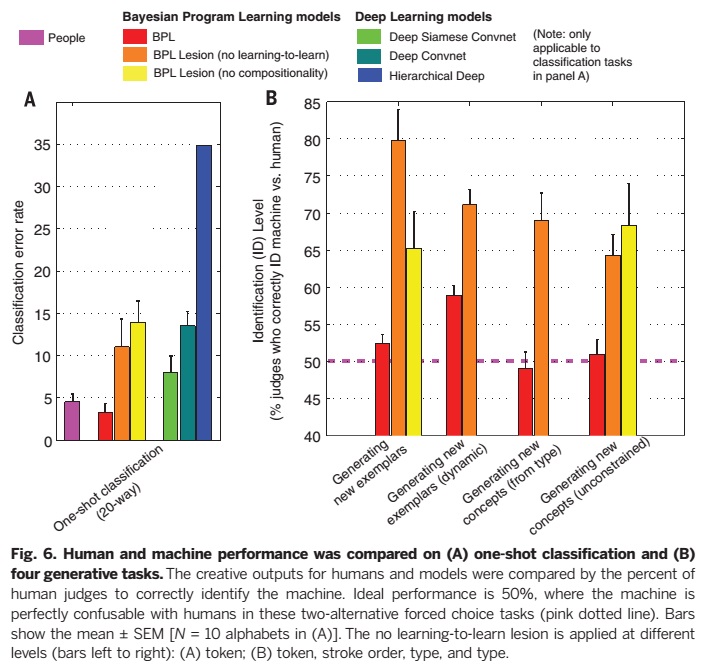
第一次分类由10个字母的任务列表进行评估。就像在Fig.1B所说的那页,当单独字符的出现,参与者要求被选择时,他们会从20个同一字符不同变形的字符中选择错误的,这个实验可参见fig 6A,错误率达95%。作为一个基准,改进后的Hausdorff减少至38.8%。人类是成功的一次性学习者,平均错误率仅为4.5%。
BPL也显示了相似的错误率,为3.3%。然而深卷积网络错误率为15.8和HD错误率为34.8%,这两者皆通过深度学习在计算机视觉任务中表现优秀。一个优化之后的暹罗卷积网络实现了8%个错误,不过还是人类以及我们这个模型犯错率的两倍。BPL的优势点在于能够模仿学习概念中潜在的因果过程,不同于此处检验的特定深度学习的策略。
BPL在其他方面也做出了积极贡献,即显示了没有学会学习(此处指标记层面)和组合时,会呈现较高的错误率(分别为为11.0%和14.%)。学会学习是指通过破坏生成模型的超参数单独研究类型与规则层面的内容。组合性指的把BPL与匹配模型进行对比,像早期手写字符的分析合成模型那样。
人类一次性学习的能力不仅仅是分类,它还包括一系列其他技能,如针对新的概念举出例子。我们通过图灵视觉测试,比较了人和机器的创意输出。裁判需要分辨九幅人类根据BPL绘画规则所做的画。我们根绝裁判的准确率给出评价,我们称为他们的身份水平:理想模版的正确率为50%,意味着他们不能够很好地分辨人类与模版地行为;最坏地情况错误率则为100%。每个裁判单独完成49个测试,没有反馈。结果在图6B中显示。裁判识别人类与BPL仅有52%平均准确率。作为一个群体,他们的表现远不及“猜”的准确率高,48个裁判中仅有3人的ID准确率高于“猜”。
三种障碍模型被不同团队的裁判依据不同条件下的视觉图灵测试进行评判,以此验证BPL中关键模型要素的必要性。学会学习(仅标记层面)和语意合成性这两种障碍显著简化了图灵测试任务,这表明通过此种任务是不平凡的,也表明这两种原则都有助于提高BPL类人型生产能力的熟练度。为了更直接地进行语法分析(Fig. 4B),我们与不同裁判(N=143)一起测试了这一任务的动态版本,每一项试验都显示人与BPL绘制了相同的字母。在这一视觉图灵测试中BPL的表现并非完美(在ID层面平均59%的正确率),但是,提前随机排列笔画顺序和方向显著提高了正确率,这表明获取正确的因果动态对BPL是重要的。
虽然从30个背景字母中学到新的特征被证明是有效的,许多人类学习者只需要更少的经验,在相关的绘制任务中只需熟悉1个或几个字母。为了看看在更局限的经验下模型的表现如何,我们用两个只含几个背景字母的子集合再次训练了其中数个模型。BPL取得了与此前相似的成绩(错误率由4.0% 提高到4.3%)。深度卷积网络的表现则显著变差(错误率由22.3% 提高到24.0%)。这些结果表明,尽管学会学习影响着BPL的成功,这一模型的结构允许它充分发挥相当有限的训练的作用。
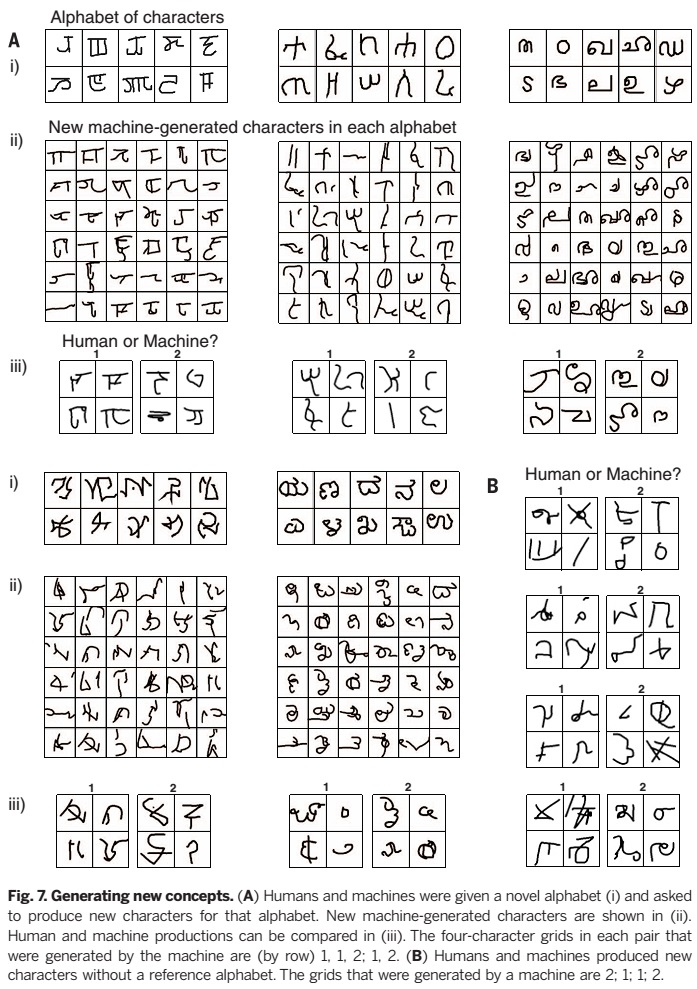
人类的生产能力远远超过生成给定概念的新例子:人类可以生成全新的概念。为了测试这一点,我们给参与者展示了几个外文字母,要求他们迅速创造一些看起来与这些字母同类的新字母(Fig.7A).。通过在种类层面设定非参数,BPL可以效仿这一行为,偏好重新利用示例字母中的笔画从而形成风格一致的新字母(section S7)。在一场视觉图灵测试中人类裁判比较了人和BPL的成果(N = 117)。Section S6中进一步的比较表明,这一模型生成貌似真实的新奇字母而非风格本身的能力是其通过测试的关键。
