









Docker
- Docker Community(社区)
- Reference documentation(参考文档)
Docker hub
- Docker hub
一些常用组件的docker hub地址
- openjdk
- nacos/nacos-server
- mysql
- redis
- rabbitmq
- elasticsearch
- zookeeper
- bitnami/kafka
- ubuntu
- debian
- nginx
Dockerfile
- Dockerfile reference
Docker命令
- Docker command line(命令帮助文档)
镜像相关
docker build -t jdk8:v1.0 . #在Dockerfile所在目录基于Dockerfile构建镜像 docker images #查看镜像 docker pull openjdk:8u342-jdk #去docker hub 拉取镜像 docker history openjdk:8u342-jdk #查看镜像构建历史 docker tag openjdk:8u342-jdk myjdk:1.0 #给镜像打个新tag重命名 docker rmi -f myjdk:1.0 #删除镜像 docker rmi -f $(docker images | grep test | grep -v ubuntu | awk '{print $3}') #批量删除镜像 docker save openjdk:8u342-jdk -o openjdk-8u342-jdk-x86_64.tar #导出镜像到tar文件 docker load -i openjdk-8u342-jdk-x86_64.tar #加载镜像文件 docker load -i openjdk-8u342-jdk-`arch`.tar #动态加载对应架构的镜像文件 docker commit myjdk:1.0 openjdk:8u342-jdk #将容器内容提交到镜像清理相关
清理数据卷
a.数据卷是被设计用来持久化数据的,它的生命周期独立于容器,Docker不会在容器被删除后自动删除数据卷,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的数据卷。如果需要在删除容器的同时移除数据卷。
b. 可以在删除容器的时候使用 docker rm -v XXX这个-v参数。docker volume ls #查看当前卷列表 docker volume prune #清理无用的卷清理dangling镜像
dangling镜像即所谓的悬挂镜像/虚悬镜像,表现为docker images命令查看时,显示的无tag镜像;docker image prune #也可以用这种组合命令 docker rmi $(docker images -f dangling=true -q)更加彻底的清理docker相关内容
docker system prune #清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像 docker system prune -a #命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉inspect 查看命令
- docker inspect
#可以通过该命令查看镜像或者容器的相关信息 docker inspect [OPTIONS] NAME|ID [NAME|ID...] #查看镜像相关信息 docker inspect openjdk:8u342-jdk #json格式查看image的Config docker inspect -f '{{json .Config}}' openjdk:8u342-jdk #查看容器的目录映射关系 docker inspect -f "{{.Mounts}}" test-container docker inspect -f '{{.ID}}' test-container #查询容器的长id #根据容器名称查找容器再宿主机的目录 docker inspect test-container | grep /var/lib/docker#根据卷id反过来查找所属容器 vid=010db1649403a75ecac82362e52e3ab1021d2d39c4f21971e5acca5743bd187d ids=`docker ps | awk 'NR!=1' | awk '{print $1}'` for id in $ids do count=`docker inspect -f "{{.Mounts}}" $id | grep $vid | wc -l` if [ $count -ge 1 ]; then docker ps | grep $id fi done容器相关