裁判们 (N = 124)还比较了在不受给定字母的约束下,人和模型如何完全自由地生成新奇字母(Fig. 7B)。对BPL中字母类型的先验分布的抽样导致了视觉图灵测试中ID层面的平均正确率达57%。而在重新使用背景字母笔画的非参数测试中,BPL取得了51%的正确率。
讨论
尽管人工智能的前景正在改变,在学习新概念上人类仍远优于机器:人类只需要更少的例子,却能以多种形式运用概念。我们的工作表明,语义合成性、因果关系和学会学习将帮助机器弥补这种差距。机器学习和计算机视觉的研究者正开始探索建立在简单程序归纳上的方法,我们的结果表明这种方法可以使人工智能在分类任务中达到人类的水平,并能在视觉图灵测试中骗过大多数裁判。在每项测试中,只有不到25%的裁判的表现显著好过随机猜测。
虽然能够成功完成这些任务,在识别视觉概念中的结构上BPL仍无法与人类相比。它缺乏平行、对称、可选要素(如“7”的小角)等外显知识,也不知道一个笔画的收尾与其他笔画的联系。而且,人类还运用了对其他能力的概念:绘画、说明、沟通以及概念组合。概率程序可以掌握概念学习与运用的多个方面,但这只会发生在它们拥有更抽象和复杂结构时。更复杂的程序还能适合学习超出简单知觉范畴的复杂概念及其因果关系。例子包括物理构件(如工具、车辆和家具)、分形结构(如河流和树木)甚至抽象知识(如自然数、自然语言语义和物理理论)。
知晓人类如何学会所有这些概念是一个长期目标。在近期,将我们的方法应用到其他类型的符号化概念可能非常具有前景。人类文化提供了许多符号系统,如手势、舞蹈、口语和手语。和字母一样,这些概念可以从一个或几个示例中学到,即便其象征性还不明显。人们通常可以根据有限的经验认出甚至给出新的例子。BPL的语义合成性、因果关系和学会学习等原则或许有助于解释这是如何发生的。
为了说明BPLBPL如何应用于语音领域,口语程序可以被指导将构成音素系统性地汇成音节,再进一步汇成词素和整个词语。给出一个词语抽象的音节和音素分析,因果模型就可以生成现实语音标记。我们已经发现了一个利用语义合成性和学会学习原则的原型模型,它可以模仿人学习新口头词汇的某些方面。
我们的工作侧重于成年学习者,这引出了自然发展问题。如果儿童和BPI一样,在学习写字时有归纳性偏向,那么这一模型就有助于发现为什么儿童觉得有些字母难写,以及哪种教学过程最为有效。比较儿童和BPL在不同阶段的分析和泛化行为,这有助于评估模型学会学习的机制并给出改善意见。将我们的测试拿给婴儿做,据此可以知道孩子在学习感知字母时,是否更依赖建立在他们原始写作经验之上的语义合成性和因果关系。因果关系的再呈现已经被纳入到现在的BPL模型中,但它们很可能是通过更深的层次结构模型嵌入到“学会学习”这一过程中。
最后,我们希望上述工作有助于揭示概念的神经表征,并推动更多基础神经学习模型的发展。此前的行为研究和我们的结果共同表明,人们部分地通过推断抽象程序学习新的手写字母。我们可以像分析BPL那样解码人类学习新知时的大脑运动前区皮质(或者其他行动导向区域)的活动吗?最近,大型脑模型和深度递归神经网络也将重点放在了字母识别和生产任务上,但通常是从每一概念的大样本示例中学习。我们将此文介绍的新模型视作这些神经模型的一个挑战。我们希望它能融合BPL已经给出实例的语义合成性、因果关系和学会学习三原则。















 3120
3120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