docker run -d --privileged --name ubuntusz2 ubuntu:sz2 tail -f /dev/null docker run -d --net=host -v /home/sz:/home/sz --name keensense-mysql keensense-mysql:base tail -f /dev/null docker run --restart always --name mynginx -d nginx #设置启动策略 docker update --restart no mynginx #如果容器已经被创建,修改容器的重启策略 docker logs ubuntusz2 #查看docker日志 docker exec mysql /bin/bash -c 'cd sz && bash init.sh' #在宿主机执行容器内部命令 docker cp sz mysql:/sz/ #复制宿主机内容到容器内docker重启策略:
no 不自动重启容器. (默认值) on-failure 容器发生error而退出(容器退出状态不为0)重启容器,可以指定重启的最大次数,如:on-failure:10 unless-stopped 在容器已经stop掉或Docker stoped/restarted的时候才重启容器 always 在容器已经stop掉或Docker stoped/restarted的时候才重启容器,手动stop的不算docker compose
- Overview of docker compose CLI(概述说明含命令帮助等)
- Compose file specification(文件规范)
Docker权限
#1. docker默认运行在root用户下,有些情况下,要求运行在非root用户,此时就会有权限问题; #2. 如果容器内部运行的用户为非root用户,且有将宿主机的目录映射挂载到容器,此时也可能产生权限问题; #3. docker容器其实是共享宿主机上的内核的,而uid和gid都是由Linux内核负责管理,所以容器内部的uid和gid和宿主机的uid和gid实际上是同一套;所以虽然容器内用户名和宿主机用户名可能不一样,但是如果他们的uid是同一个,则它们实际上就是同一个用户,所以docker容器和宿主机的用户和组权限通过相同的uid和gid实现了统一; #4. 一般Linux下root用户的uid和gid都是0;普通用户的uid和gid都是从1000开始的,所以一般安装好的linux非root用户的uid和gid都是1000;非root用户无法使用docker
#1.将用户加入docker组 sudo gpasswd -a ${USER} docker #2.重新启动docker服务 sudo service docker restart 或 sudo systemctl restart docker #3.当前用户退出系统重新登陆 su root su ${USER} # 可以通过id命令查看用户id或者id值对应的组和用户 id 1000 id user #2. 如果uid不为1000,可以考虑 su root 命令切换到root用户下,然后执行命令修改uid usermod -u 1000 myuser #将用户id修改为1000;镜像用户权限设置
例如下列Dockerfile,就是将容器内的运行程序的用户和组全部设置成1000,此时宿主机如果存在uid和gid为1000的用户,那么此时就实现了权限的统一;
FROM ubuntu:base MAINTAINER sz ENV APP_HOME /usr/share/elasticsearch ENV APP_NAME elasticsearch ENV APP_USER elasticsearch ENV APP_VERSION 6.8.17 ENV JAVA_HOME /opt/jdk1.8.0_301 ENV PATH ${JAVA_HOME}/bin:${APP_HOME}/bin:$PATH RUN mkdir -p ${APP_HOME} RUN groupadd --gid 1000 ${APP_USER} RUN useradd -u 1000 -g 1000 -G 0 -d ${APP_HOME} ${APP_USER} RUN chmod 0775 ${APP_HOME} RUN chgrp 0 ${APP_HOME} WORKDIR ${APP_HOME} COPY --chown=elasticsearch:elasticsearch ${APP_NAME}-${APP_VERSION} ${APP_HOME}/ COPY --chown=elasticsearch:elasticsearch jdk1.8.0_301 ${JAVA_HOME} USER ${APP_USER} ENTRYPOINT ["bash","-c","elasticsearch -d && tail -f /dev/null"]容器启动时指定运行用户
此时,映射挂载的宿主机目录只要所有者是uid=1000的用户,容器内部对应的目录权限所有者也是uid=1000的用户;这样就达到了权限统一,避免容器运行时目录和文件权限不足的问题;
#给宿主机的目录所有者设置为1000 chown -R 1000:1000 $installPath chown -R 1000:1000 $dataPath chown -R 1000:1000 $logPath #chown -R 1000:1000 $binPath #chown -R 1000:1000 $configPath chown -R 1000:1000 $backupPath #chown -R 1000:1000 $scriptPath #运行创建容器 docker run -d \ -v /etc/localtime:/etc/localtime \ -v ${configPath}/elasticsearch.yml:${APP_HOME}/config/elasticsearch.yml \ -v ${configPath}/jvm.options:${APP_HOME}/config/jvm.options \ -v ${dataPath}:${APP_HOME}/data \ -v ${backupPath}:${APP_HOME}/backup \ -v ${logPath}:${APP_HOME}/logs \ -u elasticsearch \ --privileged \ --net=host \ --log-opt max-size=100m \ --log-opt max-file=5 \ --name ${container} ${imageName}一些问题和故障处理
docker有时候因为加载问题无法重启,可以试试:
sudo daemon-reload && sudo systemctl start dockerdocker引擎无法启动
遇到的一次docker无法启动,报错:code=exited, status=1/FAILURE
解决过程:
#1. 删除/var/run/docker.sock目录 #2. 启动docker服务 service docker start #3.启动过程好像出现了长时间的阻塞,后不得已强制结束,Ctrl+c #4.查看/var/run/目录下已新建了docker.sock文件 #5.查看docker服务是否启动:docker image #6.还是出现命令阻塞,Ctrl+c强制退出 #7.关闭docker服务,正常关闭 service docker stop #8.启动docker服务,正常启动! service docker startdocker容器文件损坏,导致docker无法启动
记录一次docker容器文件损坏,导致docker无法启动;
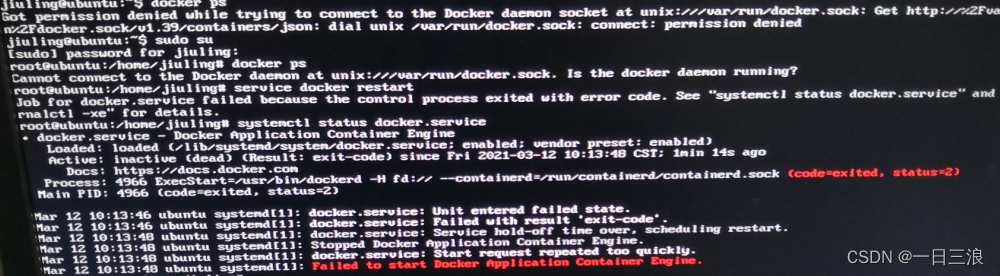
1.为了验证docker还能自我恢复,把docker运行目录挪走,mv /var/lib/docker /var/lib/docker.bak 2.重启docker服务service docker stop && service docker start 3.查看ll /var/lib/docker是否正常生成,查看docker状态service docker status 4.如果正常,则停止docker服务:service docker stop 5. 还原前面备份的mv /var/lib/docker /var/lib/docker.new && mv /var/lib/docker.bak /var/lib/docker 6.一步一步排查 containers image network overlay2 volumes看是哪个文件夹导致的无法启动; -------------------------------------------------------------------------------------- 遇到过的一个案例,报错为status=2,很多网上的docker错误相关都是status=1的;所以都没啥帮助; 唯一有status=2的是一个ftp无法启动的问题,说是网络相关,所以猜测这个报错也是网络相关问题; 把mv /var/lib/docker/network /var/lib/docker/network.bak后;重启docker服务service docker stop && service docker start 发现docker images等都正常了,但是所有的容器都无法加载;但是因为所有的文件都还再,只是无法加载容器的网络信息导致无法展示docker容器; 所以使用docker-compose -f docker-compose.yml up -d来重新构建所有的容器,因为文件和配置都在,那么就相当于基于原有文件来构建了容器,这样就相当于恢复了。 衍生: 网上也有说其中/var/lib/docker/network/files/local-kv.db记录了网络信息,由于1.9.1版本的bug,导致该文件意外受损;如果真的是这个问题,可以考虑将这个网络文件备份; 处理: 当文件损坏时,拿备份文件覆盖该文件,cp -rf /u2s/local-kv.db /var/lib/docker/network/files/local-kv.db 然后重启docker服务即可 service docker restart 这种情况下一般可能有一些容器未启动,使用docker ps -a看下,然后把未启动的容器启动一下;VM虚拟机中安装docker后,无法访问的问题
记录一次在VM虚拟机中安装docker后,无法访问的问题;
1.安装docker后,目标服务器无法ping通,停掉docker服务后,就可以ping通了; 2.判断应该是docker虚拟网卡和VM虚拟机的网络冲突了;可以直接使用命令ifdown docker0关闭docker虚拟网卡,和ifup docker0启动docker虚拟网卡来判断; 3.停止docker服务,执行 ifconfig查看网络相关地址; 4.启动docker服务后,再执行ifconfig查看网络; 5.发现docker虚拟网卡的默认默认网络短和vm服务器ip的网络段不是同一个网络段,不通; 6.修改docker虚拟网卡的ip地址到vm服务器ip的同网络段: vi /etc/docker/daemon.json 文件,如果没有就新增; 再json文件中新增bip选项,ip地址填写同一网络段ip(修改成本机ip好像会无法使用),端口21/24即可;例如:{"bip": "171.17.10.21/24"} 7.修改完成后保存,并重启docker服务;systemctl restart docker.servicedocker命令阻塞卡住问题
记录一次docker命令阻塞卡住问题;
针对docker命令卡住无法使用的问题;可能是因为docker死锁了; 此时使用systemctl stop docker 停掉docker,可能会需要蛮久; 然后再systemctl start docker; 此时,可能有部分容器会未启动,手动启动即可; 如果是因为某个容器导致卡死,那么可以尝试如下方案: 方案1: docker kill --signal=SIGINT [容器名称或容器id] 方案2: docker ps 找到对应容器id; 然后停止docker服务:service docker stop 然后删除容器对应的文件:rm -rf /var/lib/docker/container/{上面找到的id} 最后启动docker服务:service docker start系统磁盘readOlny后,导致docker无法启动
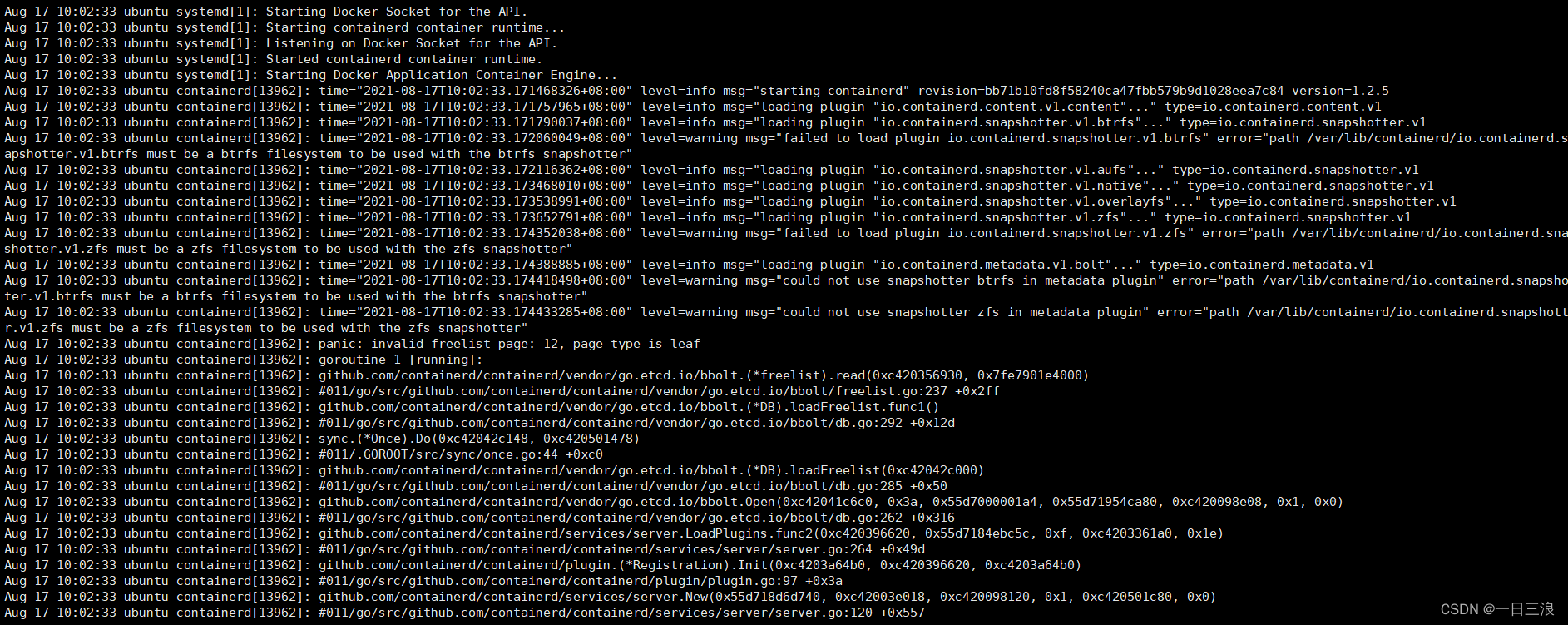
记录一次系统磁盘readOlny后,导致docker无法启动:
docker命令报错: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? systemctl restart docker #重启提示:Job for docker.service canceled. 查看系统日志/var/log/syslog 发现/var/lib/containerd/io.containerd.*相关目录有问题 mv containerd containerd_bak #备份原目录; mkdir containerd #新建目录 systemctl restart docker #重启docker 有部分容器可能起不来,直接docker restart 容器即可系统日志:
一些别人的文章
- docker使用问题总结
- docker服务启动失败















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









